 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynFacePAD 2023: Competition on Face Presentation Attack Detection Based on Privacy-aware Synthetic Training Data
Nov 09, 2023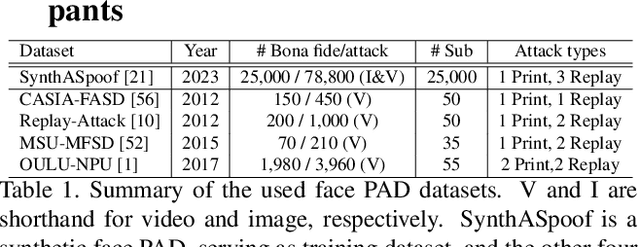

This paper presents a summary of the Competition on Face Presentation Attack Detection Based on Privacy-aware Synthetic Training Data (SynFacePAD 2023) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition attracted a total of 8 participating teams with valid submissions from academia and industry. The competition aimed to motivate and attract solutions that target detecting face presentation attacks while considering synthetic-based training data motivated by privacy, legal and ethical concerns associated with personal data. To achieve that, the training data used by the participants was limited to synthetic data provided by the organizers. The submitted solutions presented innovations and novel approaches that led to outperforming the considered baseline in the investigated benchmarks.
Iris Liveness Detection Competition (LivDet-Iris) -- The 2023 Edition
Oct 06, 2023



This paper describes the results of the 2023 edition of the ''LivDet'' series of iris presentation attack detection (PAD) competitions. New elements in this fifth competition include (1) GAN-generated iris images as a category of presentation attack instruments (PAI), and (2) an evaluation of human accuracy at detecting PAI as a reference benchmark. Clarkson University and the University of Notre Dame contributed image datasets for the competition, composed of samples representing seven different PAI categories, as well as baseline PAD algorithms. Fraunhofer IGD, Beijing University of Civil Engineering and Architecture, and Hochschule Darmstadt contributed results for a total of eight PAD algorithms to the competition. Accuracy results are analyzed by different PAI types, and compared to human accuracy. Overall, the Fraunhofer IGD algorithm, using an attention-based pixel-wise binary supervision network, showed the best-weighted accuracy results (average classification error rate of 37.31%), while the Beijing University of Civil Engineering and Architecture's algorithm won when equal weights for each PAI were given (average classification rate of 22.15%). These results suggest that iris PAD is still a challenging problem.
Liveness Detection Competition -- Noncontact-based Fingerprint Algorithms and Systems (LivDet-2023 Noncontact Fingerprint)
Oct 01, 2023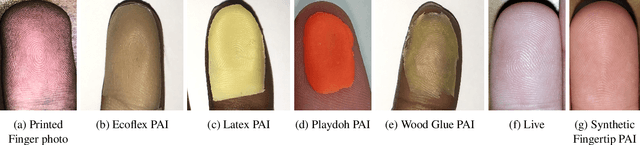


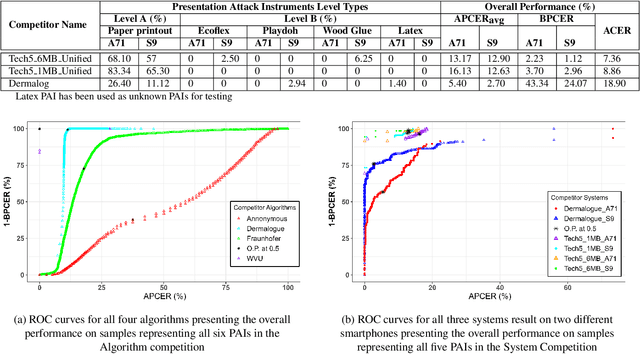
Liveness Detection (LivDet) is an international competition series open to academia and industry with the objec-tive to assess and report state-of-the-art in Presentation Attack Detection (PAD). LivDet-2023 Noncontact Fingerprint is the first edition of the noncontact fingerprint-based PAD competition for algorithms and systems. The competition serves as an important benchmark in noncontact-based fingerprint PAD, offering (a) independent assessment of the state-of-the-art in noncontact-based fingerprint PAD for algorithms and systems, and (b) common evaluation protocol, which includes finger photos of a variety of Presentation Attack Instruments (PAIs) and live fingers to the biometric research community (c) provides standard algorithm and system evaluation protocols, along with the comparative analysis of state-of-the-art algorithms from academia and industry with both old and new android smartphones. The winning algorithm achieved an APCER of 11.35% averaged overall PAIs and a BPCER of 0.62%. The winning system achieved an APCER of 13.0.4%, averaged over all PAIs tested over all the smartphones, and a BPCER of 1.68% over all smartphones tested. Four-finger systems that make individual finger-based PAD decisions were also tested. The dataset used for competition will be available 1 to all researchers as per data share protocol
Face Presentation Attack Detection by Excavating Causal Clues and Adapting Embedding Statistics
Aug 28, 2023



Recent face presentation attack detection (PAD) leverages domain adaptation (DA) and domain generalization (DG) techniques to address performance degradation on unknown domains. However, DA-based PAD methods require access to unlabeled target data, while most DG-based PAD solutions rely on a priori, i.e., known domain labels. Moreover, most DA-/DG-based methods are computationally intensive, demanding complex model architectures and/or multi-stage training processes. This paper proposes to model face PAD as a compound DG task from a causal perspective, linking it to model optimization. We excavate the causal factors hidden in the high-level representation via counterfactual intervention. Moreover, we introduce a class-guided MixStyle to enrich feature-level data distribution within classes instead of focusing on domain information. Both class-guided MixStyle and counterfactual intervention components introduce no extra trainable parameters and negligible computational resources. Extensive cross-dataset and analytic experiments demonstrate the effectiveness and efficiency of our method compared to state-of-the-art PADs. The implementation and the trained weights are publicly available.
ExFaceGAN: Exploring Identity Directions in GAN's Learned Latent Space for Synthetic Identity Generation
Jul 18, 2023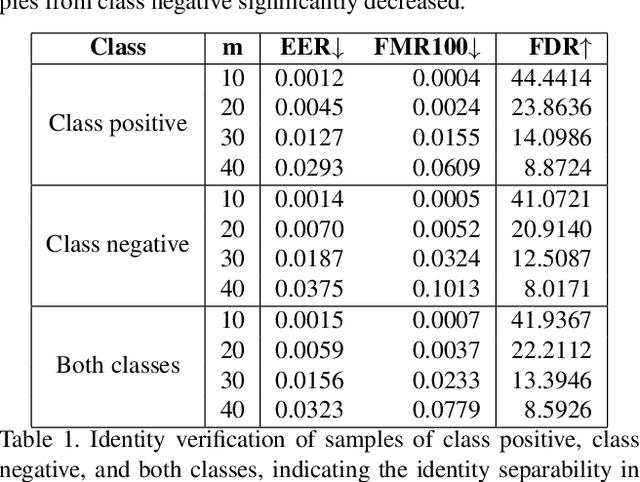

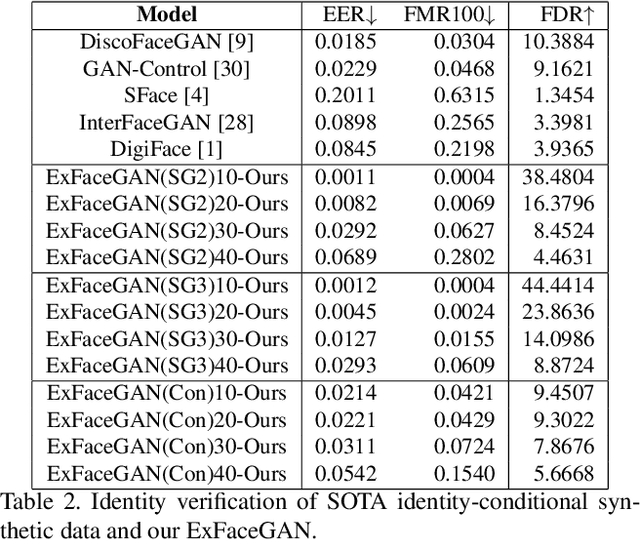

Deep generative models have recently presented impressive results in generating realistic face images of random synthetic identities. To generate multiple samples of a certain synthetic identity, previous works proposed to disentangle the latent space of GANs by incorporating additional supervision or regularization, enabling the manipulation of certain attributes. Others proposed to disentangle specific factors in unconditional pretrained GANs latent spaces to control their output, which also requires supervision by attribute classifiers. Moreover, these attributes are entangled in GAN's latent space, making it difficult to manipulate them without affecting the identity information. We propose in this work a framework, ExFaceGAN, to disentangle identity information in pretrained GANs latent spaces, enabling the generation of multiple samples of any synthetic identity. Given a reference latent code of any synthetic image and latent space of pretrained GAN, our ExFaceGAN learns an identity directional boundary that disentangles the latent space into two sub-spaces, with latent codes of samples that are either identity similar or dissimilar to a reference image. By sampling from each side of the boundary, our ExFaceGAN can generate multiple samples of synthetic identity without the need for designing a dedicated architecture or supervision from attribute classifiers. We demonstrate the generalizability and effectiveness of ExFaceGAN by integrating it into learned latent spaces of three SOTA GAN approaches. As an example of the practical benefit of our ExFaceGAN, we empirically prove that data generated by ExFaceGAN can be successfully used to train face recognition models (\url{https://github.com/fdbtrs/ExFaceGAN}).
Are Explainability Tools Gender Biased? A Case Study on Face Presentation Attack Detection
Apr 26, 2023Face recognition (FR) systems continue to spread in our daily lives with an increasing demand for higher explainability and interpretability of FR systems that are mainly based on deep learning. While bias across demographic groups in FR systems has already been studied, the bias of explainability tools has not yet been investigated. As such tools aim at steering further development and enabling a better understanding of computer vision problems, the possible existence of bias in their outcome can lead to a chain of biased decisions. In this paper, we explore the existence of bias in the outcome of explainability tools by investigating the use case of face presentation attack detection. By utilizing two different explainability tools on models with different levels of bias, we investigate the bias in the outcome of such tools. Our study shows that these tools show clear signs of gender bias in the quality of their explanations.
SynthASpoof: Developing Face Presentation Attack Detection Based on Privacy-friendly Synthetic Data
Mar 05, 2023Recently, significant progress has been made in face presentation attack detection (PAD), which aims to secure face recognition systems against presentation attacks, owing to the availability of several face PAD datasets. However, all available datasets are based on privacy and legally-sensitive authentic biometric data with a limited number of subjects. To target these legal and technical challenges, this work presents the first synthetic-based face PAD dataset, named SynthASpoof, as a large-scale PAD development dataset. The bona fide samples in SynthASpoof are synthetically generated and the attack samples are collected by presenting such synthetic data to capture systems in a real attack scenario. The experimental results demonstrate the feasibility of using SynthASpoof for the development of face PAD. Moreover, we boost the performance of such a solution by incorporating the domain generalization tool MixStyle into the PAD solutions. Additionally, we showed the viability of using synthetic data as a supplement to enrich the diversity of limited authentic training data and consistently enhance PAD performances. The SynthASpoof dataset, containing 25,000 bona fide and 78,800 attack samples, the implementation, and the pre-trained weights are made publicly available.
MorDIFF: Recognition Vulnerability and Attack Detectability of Face Morphing Attacks Created by Diffusion Autoencoders
Feb 03, 2023Investigating new methods of creating face morphing attacks is essential to foresee novel attacks and help mitigate them. Creating morphing attacks is commonly either performed on the image-level or on the representation-level. The representation-level morphing has been performed so far based on generative adversarial networks (GAN) where the encoded images are interpolated in the latent space to produce a morphed image based on the interpolated vector. Such a process was constrained by the limited reconstruction fidelity of GAN architectures. Recent advances in the diffusion autoencoder models have overcome the GAN limitations, leading to high reconstruction fidelity. This theoretically makes them a perfect candidate to perform representation-level face morphing. This work investigates using diffusion autoencoders to create face morphing attacks by comparing them to a wide range of image-level and representation-level morphs. Our vulnerability analyses on four state-of-the-art face recognition models have shown that such models are highly vulnerable to the created attacks, the MorDIFF, especially when compared to existing representation-level morphs. Detailed detectability analyses are also performed on the MorDIFF, showing that they are as challenging to detect as other morphing attacks created on the image- or representation-level. Data and morphing script are made public.
Unsupervised Face Recognition using Unlabeled Synthetic Data
Nov 14, 2022



Over the past years, the main research innovations in face recognition focused on training deep neural networks on large-scale identity-labeled datasets using variations of multi-class classification losses. However, many of these datasets are retreated by their creators due to increased privacy and ethical concerns. Very recently, privacy-friendly synthetic data has been proposed as an alternative to privacy-sensitive authentic data to comply with privacy regulations and to ensure the continuity of face recognition research. In this paper, we propose an unsupervised face recognition model based on unlabeled synthetic data (USynthFace). Our proposed USynthFace learns to maximize the similarity between two augmented images of the same synthetic instance. We enable this by a large set of geometric and color transformations in addition to GAN-based augmentation that contributes to the USynthFace model training. We also conduct numerous empirical studies on different components of our USynthFace. With the proposed set of augmentation operations, we proved the effectiveness of our USynthFace in achieving relatively high recognition accuracies using unlabeled synthetic data.
Fairness in Face Presentation Attack Detection
Sep 19, 2022
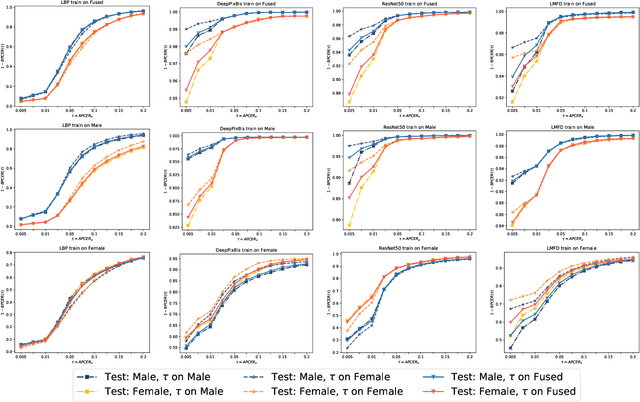
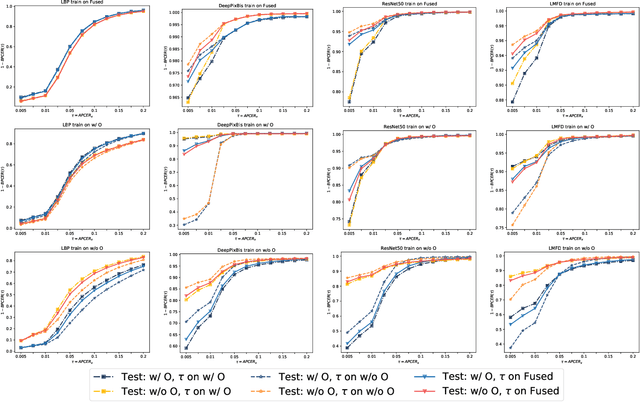

Face presentation attack detection (PAD) is critical to secure face recognition (FR) applications from presentation attacks. FR performance has been shown to be unfair to certain demographic and non-demographic groups. However, the fairness of face PAD is an understudied issue, mainly due to the lack of appropriately annotated data. To address this issue, this work first presents a Combined Attribute Annotated PAD Dataset (CAAD-PAD) by combining several well-known PAD datasets where we provide seven human-annotated attribute labels. This work then comprehensively analyses the fairness of a set of face PADs and its relation to the nature of training data and the Operational Decision Threshold Assignment (ODTA) on different data groups by studying four face PAD approaches on our CAAD-PAD. To simultaneously represent both the PAD fairness and the absolute PAD performance, we introduce a novel metric, namely the Accuracy Balanced Fairness (ABF). Extensive experiments on CAAD-PAD show that the training data and ODTA induce unfairness on gender, occlusion, and other attribute groups. Based on these analyses, we propose a data augmentation method, FairSWAP, which aims to disrupt the identity/semantic information and guide models to mine attack cues rather than attribute-related information. Detailed experimental results demonstrate that FairSWAP generally enhances both the PAD performance and the fairness of face PAD.