 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Hippocampus Memory Learning
Mar 26, 2026Social learning highlights that learning agents improve not in isolation, but through interaction and structured knowledge exchange with others. When introduced into machine learning, this principle gives rise to social machine learning (SML), where multiple agents collaboratively learn by sharing abstracted knowledge. Federated learning (FL) provides a natural collaboration substrate for this paradigm, yet existing heterogeneous FL approaches often rely on sharing model parameters or intermediate representations, which may expose sensitive information and incur additional overhead. In this work, we propose SoHip (Social Hippocampus Memory Learning), a memory-centric social machine learning framework that enables collaboration among heterogeneous agents via memory sharing rather than model sharing. SoHip abstracts each agent's individual short-term memory from local representations, consolidates it into individual long-term memory through a hippocampus-inspired mechanism, and fuses it with collectively aggregated long-term memory to enhance local prediction. Throughout the process, raw data and local models remain on-device, while only lightweight memory are exchanged. We provide theoretical analysis on convergence and privacy preservation properties. Experiments on two benchmark datasets with seven baselines demonstrate that SoHip consistently outperforms existing methods, achieving up to 8.78% accuracy improvements.
FedPDPO: Federated Personalized Direct Preference Optimization for Large Language Model Alignment
Mar 20, 2026Aligning large language models (LLMs) with human preferences in federated learning (FL) is challenging due to decentralized, privacy-sensitive, and highly non-IID preference data. Direct Preference Optimization (DPO) offers an efficient alternative to reinforcement learning with human feedback (RLHF), but its direct application in FL suffers from severe performance degradation under non-IID data and limited generalization of implicit rewards. To bridge this gap, we propose FedPDPO (Federated Personalized Direct Preference Optimization), a personalized federated framework for preference alignment of LLMs. It adopts a parameter-efficient fine-tuning architecture where each client maintains a frozen pretrained LLM backbone augmented with a Low-Rank Adaptation (LoRA) adapter, enabling communication-efficient aggregation. To address non-IID heterogeneity, we devise (1) the globally shared LoRA adapter with the personalized client-specific LLM head. Moreover, we introduce (2) a personalized DPO training strategy with a client-specific explicit reward head to complement implicit rewards and further alleviate non-IID heterogeneity, and (3) a bottleneck adapter to balance global and local features. We provide theoretical analysis establishing the probabilistic foundation and soundness. Extensive experiments on multiple preference datasets demonstrate state-of-the-art performance, achieving up to 4.80% average accuracy improvements in federated intra-domain and cross-domain settings.
Dynamically evolving segment anything model with continuous learning for medical image segmentation
Mar 08, 2025



Medical image segmentation is essential for clinical diagnosis, surgical planning, and treatment monitoring. Traditional approaches typically strive to tackle all medical image segmentation scenarios via one-time learning. However, in practical applications, the diversity of scenarios and tasks in medical image segmentation continues to expand, necessitating models that can dynamically evolve to meet the demands of various segmentation tasks. Here, we introduce EvoSAM, a dynamically evolving medical image segmentation model that continuously accumulates new knowledge from an ever-expanding array of scenarios and tasks, enhancing its segmentation capabilities. Extensive evaluations on surgical image blood vessel segmentation and multi-site prostate MRI segmentation demonstrate that EvoSAM not only improves segmentation accuracy but also mitigates catastrophic forgetting. Further experiments conducted by surgical clinicians on blood vessel segmentation confirm that EvoSAM enhances segmentation efficiency based on user prompts, highlighting its potential as a promising tool for clinical applications.
PriCE: Privacy-Preserving and Cost-Effective Scheduling for Parallelizing the Large Medical Image Processing Workflow over Hybrid Clouds
May 24, 2024


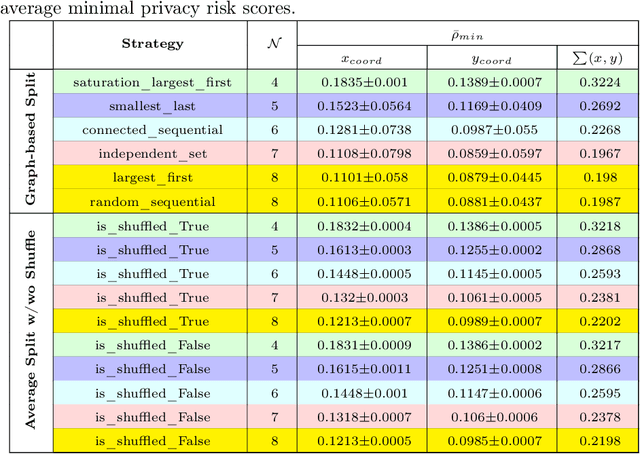
Running deep neural networks for large medical images is a resource-hungry and time-consuming task with centralized computing. Outsourcing such medical image processing tasks to hybrid clouds has benefits, such as a significant reduction of execution time and monetary cost. However, due to privacy concerns, it is still challenging to process sensitive medical images over clouds, which would hinder their deployment in many real-world applications. To overcome this, we first formulate the overall optimization objectives of the privacy-preserving distributed system model, i.e., minimizing the amount of information about the private data learned by the adversaries throughout the process, reducing the maximum execution time and cost under the user budget constraint. We propose a novel privacy-preserving and cost-effective method called PriCE to solve this multi-objective optimization problem. We performed extensive simulation experiments for artifact detection tasks on medical images using an ensemble of five deep convolutional neural network inferences as the workflow task. Experimental results show that PriCE successfully splits a wide range of input gigapixel medical images with graph-coloring-based strategies, yielding desired output utility and lowering the privacy risk, makespan, and monetary cost under user's budget.
Ocean Data Quality Assessment through Outlier Detection-enhanced Active Learning
Dec 17, 2023Ocean and climate research benefits from global ocean observation initiatives such as Argo, GLOSS, and EMSO. The Argo network, dedicated to ocean profiling, generates a vast volume of observatory data. However, data quality issues from sensor malfunctions and transmission errors necessitate stringent quality assessment. Existing methods, including machine learning, fall short due to limited labeled data and imbalanced datasets. To address these challenges, we propose an ODEAL framework for ocean data quality assessment, employing AL to reduce human experts' workload in the quality assessment workflow and leveraging outlier detection algorithms for effective model initialization. We also conduct extensive experiments on five large-scale realistic Argo datasets to gain insights into our proposed method, including the effectiveness of AL query strategies and the initial set construction approach. The results suggest that our framework enhances quality assessment efficiency by up to 465.5% with the uncertainty-based query strategy compared to random sampling and minimizes overall annotation costs by up to 76.9% using the initial set built with outlier detectors.
WWFedCBMIR: World-Wide Federated Content-Based Medical Image Retrieval
May 05, 2023The paper proposes a Federated Content-Based Medical Image Retrieval (FedCBMIR) platform that utilizes Federated Learning (FL) to address the challenges of acquiring a diverse medical data set for training CBMIR models. CBMIR assists pathologists in diagnosing breast cancer more rapidly by identifying similar medical images and relevant patches in prior cases compared to traditional cancer detection methods. However, CBMIR in histopathology necessitates a pool of Whole Slide Images (WSIs) to train to extract an optimal embedding vector that leverages search engine performance, which may not be available in all centers. The strict regulations surrounding data sharing in medical data sets also hinder research and model development, making it difficult to collect a rich data set. The proposed FedCBMIR distributes the model to collaborative centers for training without sharing the data set, resulting in shorter training times than local training. FedCBMIR was evaluated in two experiments with three scenarios on BreaKHis and Camelyon17 (CAM17). The study shows that the FedCBMIR method increases the F1-Score (F1S) of each client to 98%, 96%, 94%, and 97% in the BreaKHis experiment with a generalized model of four magnifications and does so in 6.30 hours less time than total local training. FedCBMIR also achieves 98% accuracy with CAM17 in 2.49 hours less training time than local training, demonstrating that our FedCBMIR is both fast and accurate for both pathologists and engineers. In addition, our FedCBMIR provides similar images with higher magnification for non-developed countries where participate in the worldwide FedCBMIR with developed countries to facilitate mitosis measuring in breast cancer diagnosis. We evaluate this scenario by scattering BreaKHis into four centers with different magnifications.
A Survey on Dataset Distillation: Approaches, Applications and Future Directions
May 03, 2023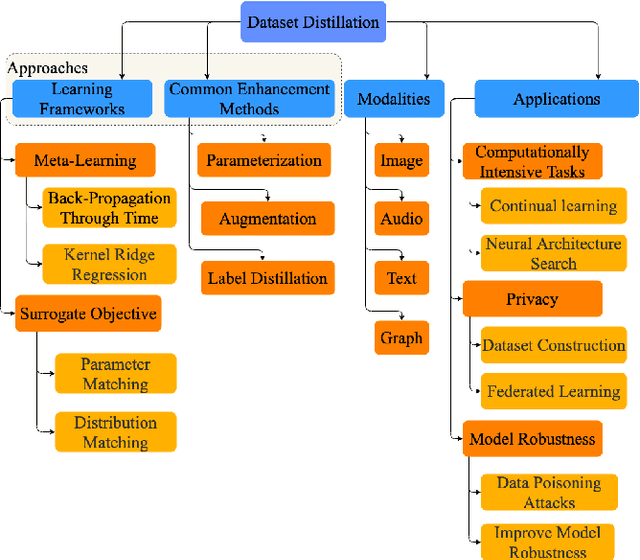
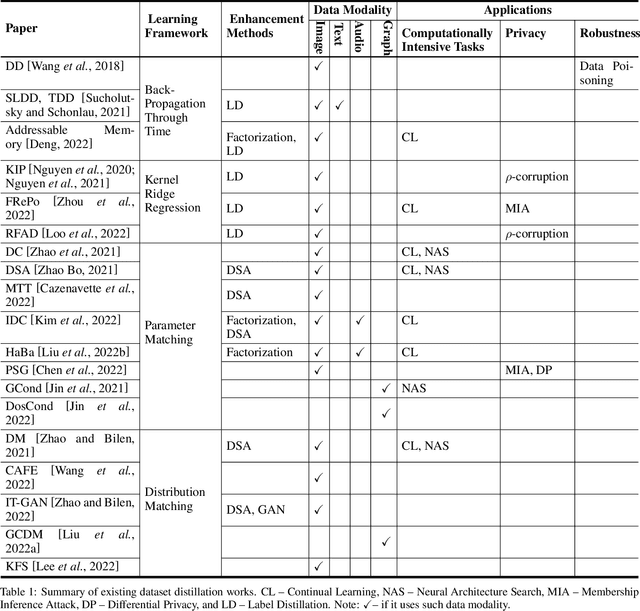
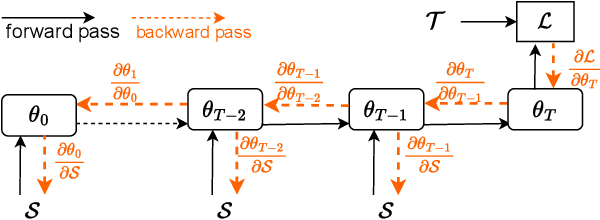

Dataset distillation is attracting more attention in machine learning as training sets continue to grow and the cost of training state-of-the-art models becomes increasingly high. By synthesizing datasets with high information density, dataset distillation offers a range of potential applications, including support for continual learning, neural architecture search, and privacy protection. Despite recent advances, we lack a holistic understanding of the approaches and applications. Our survey aims to bridge this gap by first proposing a taxonomy of dataset distillation, characterizing existing approaches, and then systematically reviewing the data modalities, and related applications. In addition, we summarize the challenges and discuss future directions for this field of research.