 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Drowsiness Detection -- Modern Applications and Methods
Aug 23, 2024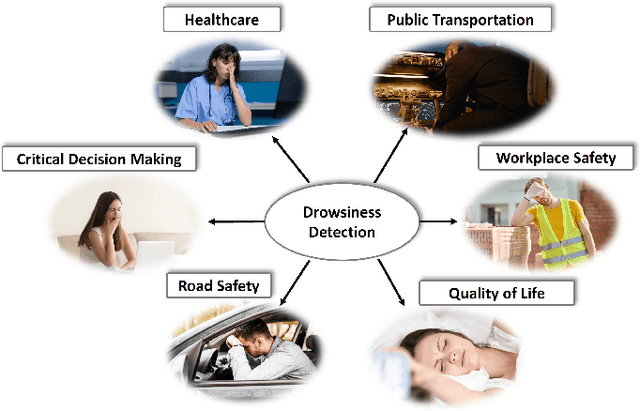
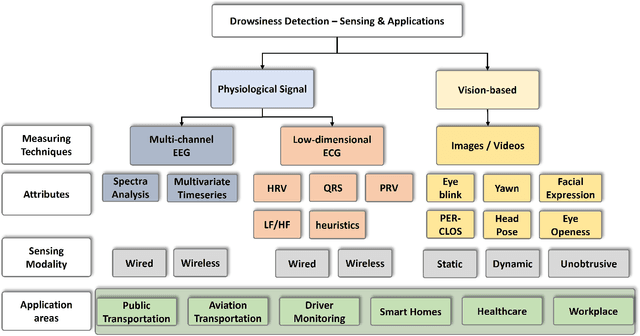
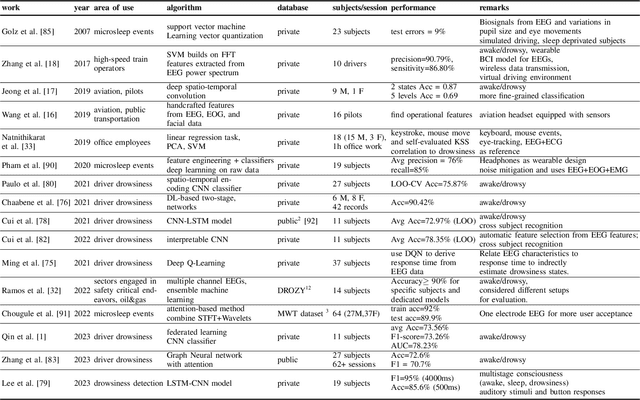
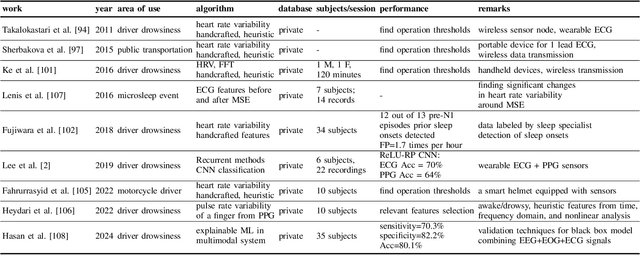
Drowsiness detection holds paramount importance in ensuring safety in workplaces or behind the wheel, enhancing productivity, and healthcare across diverse domains. Therefore accurate and real-time drowsiness detection plays a critical role in preventing accidents, enhancing safety, and ultimately saving lives across various sectors and scenarios. This comprehensive review explores the significance of drowsiness detection in various areas of application, transcending the conventional focus solely on driver drowsiness detection. We delve into the current methodologies, challenges, and technological advancements in drowsiness detection schemes, considering diverse contexts such as public transportation, healthcare, workplace safety, and beyond. By examining the multifaceted implications of drowsiness, this work contributes to a holistic understanding of its impact and the crucial role of accurate and real-time detection techniques in enhancing safety and performance. We identified weaknesses in current algorithms and limitations in existing research such as accurate and real-time detection, stable data transmission, and building bias-free systems. Our survey frames existing works and leads to practical recommendations like mitigating the bias issue by using synthetic data, overcoming the hardware limitations with model compression, and leveraging fusion to boost model performance. This is a pioneering work to survey the topic of drowsiness detection in such an entirely and not only focusing on one single aspect. We consider the topic of drowsiness detection as a dynamic and evolving field, presenting numerous opportunities for further exploration.
Generalization of Fitness Exercise Recognition from Doppler Measurements by Domain-adaption and Few-Shot Learning
Nov 20, 2023In previous works, a mobile application was developed using an unmodified commercial off-the-shelf smartphone to recognize whole-body exercises. The working principle was based on the ultrasound Doppler sensing with the device built-in hardware. Applying such a lab-environment trained model on realistic application variations causes a significant drop in performance, and thus decimate its applicability. The reason of the reduced performance can be manifold. It could be induced by the user, environment, and device variations in realistic scenarios. Such scenarios are often more complex and diverse, which can be challenging to anticipate in the initial training data. To study and overcome this issue, this paper presents a database with controlled and uncontrolled subsets of fitness exercises. We propose two concepts to utilize small adaption data to successfully improve model generalization in an uncontrolled environment, increasing the recognition accuracy by two to six folds compared to the baseline for different users.
Towards Explaining Demographic Bias through the Eyes of Face Recognition Models
Aug 29, 2022

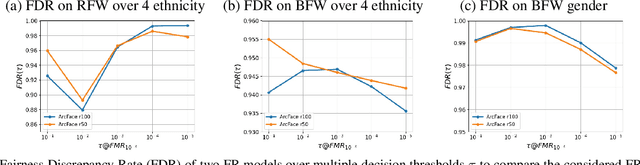

Biases inherent in both data and algorithms make the fairness of widespread machine learning (ML)-based decision-making systems less than optimal. To improve the trustfulness of such ML decision systems, it is crucial to be aware of the inherent biases in these solutions and to make them more transparent to the public and developers. In this work, we aim at providing a set of explainability tool that analyse the difference in the face recognition models' behaviors when processing different demographic groups. We do that by leveraging higher-order statistical information based on activation maps to build explainability tools that link the FR models' behavior differences to certain facial regions. The experimental results on two datasets and two face recognition models pointed out certain areas of the face where the FR models react differently for certain demographic groups compared to reference groups. The outcome of these analyses interestingly aligns well with the results of studies that analyzed the anthropometric differences and the human judgment differences on the faces of different demographic groups. This is thus the first study that specifically tries to explain the biased behavior of FR models on different demographic groups and link it directly to the spatial facial features. The code is publicly available here.
Face Morphing Attacks and Face Image Quality: The Effect of Morphing and the Unsupervised Attack Detection by Quality
Aug 12, 2022

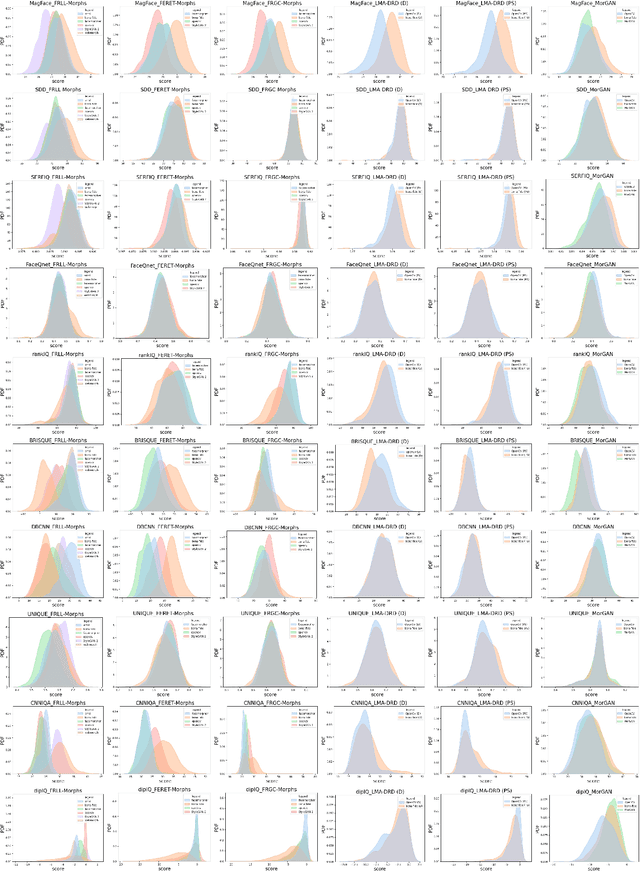
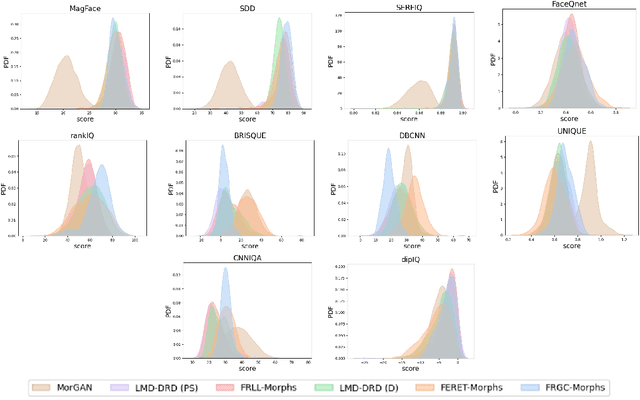
Morphing attacks are a form of presentation attacks that gathered increasing attention in recent years. A morphed image can be successfully verified to multiple identities. This operation, therefore, poses serious security issues related to the ability of a travel or identity document to be verified to belong to multiple persons. Previous works touched on the issue of the quality of morphing attack images, however, with the main goal of quantitatively proofing the realistic appearance of the produced morphing attacks. We theorize that the morphing processes might have an effect on both, the perceptual image quality and the image utility in face recognition (FR) when compared to bona fide samples. Towards investigating this theory, this work provides an extensive analysis of the effect of morphing on face image quality, including both general image quality measures and face image utility measures. This analysis is not limited to a single morphing technique, but rather looks at six different morphing techniques and five different data sources using ten different quality measures. This analysis reveals consistent separability between the quality scores of morphing attack and bona fide samples measured by certain quality measures. Our study goes further to build on this effect and investigate the possibility of performing unsupervised morphing attack detection (MAD) based on quality scores. Our study looks intointra and inter-dataset detectability to evaluate the generalizability of such a detection concept on different morphing techniques and bona fide sources. Our final results point out that a set of quality measures, such as MagFace and CNNNIQA, can be used to perform unsupervised and generalized MAD with a correct classification accuracy of over 70%.
CR-FIQA: Face Image Quality Assessment by Learning Sample Relative Classifiability
Dec 13, 2021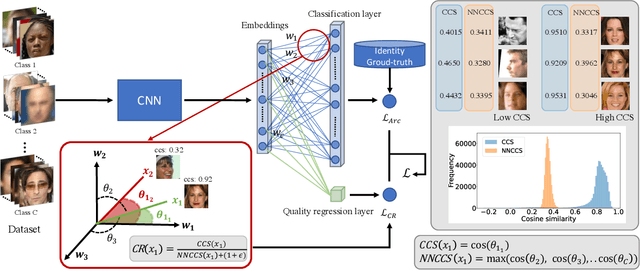
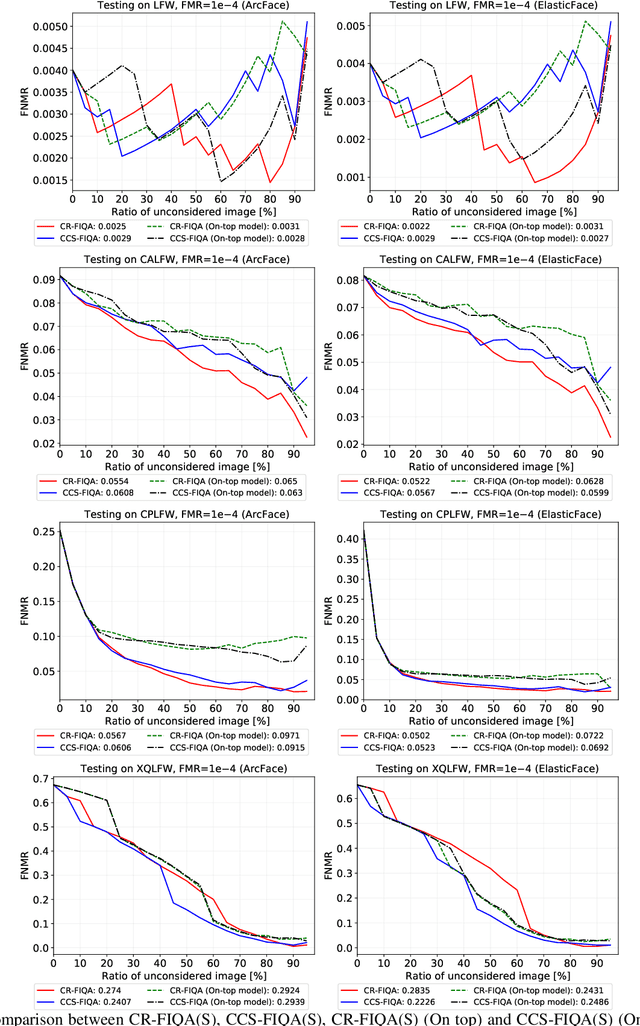
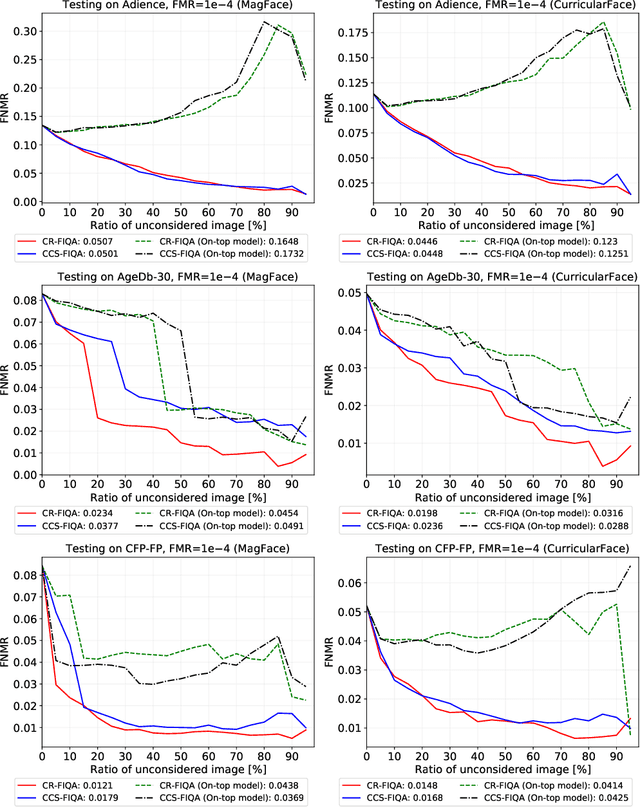

The quality of face images significantly influences the performance of underlying face recognition algorithms. Face image quality assessment (FIQA) estimates the utility of the captured image in achieving reliable and accurate recognition performance. In this work, we propose a novel learning paradigm that learns internal network observations during the training process. Based on that, our proposed CR-FIQA uses this paradigm to estimate the face image quality of a sample by predicting its relative classifiability. This classifiability is measured based on the allocation of the training sample feature representation in angular space with respect to its class center and the nearest negative class center. We experimentally illustrate the correlation between the face image quality and the sample relative classifiability. As such property is only observable for the training dataset, we propose to learn this property from the training dataset and utilize it to predict the quality measure on unseen samples. This training is performed simultaneously while optimizing the class centers by an angular margin penalty-based softmax loss used for face recognition model training. Through extensive evaluation experiments on eight benchmarks and four face recognition models, we demonstrate the superiority of our proposed CR-FIQA over state-of-the-art (SOTA) FIQA algorithms.
Explainability of the Implications of Supervised and Unsupervised Face Image Quality Estimations Through Activation Map Variation Analyses in Face Recognition Models
Dec 09, 2021

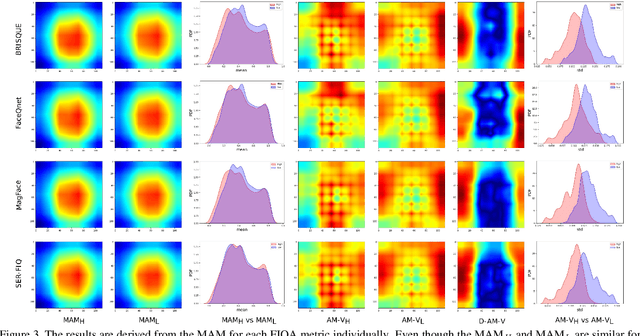

It is challenging to derive explainability for unsupervised or statistical-based face image quality assessment (FIQA) methods. In this work, we propose a novel set of explainability tools to derive reasoning for different FIQA decisions and their face recognition (FR) performance implications. We avoid limiting the deployment of our tools to certain FIQA methods by basing our analyses on the behavior of FR models when processing samples with different FIQA decisions. This leads to explainability tools that can be applied for any FIQA method with any CNN-based FR solution using activation mapping to exhibit the network's activation derived from the face embedding. To avoid the low discrimination between the general spatial activation mapping of low and high-quality images in FR models, we build our explainability tools in a higher derivative space by analyzing the variation of the FR activation maps of image sets with different quality decisions. We demonstrate our tools and analyze the findings on four FIQA methods, by presenting inter and intra-FIQA method analyses. Our proposed tools and the analyses based on them point out, among other conclusions, that high-quality images typically cause consistent low activation on the areas outside of the central face region, while low-quality images, despite general low activation, have high variations of activation in such areas. Our explainability tools also extend to analyzing single images where we show that low-quality images tend to have an FR model spatial activation that strongly differs from what is expected from a high-quality image where this difference also tends to appear more in areas outside of the central face region and does correspond to issues like extreme poses and facial occlusions. The implementation of the proposed tools is accessible here [link].
The Effect of Wearing a Face Mask on Face Image Quality
Nov 02, 2021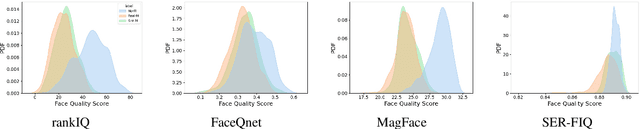

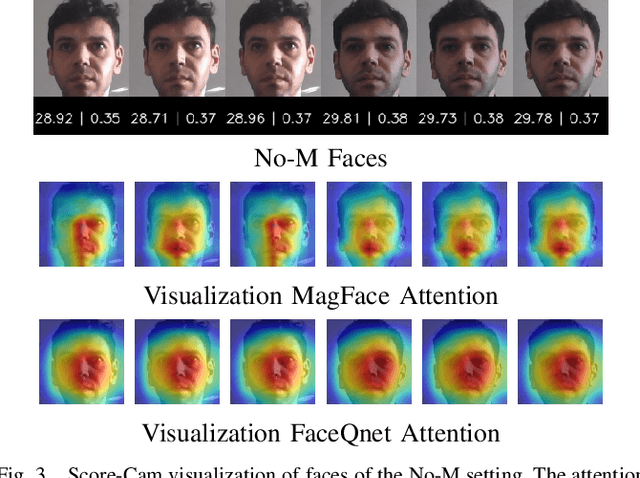

Due to the COVID-19 situation, face masks have become a main part of our daily life. Wearing mouth-and-nose protection has been made a mandate in many public places, to prevent the spread of the COVID-19 virus. However, face masks affect the performance of face recognition, since a large area of the face is covered. The effect of wearing a face mask on the different components of the face recognition system in a collaborative environment is a problem that is still to be fully studied. This work studies, for the first time, the effect of wearing a face mask on face image quality by utilising state-of-the-art face image quality assessment methods of different natures. This aims at providing better understanding on the effect of face masks on the operation of face recognition as a whole system. In addition, we further studied the effect of simulated masks on face image utility in comparison to real face masks. We discuss the correlation between the mask effect on face image quality and that on the face verification performance by automatic systems and human experts, indicating a consistent trend between both factors. The evaluation is conducted on the database containing (1) no-masked faces, (2) real face masks, and (3) simulated face masks, by synthetically generating digital facial masks on no-masked faces. Finally, a visual interpretation of the face areas contributing to the quality score of a selected set of quality assessment methods is provided to give a deeper insight into the difference of network decisions in masked and non-masked faces, among other variations.
A Deep Insight into Measuring Face Image Utility with General and Face-specific Image Quality Metrics
Oct 22, 2021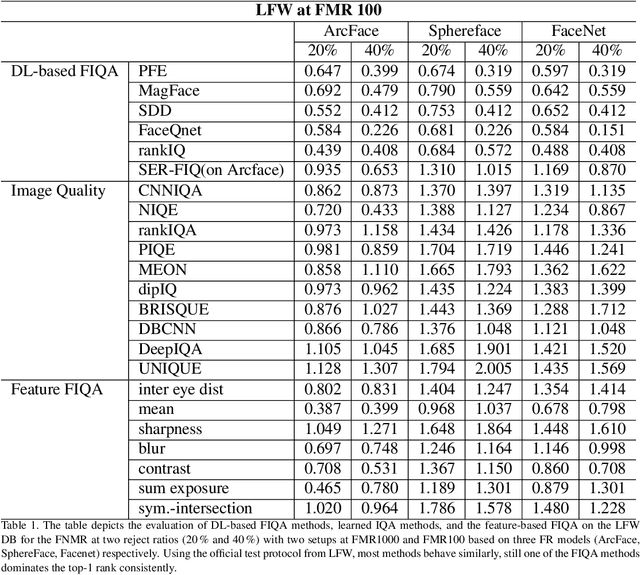
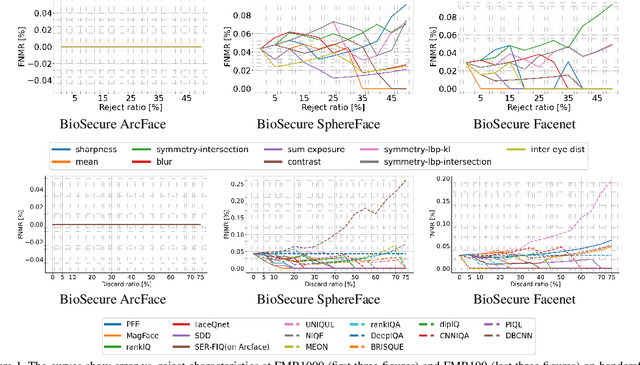
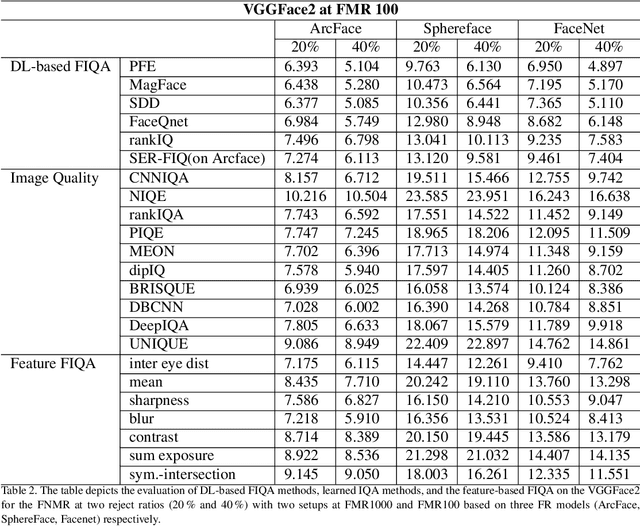
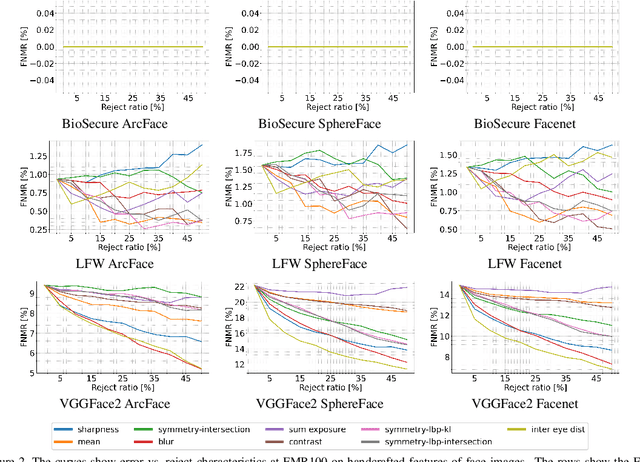
Quality scores provide a measure to evaluate the utility of biometric samples for biometric recognition. Biometric recognition systems require high-quality samples to achieve optimal performance. This paper focuses on face images and the measurement of face image utility with general and face-specific image quality metrics. While face-specific metrics rely on features of aligned face images, general image quality metrics can be used on the global image and relate to human perceptions. In this paper, we analyze the gap between the general image quality metrics and the face image quality metrics. Our contribution lies in a thorough examination of how different the image quality assessment algorithms relate to the utility for the face recognition task. The results of image quality assessment algorithms are further compared with those of dedicated face image quality assessment algorithms. In total, 25 different quality metrics are evaluated on three face image databases, BioSecure, LFW, and VGGFace2 using three open-source face recognition solutions, SphereFace, ArcFace, and FaceNet. Our results reveal a clear correlation between learned image metrics to face image utility even without being specifically trained as a face utility measure. Individual handcrafted features lack general stability and perform significantly worse than general face-specific quality metrics. We additionally provide a visual insight into the image areas contributing to the quality score of a selected set of quality assessment methods.