 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace-MLLM: A Large Face Perception Model
Oct 28, 2024



Although multimodal large language models (MLLMs) have achieved promising results on a wide range of vision-language tasks, their ability to perceive and understand human faces is rarely explored. In this work, we comprehensively evaluate existing MLLMs on face perception tasks. The quantitative results reveal that existing MLLMs struggle to handle these tasks. The primary reason is the lack of image-text datasets that contain fine-grained descriptions of human faces. To tackle this problem, we design a practical pipeline for constructing datasets, upon which we further build a novel multimodal large face perception model, namely Face-MLLM. Specifically, we re-annotate LAION-Face dataset with more detailed face captions and facial attribute labels. Besides, we re-formulate traditional face datasets using the question-answer style, which is fit for MLLMs. Together with these enriched datasets, we develop a novel three-stage MLLM training method. In the first two stages, our model learns visual-text alignment and basic visual question answering capability, respectively. In the third stage, our model learns to handle multiple specialized face perception tasks. Experimental results show that our model surpasses previous MLLMs on five famous face perception tasks. Besides, on our newly introduced zero-shot facial attribute analysis task, our Face-MLLM also presents superior performance.
Mix Q-learning for Lane Changing: A Collaborative Decision-Making Method in Multi-Agent Deep Reinforcement Learning
Jun 14, 2024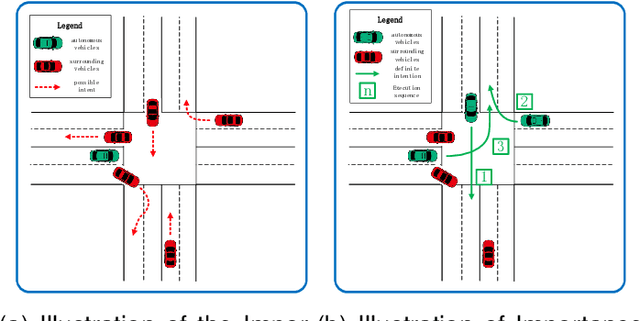

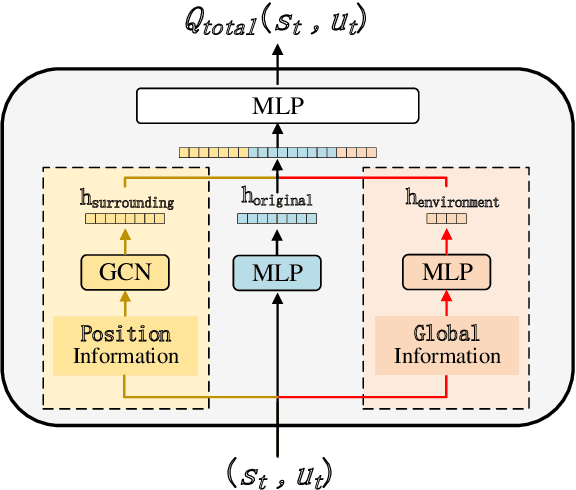

Lane-changing decisions, which are crucial for autonomous vehicle path planning, face practical challenges due to rule-based constraints and limited data. Deep reinforcement learning has become a major research focus due to its advantages in data acquisition and interpretability. However, current models often overlook collaboration, which affects not only impacts overall traffic efficiency but also hinders the vehicle's own normal driving in the long run. To address the aforementioned issue, this paper proposes a method named Mix Q-learning for Lane Changing(MQLC) that integrates a hybrid value Q network, taking into account both collective and individual benefits for the greater good. At the collective level, our method coordinates the individual Q and global Q networks by utilizing global information. This enables agents to effectively balance their individual interests with the collective benefit. At the individual level, we integrated a deep learning-based intent recognition module into our observation and enhanced the decision network. These changes provide agents with richer decision information and more accurate feature extraction for improved lane-changing decisions. This strategy enables the multi-agent system to learn and formulate optimal decision-making strategies effectively. Our MQLC model, through extensive experimental results, impressively outperforms other state-of-the-art multi-agent decision-making methods, achieving significantly safer and faster lane-changing decisions.
Task-adaptive Q-Face
May 15, 2024



Although face analysis has achieved remarkable improvements in the past few years, designing a multi-task face analysis model is still challenging. Most face analysis tasks are studied as separate problems and do not benefit from the synergy among related tasks. In this work, we propose a novel task-adaptive multi-task face analysis method named as Q-Face, which simultaneously performs multiple face analysis tasks with a unified model. We fuse the features from multiple layers of a large-scale pre-trained model so that the whole model can use both local and global facial information to support multiple tasks. Furthermore, we design a task-adaptive module that performs cross-attention between a set of query vectors and the fused multi-stage features and finally adaptively extracts desired features for each face analysis task. Extensive experiments show that our method can perform multiple tasks simultaneously and achieves state-of-the-art performance on face expression recognition, action unit detection, face attribute analysis, age estimation, and face pose estimation. Compared to conventional methods, our method opens up new possibilities for multi-task face analysis and shows the potential for both accuracy and efficiency.
Locality-aware Channel-wise Dropout for Occluded Face Recognition
Jul 20, 2021
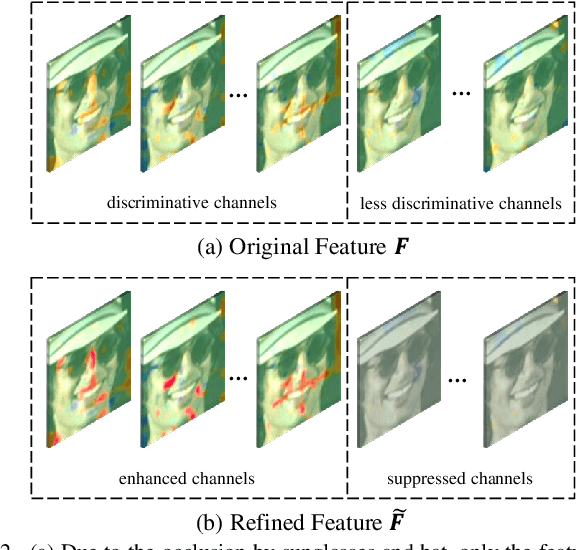
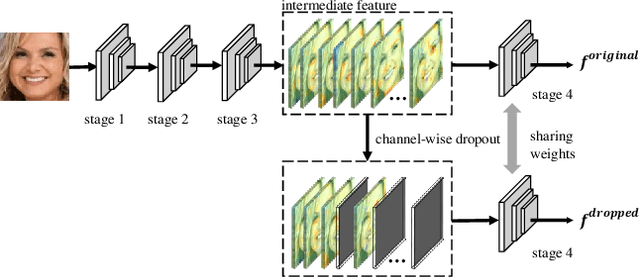
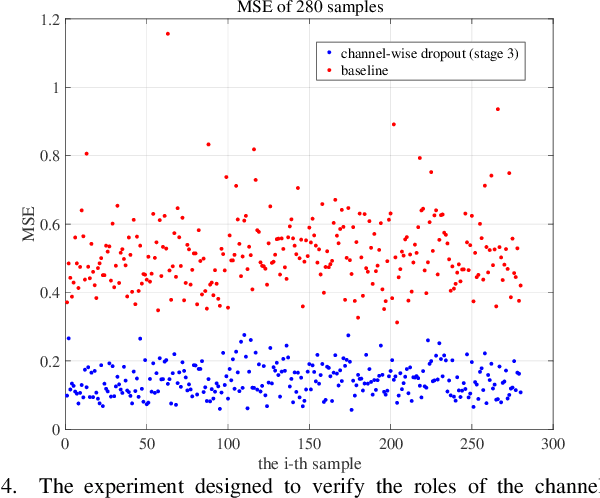
Face recognition remains a challenging task in unconstrained scenarios, especially when faces are partially occluded. To improve the robustness against occlusion, augmenting the training images with artificial occlusions has been proved as a useful approach. However, these artificial occlusions are commonly generated by adding a black rectangle or several object templates including sunglasses, scarfs and phones, which cannot well simulate the realistic occlusions. In this paper, based on the argument that the occlusion essentially damages a group of neurons, we propose a novel and elegant occlusion-simulation method via dropping the activations of a group of neurons in some elaborately selected channel. Specifically, we first employ a spatial regularization to encourage each feature channel to respond to local and different face regions. In this way, the activations affected by an occlusion in a local region are more likely to be located in a single feature channel. Then, the locality-aware channel-wise dropout (LCD) is designed to simulate the occlusion by dropping out the entire feature channel. Furthermore, by randomly dropping out several feature channels, our method can well simulate the occlusion of larger area. The proposed LCD can encourage its succeeding layers to minimize the intra-class feature variance caused by occlusions, thus leading to improved robustness against occlusion. In addition, we design an auxiliary spatial attention module by learning a channel-wise attention vector to reweight the feature channels, which improves the contributions of non-occluded regions. Extensive experiments on various benchmarks show that the proposed method outperforms state-of-the-art methods with a remarkable improvement.
MFR 2021: Masked Face Recognition Competition
Jun 29, 2021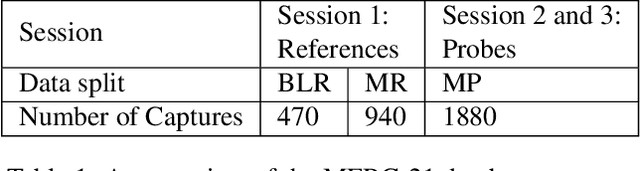

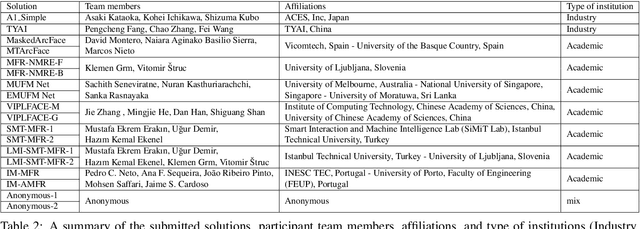
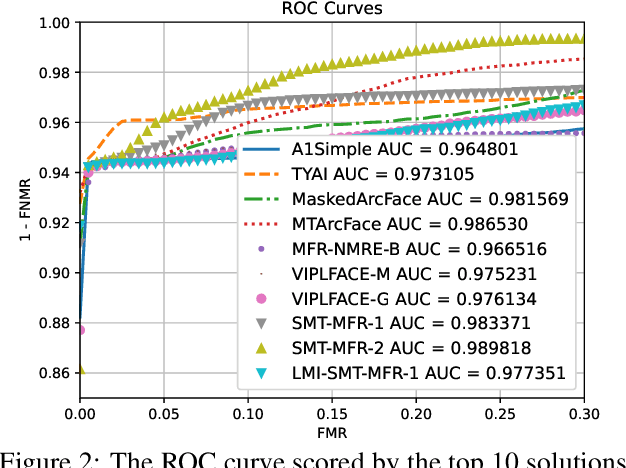
This paper presents a summary of the Masked Face Recognition Competitions (MFR) held within the 2021 International Joint Conference on Biometrics (IJCB 2021). The competition attracted a total of 10 participating teams with valid submissions. The affiliations of these teams are diverse and associated with academia and industry in nine different countries. These teams successfully submitted 18 valid solutions. The competition is designed to motivate solutions aiming at enhancing the face recognition accuracy of masked faces. Moreover, the competition considered the deployability of the proposed solutions by taking the compactness of the face recognition models into account. A private dataset representing a collaborative, multi-session, real masked, capture scenario is used to evaluate the submitted solutions. In comparison to one of the top-performing academic face recognition solutions, 10 out of the 18 submitted solutions did score higher masked face verification accuracy.