 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamically evolving segment anything model with continuous learning for medical image segmentation
Mar 08, 2025



Medical image segmentation is essential for clinical diagnosis, surgical planning, and treatment monitoring. Traditional approaches typically strive to tackle all medical image segmentation scenarios via one-time learning. However, in practical applications, the diversity of scenarios and tasks in medical image segmentation continues to expand, necessitating models that can dynamically evolve to meet the demands of various segmentation tasks. Here, we introduce EvoSAM, a dynamically evolving medical image segmentation model that continuously accumulates new knowledge from an ever-expanding array of scenarios and tasks, enhancing its segmentation capabilities. Extensive evaluations on surgical image blood vessel segmentation and multi-site prostate MRI segmentation demonstrate that EvoSAM not only improves segmentation accuracy but also mitigates catastrophic forgetting. Further experiments conducted by surgical clinicians on blood vessel segmentation confirm that EvoSAM enhances segmentation efficiency based on user prompts, highlighting its potential as a promising tool for clinical applications.
Affective Behaviour Analysis Using Pretrained Model with Facial Priori
Jul 24, 2022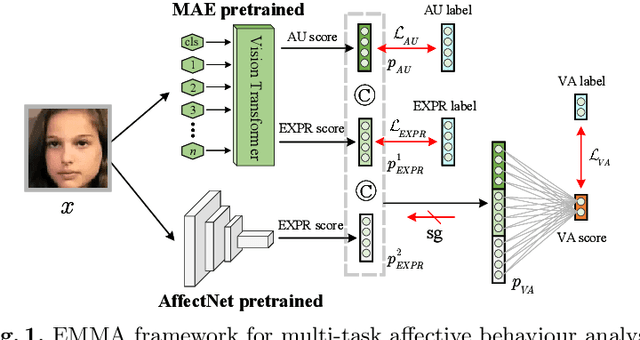
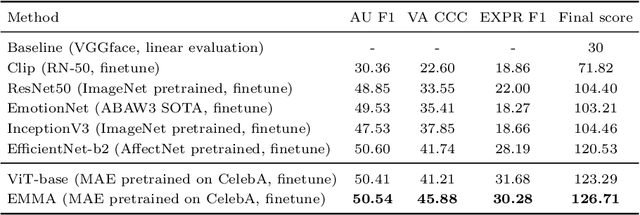
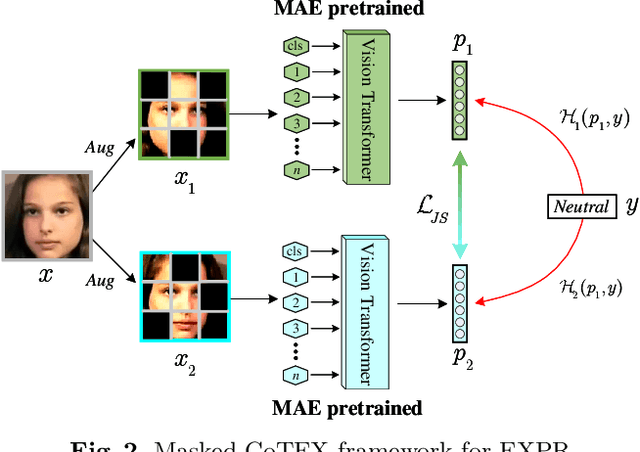

Affective behaviour analysis has aroused researchers' attention due to its broad applications. However, it is labor exhaustive to obtain accurate annotations for massive face images. Thus, we propose to utilize the prior facial information via Masked Auto-Encoder (MAE) pretrained on unlabeled face images. Furthermore, we combine MAE pretrained Vision Transformer (ViT) and AffectNet pretrained CNN to perform multi-task emotion recognition. We notice that expression and action unit (AU) scores are pure and intact features for valence-arousal (VA) regression. As a result, we utilize AffectNet pretrained CNN to extract expression scores concatenating with expression and AU scores from ViT to obtain the final VA features. Moreover, we also propose a co-training framework with two parallel MAE pretrained ViT for expression recognition tasks. In order to make the two views independent, we random mask most patches during the training process. Then, JS divergence is performed to make the predictions of the two views as consistent as possible. The results on ABAW4 show that our methods are effective.