 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFake Doctor: Diagnosing and Treating Audio-Video Fake Detection
Jun 06, 2025Generative AI advances rapidly, allowing the creation of very realistic manipulated video and audio. This progress presents a significant security and ethical threat, as malicious users can exploit DeepFake techniques to spread misinformation. Recent DeepFake detection approaches explore the multimodal (audio-video) threat scenario. In particular, there is a lack of reproducibility and critical issues with existing datasets - such as the recently uncovered silence shortcut in the widely used FakeAVCeleb dataset. Considering the importance of this topic, we aim to gain a deeper understanding of the key issues affecting benchmarking in audio-video DeepFake detection. We examine these challenges through the lens of the three core benchmarking pillars: datasets, detection methods, and evaluation protocols. To address these issues, we spotlight the recent DeepSpeak v1 dataset and are the first to propose an evaluation protocol and benchmark it using SOTA models. We introduce SImple Multimodal BAseline (SIMBA), a competitive yet minimalistic approach that enables the exploration of diverse design choices. We also deepen insights into the issue of audio shortcuts and present a promising mitigation strategy. Finally, we analyze and enhance the evaluation scheme on the widely used FakeAVCeleb dataset. Our findings offer a way forward in the complex area of audio-video DeepFake detection.
ExFaceGAN: Exploring Identity Directions in GAN's Learned Latent Space for Synthetic Identity Generation
Jul 18, 2023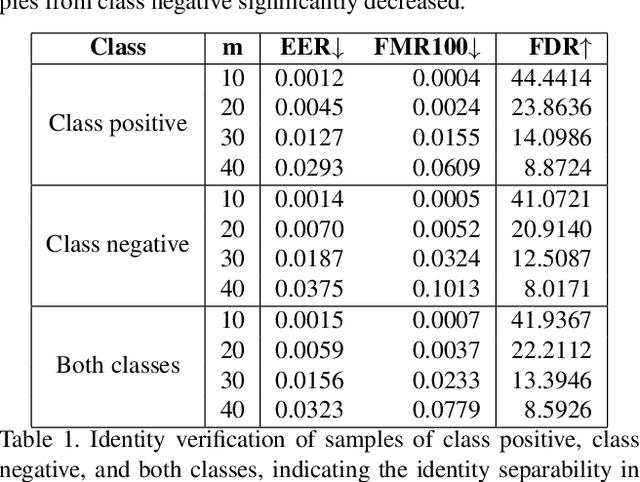

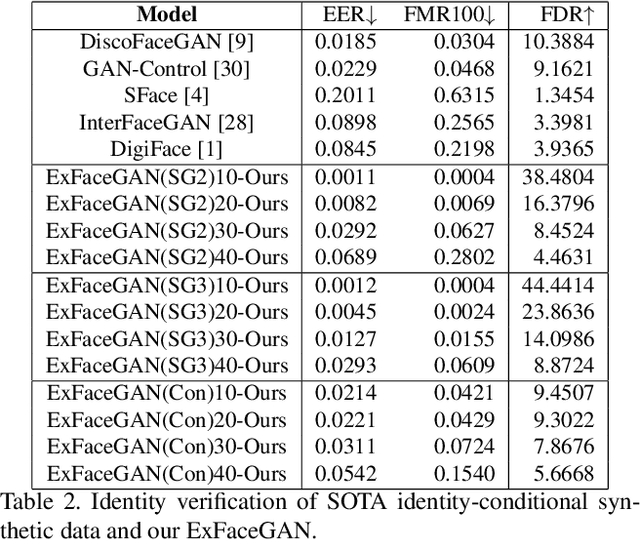

Deep generative models have recently presented impressive results in generating realistic face images of random synthetic identities. To generate multiple samples of a certain synthetic identity, previous works proposed to disentangle the latent space of GANs by incorporating additional supervision or regularization, enabling the manipulation of certain attributes. Others proposed to disentangle specific factors in unconditional pretrained GANs latent spaces to control their output, which also requires supervision by attribute classifiers. Moreover, these attributes are entangled in GAN's latent space, making it difficult to manipulate them without affecting the identity information. We propose in this work a framework, ExFaceGAN, to disentangle identity information in pretrained GANs latent spaces, enabling the generation of multiple samples of any synthetic identity. Given a reference latent code of any synthetic image and latent space of pretrained GAN, our ExFaceGAN learns an identity directional boundary that disentangles the latent space into two sub-spaces, with latent codes of samples that are either identity similar or dissimilar to a reference image. By sampling from each side of the boundary, our ExFaceGAN can generate multiple samples of synthetic identity without the need for designing a dedicated architecture or supervision from attribute classifiers. We demonstrate the generalizability and effectiveness of ExFaceGAN by integrating it into learned latent spaces of three SOTA GAN approaches. As an example of the practical benefit of our ExFaceGAN, we empirically prove that data generated by ExFaceGAN can be successfully used to train face recognition models (\url{https://github.com/fdbtrs/ExFaceGAN}).
Unsupervised Face Recognition using Unlabeled Synthetic Data
Nov 14, 2022



Over the past years, the main research innovations in face recognition focused on training deep neural networks on large-scale identity-labeled datasets using variations of multi-class classification losses. However, many of these datasets are retreated by their creators due to increased privacy and ethical concerns. Very recently, privacy-friendly synthetic data has been proposed as an alternative to privacy-sensitive authentic data to comply with privacy regulations and to ensure the continuity of face recognition research. In this paper, we propose an unsupervised face recognition model based on unlabeled synthetic data (USynthFace). Our proposed USynthFace learns to maximize the similarity between two augmented images of the same synthetic instance. We enable this by a large set of geometric and color transformations in addition to GAN-based augmentation that contributes to the USynthFace model training. We also conduct numerous empirical studies on different components of our USynthFace. With the proposed set of augmentation operations, we proved the effectiveness of our USynthFace in achieving relatively high recognition accuracies using unlabeled synthetic data.
CR-FIQA: Face Image Quality Assessment by Learning Sample Relative Classifiability
Dec 13, 2021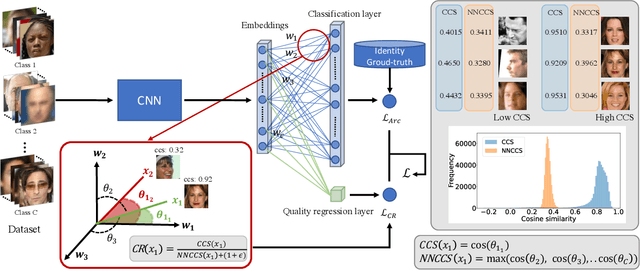
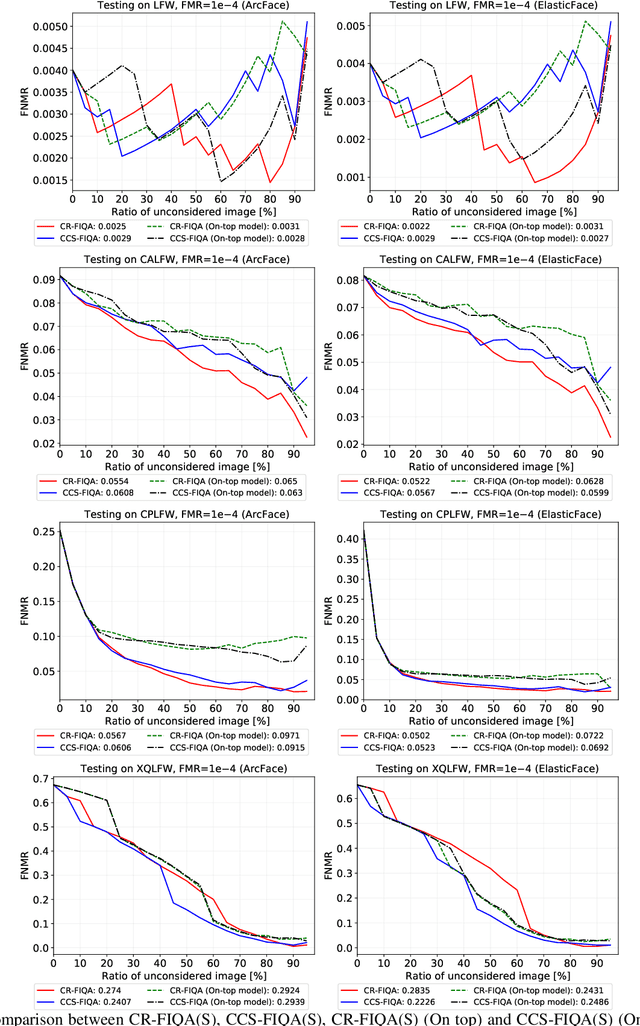
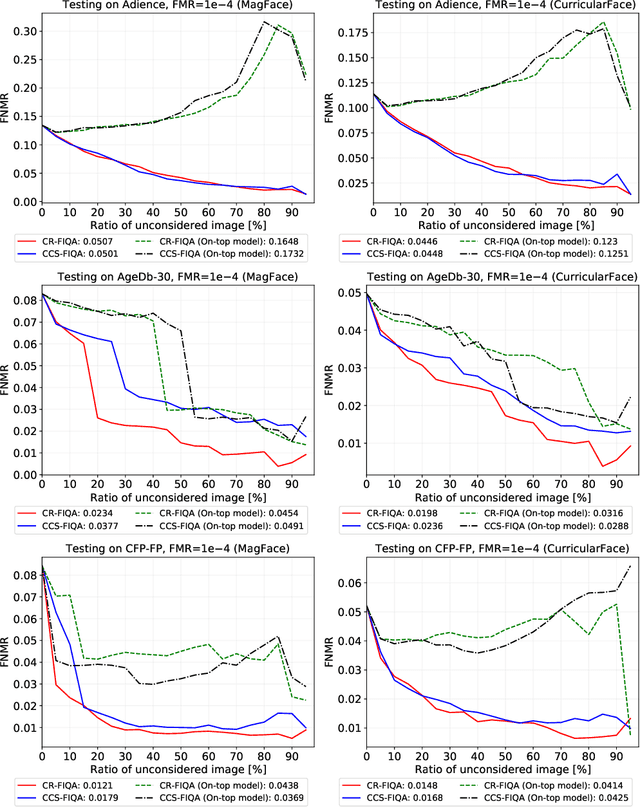

The quality of face images significantly influences the performance of underlying face recognition algorithms. Face image quality assessment (FIQA) estimates the utility of the captured image in achieving reliable and accurate recognition performance. In this work, we propose a novel learning paradigm that learns internal network observations during the training process. Based on that, our proposed CR-FIQA uses this paradigm to estimate the face image quality of a sample by predicting its relative classifiability. This classifiability is measured based on the allocation of the training sample feature representation in angular space with respect to its class center and the nearest negative class center. We experimentally illustrate the correlation between the face image quality and the sample relative classifiability. As such property is only observable for the training dataset, we propose to learn this property from the training dataset and utilize it to predict the quality measure on unseen samples. This training is performed simultaneously while optimizing the class centers by an angular margin penalty-based softmax loss used for face recognition model training. Through extensive evaluation experiments on eight benchmarks and four face recognition models, we demonstrate the superiority of our proposed CR-FIQA over state-of-the-art (SOTA) FIQA algorithms.
PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and Multi-Step Knowledge Distillation
Aug 24, 2021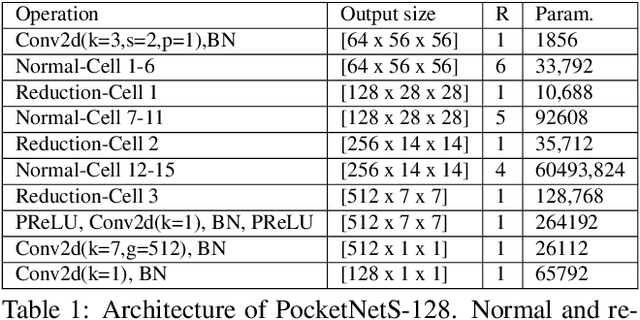
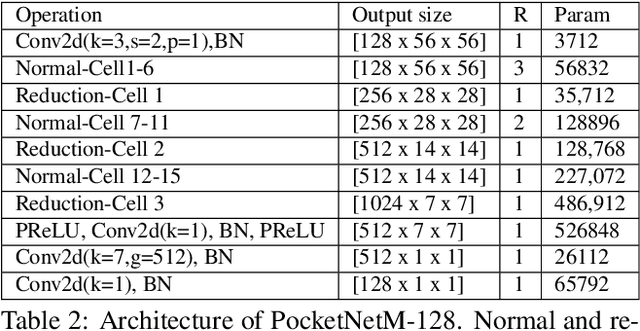
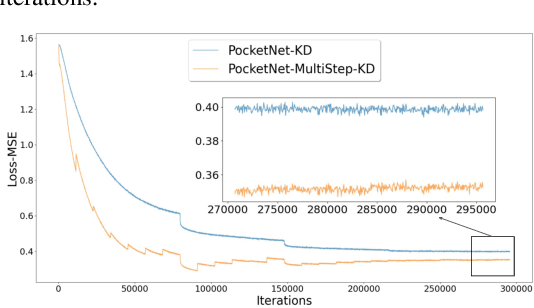
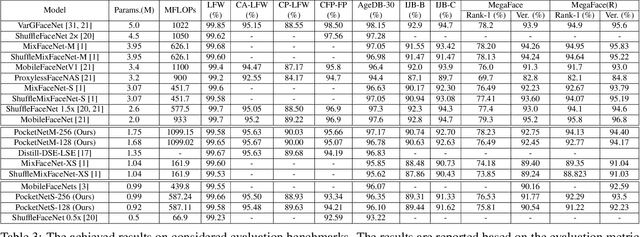
Deep neural networks have rapidly become the mainstream method for face recognition. However, deploying such models that contain an extremely large number of parameters to embedded devices or in application scenarios with limited memory footprint is challenging. In this work, we present an extremely lightweight and accurate face recognition solution. We utilize neural architecture search to develop a new family of face recognition models, namely PocketNet. We also propose to enhance the verification performance of the compact model by presenting a novel training paradigm based on knowledge distillation, namely the multi-step knowledge distillation. We present an extensive experimental evaluation and comparisons with the recent compact face recognition models on nine different benchmarks including large-scale evaluation benchmarks such as IJB-B, IJB-C, and MegaFace. PocketNets have consistently advanced the state-of-the-art (SOTA) face recognition performance on nine mainstream benchmarks when considering the same level of model compactness. With 0.92M parameters, our smallest network PocketNetS-128 achieved very competitive results to recent SOTA compacted models that contain more than 4M parameters. Training codes and pre-trained models are publicly released https://github.com/fdbtrs/PocketNet.