 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXVerse: Consistent Multi-Subject Control of Identity and Semantic Attributes via DiT Modulation
Jun 26, 2025Achieving fine-grained control over subject identity and semantic attributes (pose, style, lighting) in text-to-image generation, particularly for multiple subjects, often undermines the editability and coherence of Diffusion Transformers (DiTs). Many approaches introduce artifacts or suffer from attribute entanglement. To overcome these challenges, we propose a novel multi-subject controlled generation model XVerse. By transforming reference images into offsets for token-specific text-stream modulation, XVerse allows for precise and independent control for specific subject without disrupting image latents or features. Consequently, XVerse offers high-fidelity, editable multi-subject image synthesis with robust control over individual subject characteristics and semantic attributes. This advancement significantly improves personalized and complex scene generation capabilities.
Tarsier2: Advancing Large Vision-Language Models from Detailed Video Description to Comprehensive Video Understanding
Jan 14, 2025We introduce Tarsier2, a state-of-the-art large vision-language model (LVLM) designed for generating detailed and accurate video descriptions, while also exhibiting superior general video understanding capabilities. Tarsier2 achieves significant advancements through three key upgrades: (1) Scaling pre-training data from 11M to 40M video-text pairs, enriching both volume and diversity; (2) Performing fine-grained temporal alignment during supervised fine-tuning; (3) Using model-based sampling to automatically construct preference data and applying DPO training for optimization. Extensive experiments show that Tarsier2-7B consistently outperforms leading proprietary models, including GPT-4o and Gemini 1.5 Pro, in detailed video description tasks. On the DREAM-1K benchmark, Tarsier2-7B improves F1 by 2.8\% over GPT-4o and 5.8\% over Gemini-1.5-Pro. In human side-by-side evaluations, Tarsier2-7B shows a +8.6\% performance advantage over GPT-4o and +24.9\% over Gemini-1.5-Pro. Tarsier2-7B also sets new state-of-the-art results across 15 public benchmarks, spanning tasks such as video question-answering, video grounding, hallucination test, and embodied question-answering, demonstrating its versatility as a robust generalist vision-language model.
Face-MLLM: A Large Face Perception Model
Oct 28, 2024



Although multimodal large language models (MLLMs) have achieved promising results on a wide range of vision-language tasks, their ability to perceive and understand human faces is rarely explored. In this work, we comprehensively evaluate existing MLLMs on face perception tasks. The quantitative results reveal that existing MLLMs struggle to handle these tasks. The primary reason is the lack of image-text datasets that contain fine-grained descriptions of human faces. To tackle this problem, we design a practical pipeline for constructing datasets, upon which we further build a novel multimodal large face perception model, namely Face-MLLM. Specifically, we re-annotate LAION-Face dataset with more detailed face captions and facial attribute labels. Besides, we re-formulate traditional face datasets using the question-answer style, which is fit for MLLMs. Together with these enriched datasets, we develop a novel three-stage MLLM training method. In the first two stages, our model learns visual-text alignment and basic visual question answering capability, respectively. In the third stage, our model learns to handle multiple specialized face perception tasks. Experimental results show that our model surpasses previous MLLMs on five famous face perception tasks. Besides, on our newly introduced zero-shot facial attribute analysis task, our Face-MLLM also presents superior performance.
Task-adaptive Q-Face
May 15, 2024



Although face analysis has achieved remarkable improvements in the past few years, designing a multi-task face analysis model is still challenging. Most face analysis tasks are studied as separate problems and do not benefit from the synergy among related tasks. In this work, we propose a novel task-adaptive multi-task face analysis method named as Q-Face, which simultaneously performs multiple face analysis tasks with a unified model. We fuse the features from multiple layers of a large-scale pre-trained model so that the whole model can use both local and global facial information to support multiple tasks. Furthermore, we design a task-adaptive module that performs cross-attention between a set of query vectors and the fused multi-stage features and finally adaptively extracts desired features for each face analysis task. Extensive experiments show that our method can perform multiple tasks simultaneously and achieves state-of-the-art performance on face expression recognition, action unit detection, face attribute analysis, age estimation, and face pose estimation. Compared to conventional methods, our method opens up new possibilities for multi-task face analysis and shows the potential for both accuracy and efficiency.
Affective Behaviour Analysis Using Pretrained Model with Facial Priori
Jul 24, 2022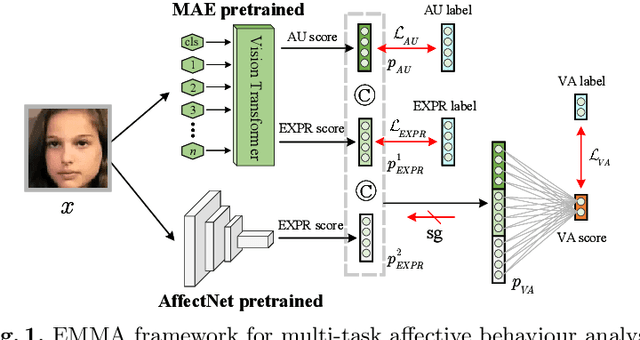
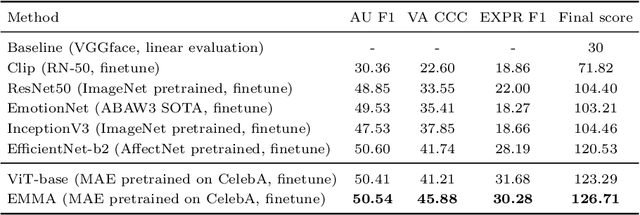
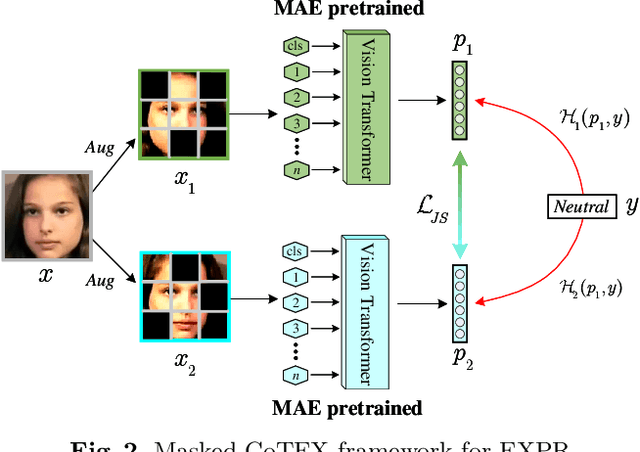

Affective behaviour analysis has aroused researchers' attention due to its broad applications. However, it is labor exhaustive to obtain accurate annotations for massive face images. Thus, we propose to utilize the prior facial information via Masked Auto-Encoder (MAE) pretrained on unlabeled face images. Furthermore, we combine MAE pretrained Vision Transformer (ViT) and AffectNet pretrained CNN to perform multi-task emotion recognition. We notice that expression and action unit (AU) scores are pure and intact features for valence-arousal (VA) regression. As a result, we utilize AffectNet pretrained CNN to extract expression scores concatenating with expression and AU scores from ViT to obtain the final VA features. Moreover, we also propose a co-training framework with two parallel MAE pretrained ViT for expression recognition tasks. In order to make the two views independent, we random mask most patches during the training process. Then, JS divergence is performed to make the predictions of the two views as consistent as possible. The results on ABAW4 show that our methods are effective.