 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization of Fitness Exercise Recognition from Doppler Measurements by Domain-adaption and Few-Shot Learning
Nov 20, 2023In previous works, a mobile application was developed using an unmodified commercial off-the-shelf smartphone to recognize whole-body exercises. The working principle was based on the ultrasound Doppler sensing with the device built-in hardware. Applying such a lab-environment trained model on realistic application variations causes a significant drop in performance, and thus decimate its applicability. The reason of the reduced performance can be manifold. It could be induced by the user, environment, and device variations in realistic scenarios. Such scenarios are often more complex and diverse, which can be challenging to anticipate in the initial training data. To study and overcome this issue, this paper presents a database with controlled and uncontrolled subsets of fitness exercises. We propose two concepts to utilize small adaption data to successfully improve model generalization in an uncontrolled environment, increasing the recognition accuracy by two to six folds compared to the baseline for different users.
Stating Comparison Score Uncertainty and Verification Decision Confidence Towards Transparent Face Recognition
Oct 19, 2022
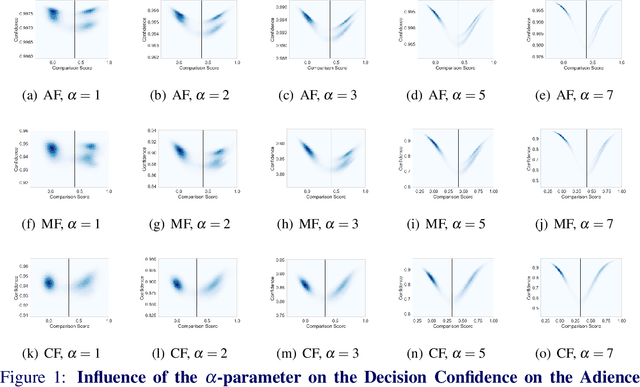
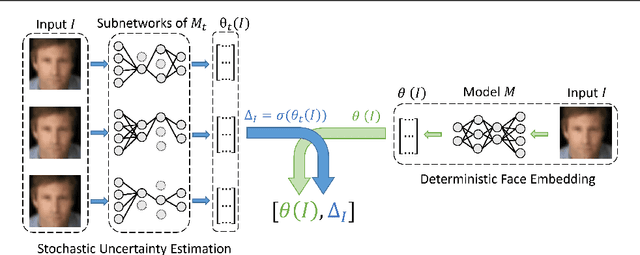

Face Recognition (FR) is increasingly used in critical verification decisions and thus, there is a need for assessing the trustworthiness of such decisions. The confidence of a decision is often based on the overall performance of the model or on the image quality. We propose to propagate model uncertainties to scores and decisions in an effort to increase the transparency of verification decisions. This work presents two contributions. First, we propose an approach to estimate the uncertainty of face comparison scores. Second, we introduce a confidence measure of the system's decision to provide insights into the verification decision. The suitability of the comparison scores uncertainties and the verification decision confidences have been experimentally proven on three face recognition models on two datasets.
On the (Limited) Generalization of MasterFace Attacks and Its Relation to the Capacity of Face Representations
Apr 01, 2022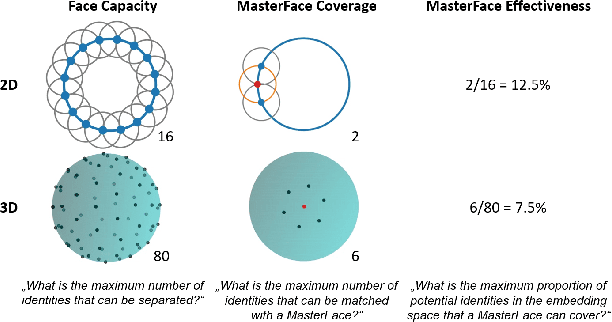

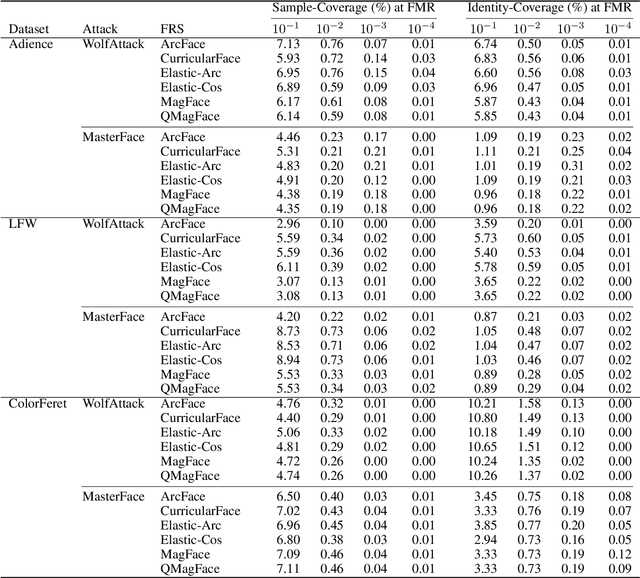
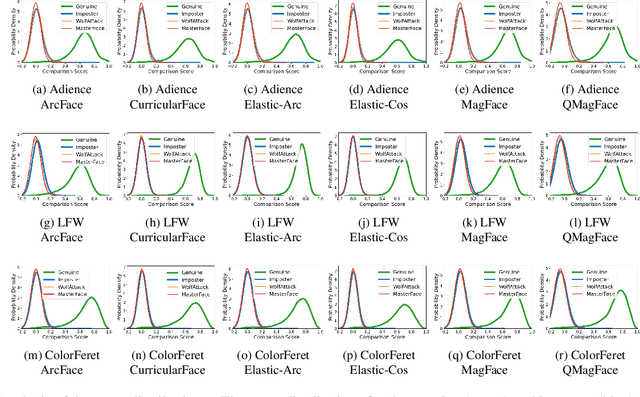
A MasterFace is a face image that can successfully match against a large portion of the population. Since their generation does not require access to the information of the enrolled subjects, MasterFace attacks represent a potential security risk for widely-used face recognition systems. Previous works proposed methods for generating such images and demonstrated that these attacks can strongly compromise face recognition. However, previous works followed evaluation settings consisting of older recognition models, limited cross-dataset and cross-model evaluations, and the use of low-scale testing data. This makes it hard to state the generalizability of these attacks. In this work, we comprehensively analyse the generalizability of MasterFace attacks in empirical and theoretical investigations. The empirical investigations include the use of six state-of-the-art FR models, cross-dataset and cross-model evaluation protocols, and utilizing testing datasets of significantly higher size and variance. The results indicate a low generalizability when MasterFaces are training on a different face recognition model than the one used for testing. In these cases, the attack performance is similar to zero-effort imposter attacks. In the theoretical investigations, we define and estimate the face capacity and the maximum MasterFace coverage under the assumption that identities in the face space are well separated. The current trend of increasing the fairness and generalizability in face recognition indicates that the vulnerability of future systems might further decrease. Future works might analyse the utility of MasterFaces for understanding and enhancing the robustness of face recognition models.
Mask-invariant Face Recognition through Template-level Knowledge Distillation
Dec 10, 2021

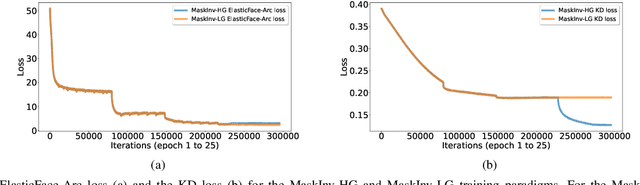
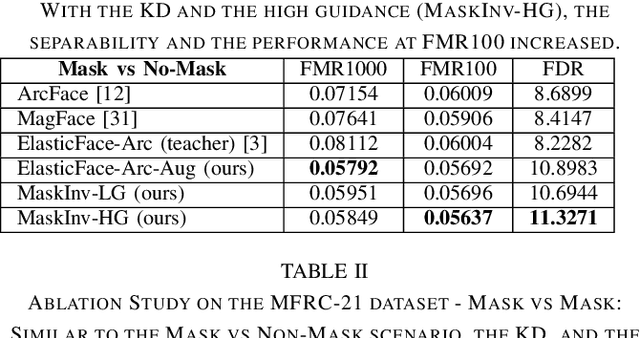
The emergence of the global COVID-19 pandemic poses new challenges for biometrics. Not only are contactless biometric identification options becoming more important, but face recognition has also recently been confronted with the frequent wearing of masks. These masks affect the performance of previous face recognition systems, as they hide important identity information. In this paper, we propose a mask-invariant face recognition solution (MaskInv) that utilizes template-level knowledge distillation within a training paradigm that aims at producing embeddings of masked faces that are similar to those of non-masked faces of the same identities. In addition to the distilled knowledge, the student network benefits from additional guidance by margin-based identity classification loss, ElasticFace, using masked and non-masked faces. In a step-wise ablation study on two real masked face databases and five mainstream databases with synthetic masks, we prove the rationalization of our MaskInv approach. Our proposed solution outperforms previous state-of-the-art (SOTA) academic solutions in the recent MFRC-21 challenge in both scenarios, masked vs masked and masked vs non-masked, and also outperforms the previous solution on the MFR2 dataset. Furthermore, we demonstrate that the proposed model can still perform well on unmasked faces with only a minor loss in verification performance. The code, the trained models, as well as the evaluation protocol on the synthetically masked data are publicly available: https://github.com/fdbtrs/Masked-Face-Recognition-KD.
QMagFace: Simple and Accurate Quality-Aware Face Recognition
Nov 30, 2021
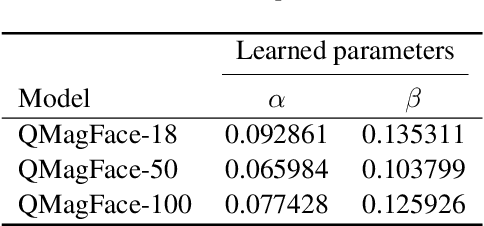

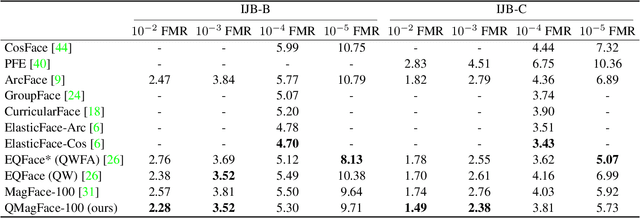
Face recognition systems have to deal with large variabilities (such as different poses, illuminations, and expressions) that might lead to incorrect matching decisions. These variabilities can be measured in terms of face image quality which is defined over the utility of a sample for recognition. Previous works on face recognition either do not employ this valuable information or make use of non-inherently fit quality estimates. In this work, we propose a simple and effective face recognition solution (QMag-Face) that combines a quality-aware comparison score with a recognition model based on a magnitude-aware angular margin loss. The proposed approach includes model-specific face image qualities in the comparison process to enhance the recognition performance under unconstrained circumstances. Exploiting the linearity between the qualities and their comparison scores induced by the utilized loss, our quality-aware comparison function is simple and highly generalizable. The experiments conducted on several face recognition databases and benchmarks demonstrate that the introduced quality-awareness leads to consistent improvements in the recognition performance. Moreover, the proposed QMagFace approach performs especially well under challenging circumstances, such as cross-pose, cross-age, or cross-quality. Consequently, it leads to state-of-the-art performances on several face recognition benchmarks, such as 98.50% on AgeDB, 83.95% on XQLFQ, and 98.74% on CFP-FP. The code for QMagFace is publicly available
Pixel-Level Face Image Quality Assessment for Explainable Face Recognition
Nov 05, 2021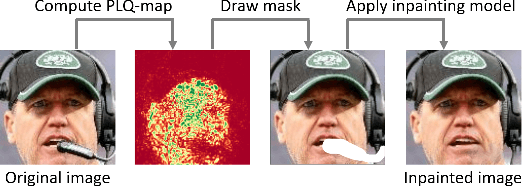
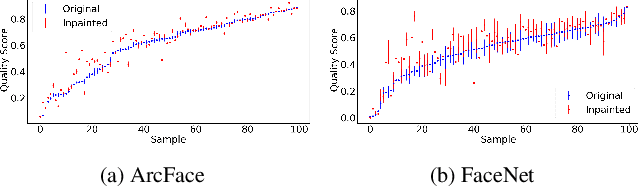

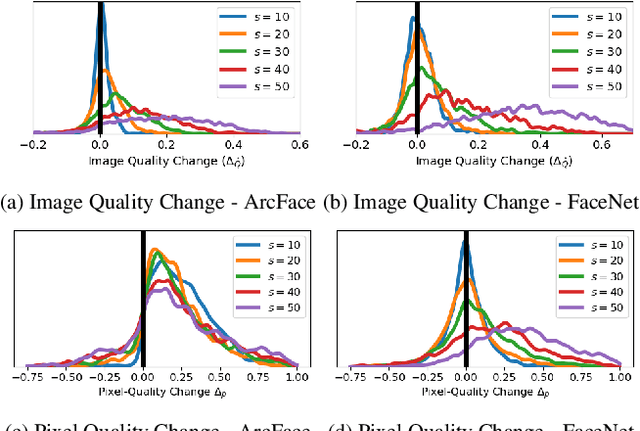
An essential factor to achieve high performance in face recognition systems is the quality of its samples. Since these systems are involved in various daily life there is a strong need of making face recognition processes understandable for humans. In this work, we introduce the concept of pixel-level face image quality that determines the utility of pixels in a face image for recognition. Given an arbitrary face recognition network, in this work, we propose a training-free approach to assess the pixel-level qualities of a face image. To achieve this, a model-specific quality value of the input image is estimated and used to build a sample-specific quality regression model. Based on this model, quality-based gradients are back-propagated and converted into pixel-level quality estimates. In the experiments, we qualitatively and quantitatively investigated the meaningfulness of the pixel-level qualities based on real and artificial disturbances and by comparing the explanation maps on ICAO-incompliant faces. In all scenarios, the results demonstrate that the proposed solution produces meaningful pixel-level qualities. The code is publicly available.
The Effect of Wearing a Face Mask on Face Image Quality
Nov 02, 2021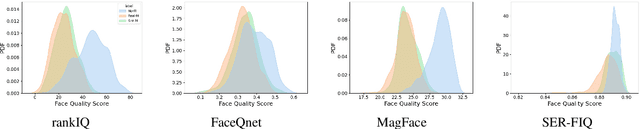

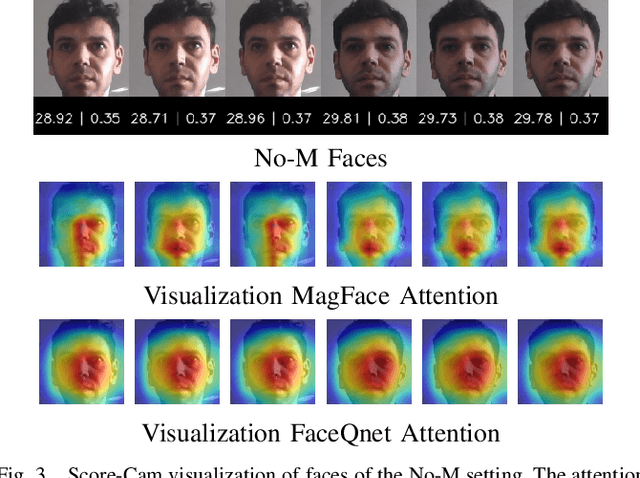

Due to the COVID-19 situation, face masks have become a main part of our daily life. Wearing mouth-and-nose protection has been made a mandate in many public places, to prevent the spread of the COVID-19 virus. However, face masks affect the performance of face recognition, since a large area of the face is covered. The effect of wearing a face mask on the different components of the face recognition system in a collaborative environment is a problem that is still to be fully studied. This work studies, for the first time, the effect of wearing a face mask on face image quality by utilising state-of-the-art face image quality assessment methods of different natures. This aims at providing better understanding on the effect of face masks on the operation of face recognition as a whole system. In addition, we further studied the effect of simulated masks on face image utility in comparison to real face masks. We discuss the correlation between the mask effect on face image quality and that on the face verification performance by automatic systems and human experts, indicating a consistent trend between both factors. The evaluation is conducted on the database containing (1) no-masked faces, (2) real face masks, and (3) simulated face masks, by synthetically generating digital facial masks on no-masked faces. Finally, a visual interpretation of the face areas contributing to the quality score of a selected set of quality assessment methods is provided to give a deeper insight into the difference of network decisions in masked and non-masked faces, among other variations.
ElasticFace: Elastic Margin Loss for Deep Face Recognition
Sep 22, 2021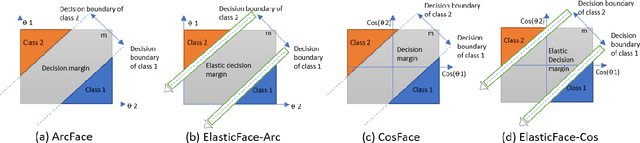
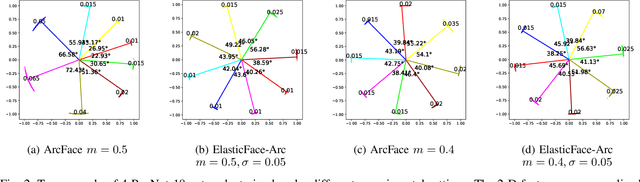


Learning discriminative face features plays a major role in building high-performing face recognition models. The recent state-of-the-art face recognition solutions proposed to incorporate a fixed penalty margin on commonly used classification loss function, softmax loss, in the normalized hypersphere to increase the discriminative power of face recognition models, by minimizing the intra-class variation and maximizing the inter-class variation. Marginal softmax losses, such as ArcFace and CosFace, assume that the geodesic distance between and within the different identities can be equally learned using a fixed margin. However, such a learning objective is not realistic for real data with inconsistent inter-and intra-class variation, which might limit the discriminative and generalizability of the face recognition model. In this paper, we relax the fixed margin constrain by proposing elastic margin loss (ElasticFace) that allows flexibility in the push for class separability. The main idea is to utilize random margin values drawn from a normal distribution in each training iteration. This aims at giving the margin chances to extract and retract to allow space for flexible class separability learning. We demonstrate the superiority of our elastic margin loss over ArcFace and CosFace losses, using the same geometric transformation, on a large set of mainstream benchmarks. From a wider perspective, our ElasticFace has advanced the state-of-the-art face recognition performance on six out of nine mainstream benchmarks.
Learnable Multi-level Frequency Decomposition and Hierarchical Attention Mechanism for Generalized Face Presentation Attack Detection
Sep 16, 2021
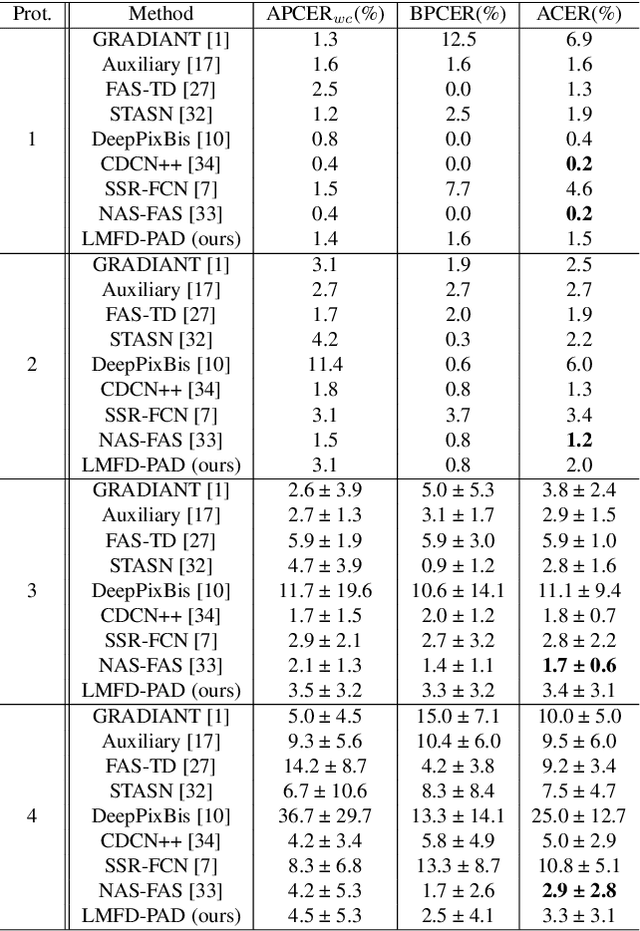
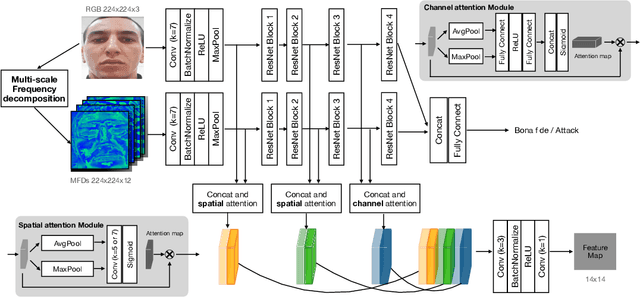
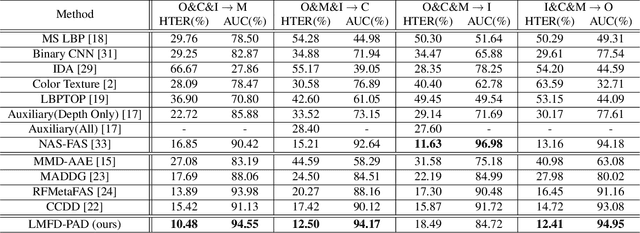
With the increased deployment of face recognition systems in our daily lives, face presentation attack detection (PAD) is attracting a lot of attention and playing a key role in securing face recognition systems. Despite the great performance achieved by the hand-crafted and deep learning based methods in intra-dataset evaluations, the performance drops when dealing with unseen scenarios. In this work, we propose a dual-stream convolution neural networks (CNNs) framework. One stream adapts four learnable frequency filters to learn features in the frequency domain, which are less influenced variations in sensors/illuminations. The other stream leverage the RGB images to complement the features of the frequency domain. Moreover, we propose a hierarchical attention module integration to join the information from the two streams at different stages by considering the nature of deep features in different layers of the CNN. The proposed method is evaluated in the intra-dataset and cross-dataset setups and the results demonstrates that our proposed approach enhances the generalizability in most experimental setups in comparison to state-of-the-art, including the methods designed explicitly for domain adaption/shift problem. We successfully prove the design of our proposed PAD solution in a step-wise ablation study that involves our proposed learnable frequency decomposition, our hierarchical attention module design, and the used loss function. Training codes and pre-trained models are publicly released.
PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and Multi-Step Knowledge Distillation
Aug 24, 2021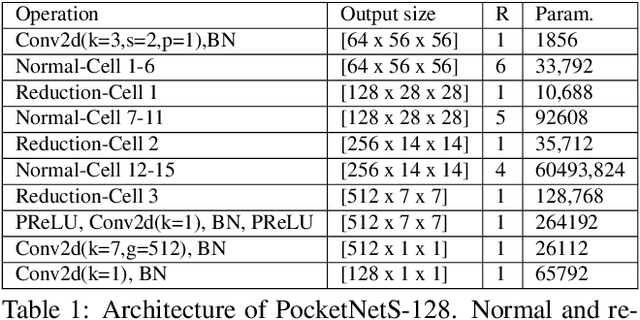
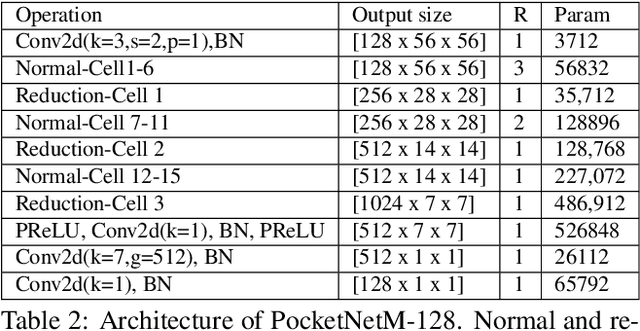
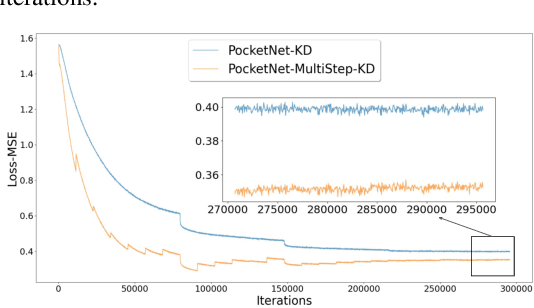
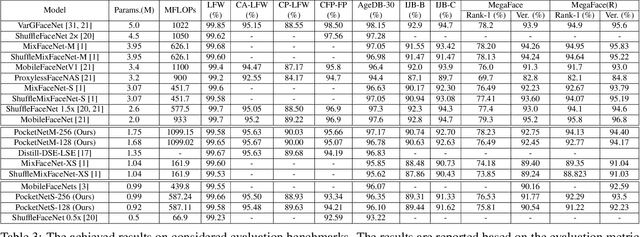
Deep neural networks have rapidly become the mainstream method for face recognition. However, deploying such models that contain an extremely large number of parameters to embedded devices or in application scenarios with limited memory footprint is challenging. In this work, we present an extremely lightweight and accurate face recognition solution. We utilize neural architecture search to develop a new family of face recognition models, namely PocketNet. We also propose to enhance the verification performance of the compact model by presenting a novel training paradigm based on knowledge distillation, namely the multi-step knowledge distillation. We present an extensive experimental evaluation and comparisons with the recent compact face recognition models on nine different benchmarks including large-scale evaluation benchmarks such as IJB-B, IJB-C, and MegaFace. PocketNets have consistently advanced the state-of-the-art (SOTA) face recognition performance on nine mainstream benchmarks when considering the same level of model compactness. With 0.92M parameters, our smallest network PocketNetS-128 achieved very competitive results to recent SOTA compacted models that contain more than 4M parameters. Training codes and pre-trained models are publicly released https://github.com/fdbtrs/PocketNet.