 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study on Dataset Distillation: Performance, Privacy, Robustness and Fairness
May 05, 2023
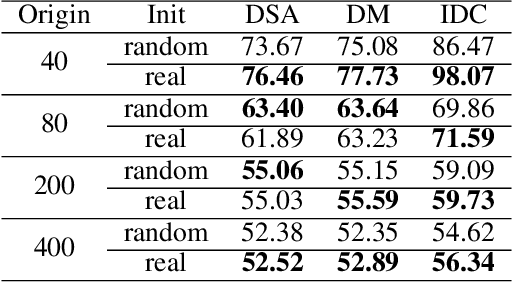
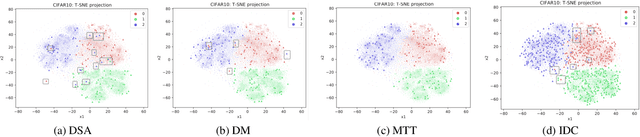
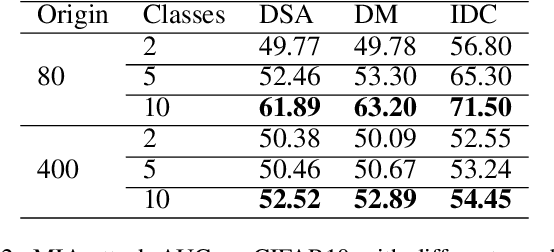
The aim of dataset distillation is to encode the rich features of an original dataset into a tiny dataset. It is a promising approach to accelerate neural network training and related studies. Different approaches have been proposed to improve the informativeness and generalization performance of distilled images. However, no work has comprehensively analyzed this technique from a security perspective and there is a lack of systematic understanding of potential risks. In this work, we conduct extensive experiments to evaluate current state-of-the-art dataset distillation methods. We successfully use membership inference attacks to show that privacy risks still remain. Our work also demonstrates that dataset distillation can cause varying degrees of impact on model robustness and amplify model unfairness across classes when making predictions. This work offers a large-scale benchmarking framework for dataset distillation evaluation.
A Survey on Dataset Distillation: Approaches, Applications and Future Directions
May 03, 2023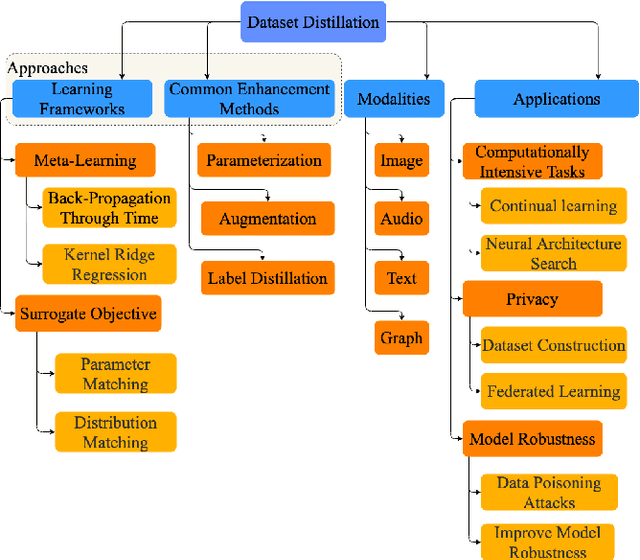
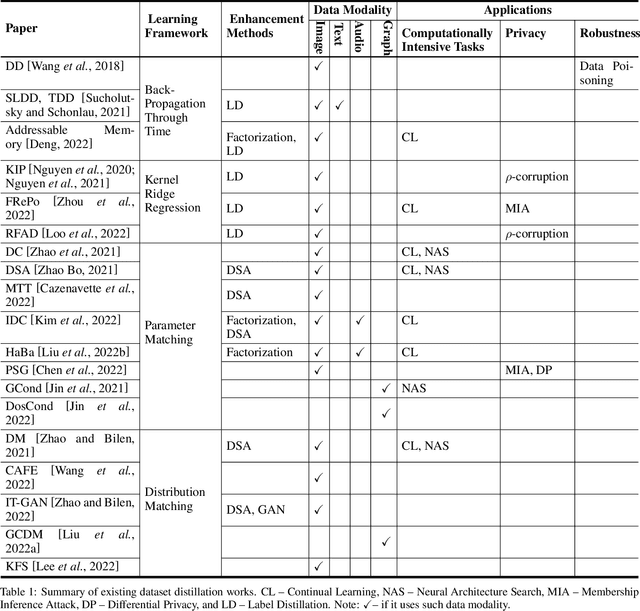
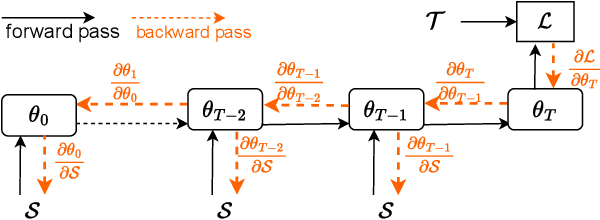

Dataset distillation is attracting more attention in machine learning as training sets continue to grow and the cost of training state-of-the-art models becomes increasingly high. By synthesizing datasets with high information density, dataset distillation offers a range of potential applications, including support for continual learning, neural architecture search, and privacy protection. Despite recent advances, we lack a holistic understanding of the approaches and applications. Our survey aims to bridge this gap by first proposing a taxonomy of dataset distillation, characterizing existing approaches, and then systematically reviewing the data modalities, and related applications. In addition, we summarize the challenges and discuss future directions for this field of research.