 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Time Series Language Model for Descriptive Caption Generation
Jan 03, 2025



The automatic generation of representative natural language descriptions for observable patterns in time series data enhances interpretability, simplifies analysis and increases cross-domain utility of temporal data. While pre-trained foundation models have made considerable progress in natural language processing (NLP) and computer vision (CV), their application to time series analysis has been hindered by data scarcity. Although several large language model (LLM)-based methods have been proposed for time series forecasting, time series captioning is under-explored in the context of LLMs. In this paper, we introduce TSLM, a novel time series language model designed specifically for time series captioning. TSLM operates as an encoder-decoder model, leveraging both text prompts and time series data representations to capture subtle temporal patterns across multiple phases and generate precise textual descriptions of time series inputs. TSLM addresses the data scarcity problem in time series captioning by first leveraging an in-context prompting synthetic data generation, and second denoising the generated data via a novel cross-modal dense retrieval scoring applied to time series-caption pairs. Experimental findings on various time series captioning datasets demonstrate that TSLM outperforms existing state-of-the-art approaches from multiple data modalities by a significant margin.
Training Better Deep Learning Models Using Human Saliency
Oct 21, 2024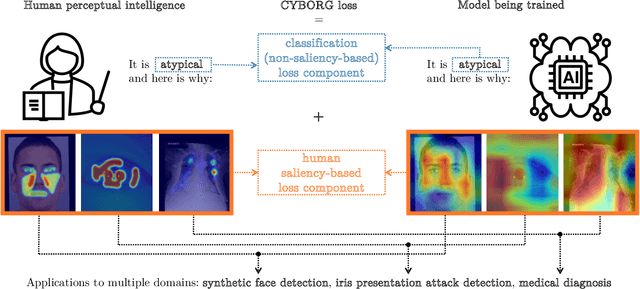
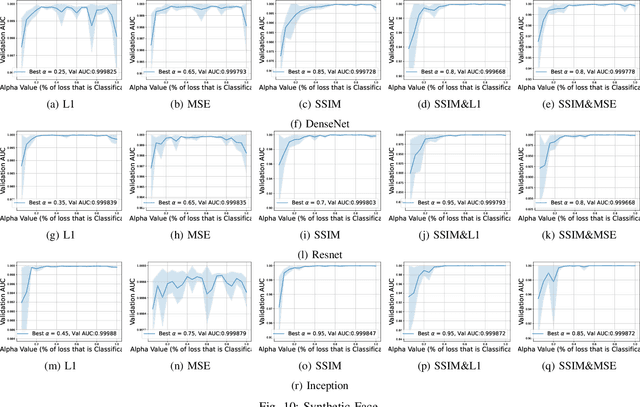
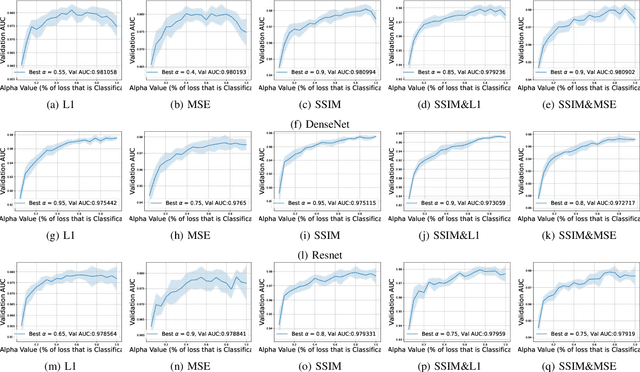
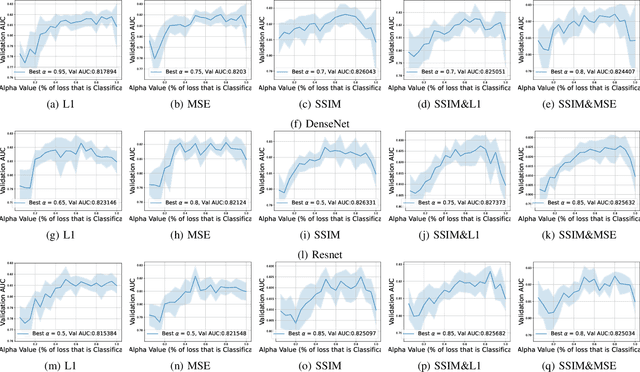
This work explores how human judgement about salient regions of an image can be introduced into deep convolutional neural network (DCNN) training. Traditionally, training of DCNNs is purely data-driven. This often results in learning features of the data that are only coincidentally correlated with class labels. Human saliency can guide network training using our proposed new component of the loss function that ConveYs Brain Oversight to Raise Generalization (CYBORG) and penalizes the model for using non-salient regions. This mechanism produces DCNNs achieving higher accuracy and generalization compared to using the same training data without human salience. Experimental results demonstrate that CYBORG applies across multiple network architectures and problem domains (detection of synthetic faces, iris presentation attacks and anomalies in chest X-rays), while requiring significantly less data than training without human saliency guidance. Visualizations show that CYBORG-trained models' saliency is more consistent across independent training runs than traditionally-trained models, and also in better agreement with humans. To lower the cost of collecting human annotations, we also explore using deep learning to provide automated annotations. CYBORG training of CNNs addresses important issues such as reducing the appetite for large training sets, increasing interpretability, and reducing fragility by generalizing better to new types of data.
Increasing Interpretability of Neural Networks By Approximating Human Visual Saliency
Oct 21, 2024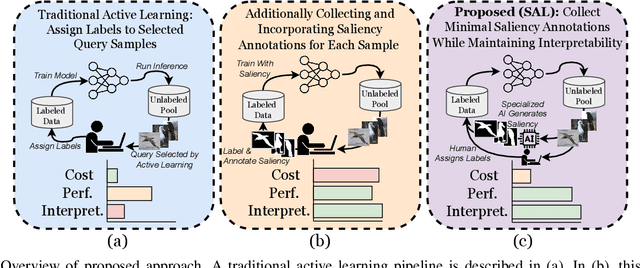
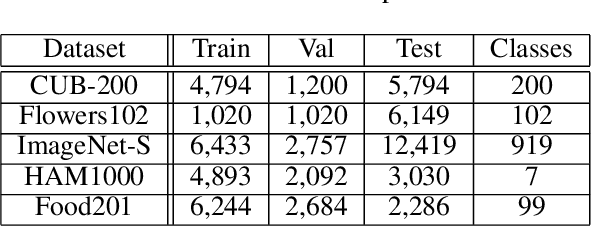

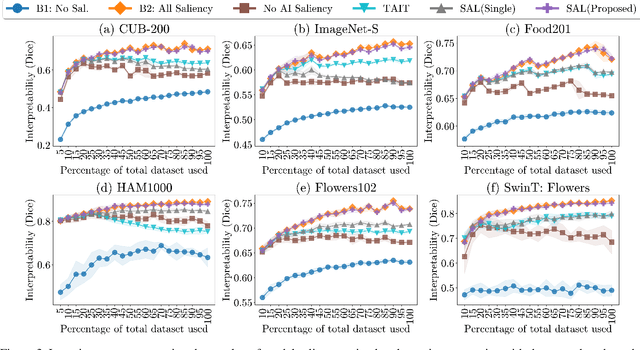
Understanding specifically where a model focuses on within an image is critical for human interpretability of the decision-making process. Deep learning-based solutions are prone to learning coincidental correlations in training datasets, causing over-fitting and reducing the explainability. Recent advances have shown that guiding models to human-defined regions of saliency within individual images significantly increases performance and interpretability. Human-guided models also exhibit greater generalization capabilities, as coincidental dataset features are avoided. Results show that models trained with saliency incorporation display an increase in interpretability of up to 30% over models trained without saliency information. The collection of this saliency information, however, can be costly, laborious and in some cases infeasible. To address this limitation, we propose a combination strategy of saliency incorporation and active learning to reduce the human annotation data required by 80% while maintaining the interpretability and performance increase from human saliency. Extensive experimentation outlines the effectiveness of the proposed approach across five public datasets and six active learning criteria.
Iris Liveness Detection Competition (LivDet-Iris) -- The 2023 Edition
Oct 06, 2023



This paper describes the results of the 2023 edition of the ''LivDet'' series of iris presentation attack detection (PAD) competitions. New elements in this fifth competition include (1) GAN-generated iris images as a category of presentation attack instruments (PAI), and (2) an evaluation of human accuracy at detecting PAI as a reference benchmark. Clarkson University and the University of Notre Dame contributed image datasets for the competition, composed of samples representing seven different PAI categories, as well as baseline PAD algorithms. Fraunhofer IGD, Beijing University of Civil Engineering and Architecture, and Hochschule Darmstadt contributed results for a total of eight PAD algorithms to the competition. Accuracy results are analyzed by different PAI types, and compared to human accuracy. Overall, the Fraunhofer IGD algorithm, using an attention-based pixel-wise binary supervision network, showed the best-weighted accuracy results (average classification error rate of 37.31%), while the Beijing University of Civil Engineering and Architecture's algorithm won when equal weights for each PAI were given (average classification rate of 22.15%). These results suggest that iris PAD is still a challenging problem.
Teaching AI to Teach: Leveraging Limited Human Salience Data Into Unlimited Saliency-Based Training
Jun 08, 2023
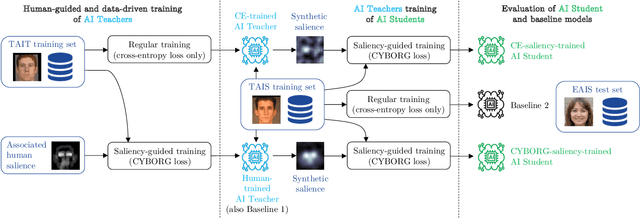

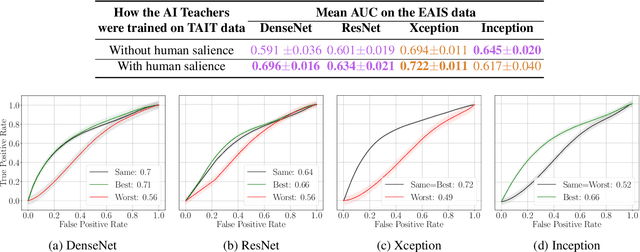
Machine learning models have shown increased accuracy in classification tasks when the training process incorporates human perceptual information. However, a challenge in training human-guided models is the cost associated with collecting image annotations for human salience. Collecting annotation data for all images in a large training set can be prohibitively expensive. In this work, we utilize ''teacher'' models (trained on a small amount of human-annotated data) to annotate additional data by means of teacher models' saliency maps. Then, ''student'' models are trained using the larger amount of annotated training data. This approach makes it possible to supplement a limited number of human-supplied annotations with an arbitrarily large number of model-generated image annotations. We compare the accuracy achieved by our teacher-student training paradigm with (1) training using all available human salience annotations, and (2) using all available training data without human salience annotations. We use synthetic face detection and fake iris detection as example challenging problems, and report results across four model architectures (DenseNet, ResNet, Xception, and Inception), and two saliency estimation methods (CAM and RISE). Results show that our teacher-student training paradigm results in models that significantly exceed the performance of both baselines, demonstrating that our approach can usefully leverage a small amount of human annotations to generate salience maps for an arbitrary amount of additional training data.
Explain To Me: Salience-Based Explainability for Synthetic Face Detection Models
Mar 27, 2023



The performance of convolutional neural networks has continued to improve over the last decade. At the same time, as model complexity grows, it becomes increasingly more difficult to explain model decisions. Such explanations may be of critical importance for reliable operation of human-machine pairing setups, or for model selection when the "best" model among many equally-accurate models must be established. Saliency maps represent one popular way of explaining model decisions by highlighting image regions models deem important when making a prediction. However, examining salience maps at scale is not practical. In this paper, we propose five novel methods of leveraging model salience to explain a model behavior at scale. These methods ask: (a) what is the average entropy for a model's salience maps, (b) how does model salience change when fed out-of-set samples, (c) how closely does model salience follow geometrical transformations, (d) what is the stability of model salience across independent training runs, and (e) how does model salience react to salience-guided image degradations. To assess the proposed measures on a concrete and topical problem, we conducted a series of experiments for the task of synthetic face detection with two types of models: those trained traditionally with cross-entropy loss, and those guided by human salience when training to increase model generalizability. These two types of models are characterized by different, interpretable properties of their salience maps, which allows for the evaluation of the correctness of the proposed measures. We offer source codes for each measure along with this paper.
State Of The Art In Open-Set Iris Presentation Attack Detection
Aug 22, 2022


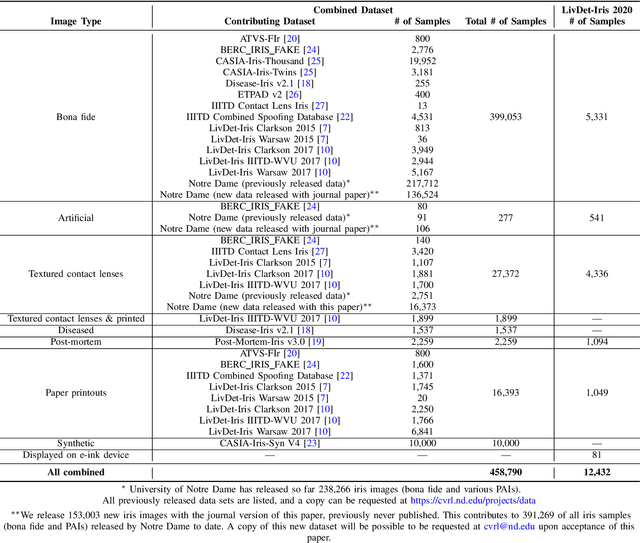
Research in presentation attack detection (PAD) for iris recognition has largely moved beyond evaluation in "closed-set" scenarios, to emphasize ability to generalize to presentation attack types not present in the training data. This paper offers several contributions to understand and extend the state-of-the-art in open-set iris PAD. First, it describes the most authoritative evaluation to date of iris PAD. We have curated the largest publicly-available image dataset for this problem, drawing from 26 benchmarks previously released by various groups, and adding 150,000 images being released with the journal version of this paper, to create a set of 450,000 images representing authentic iris and seven types of presentation attack instrument (PAI). We formulate a leave-one-PAI-out evaluation protocol, and show that even the best algorithms in the closed-set evaluations exhibit catastrophic failures on multiple attack types in the open-set scenario. This includes algorithms performing well in the most recent LivDet-Iris 2020 competition, which may come from the fact that the LivDet-Iris protocol emphasizes sequestered images rather than unseen attack types. Second, we evaluate the accuracy of five open-source iris presentation attack algorithms available today, one of which is newly-proposed in this paper, and build an ensemble method that beats the winner of the LivDet-Iris 2020 by a substantial margin. This paper demonstrates that closed-set iris PAD, when all PAIs are known during training, is a solved problem, with multiple algorithms showing very high accuracy, while open-set iris PAD, when evaluated correctly, is far from being solved. The newly-created dataset, new open-source algorithms, and evaluation protocol, made publicly available with the journal version of this paper, provide the experimental artifacts that researchers can use to measure progress on this important problem.
The Value of AI Guidance in Human Examination of Synthetically-Generated Faces
Aug 22, 2022



Face image synthesis has progressed beyond the point at which humans can effectively distinguish authentic faces from synthetically generated ones. Recently developed synthetic face image detectors boast "better-than-human" discriminative ability, especially those guided by human perceptual intelligence during the model's training process. In this paper, we investigate whether these human-guided synthetic face detectors can assist non-expert human operators in the task of synthetic image detection when compared to models trained without human-guidance. We conducted a large-scale experiment with more than 1,560 subjects classifying whether an image shows an authentic or synthetically-generated face, and annotate regions that supported their decisions. In total, 56,015 annotations across 3,780 unique face images were collected. All subjects first examined samples without any AI support, followed by samples given (a) the AI's decision ("synthetic" or "authentic"), (b) class activation maps illustrating where the model deems salient for its decision, or (c) both the AI's decision and AI's saliency map. Synthetic faces were generated with six modern Generative Adversarial Networks. Interesting observations from this experiment include: (1) models trained with human-guidance offer better support to human examination of face images when compared to models trained traditionally using cross-entropy loss, (2) binary decisions presented to humans offers better support than saliency maps, (3) understanding the AI's accuracy helps humans to increase trust in a given model and thus increase their overall accuracy. This work demonstrates that although humans supported by machines achieve better-than-random accuracy of synthetic face detection, the ways of supplying humans with AI support and of building trust are key factors determining high effectiveness of the human-AI tandem.
Human Saliency-Driven Patch-based Matching for Interpretable Post-mortem Iris Recognition
Aug 03, 2022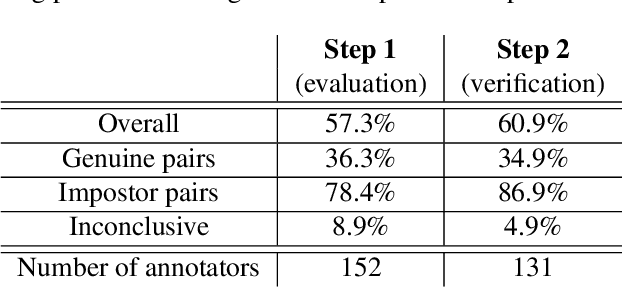
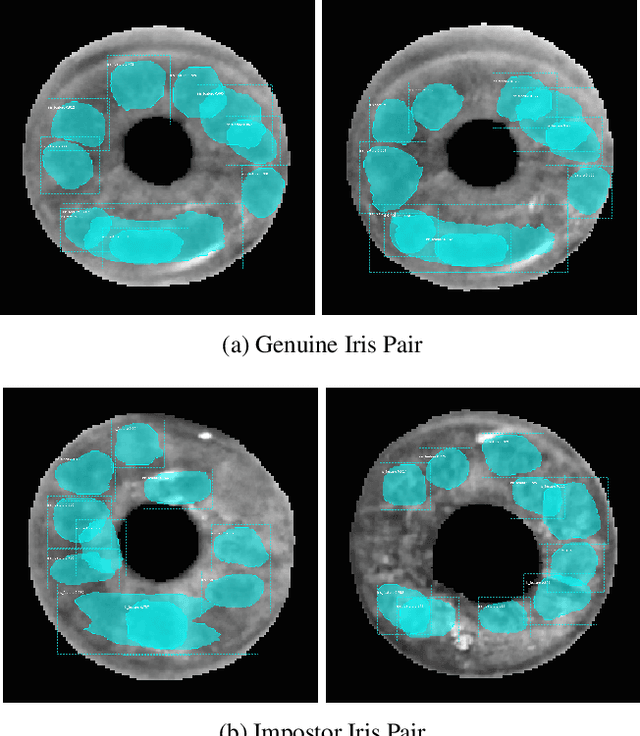
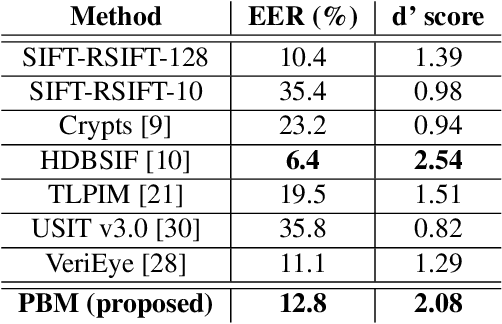
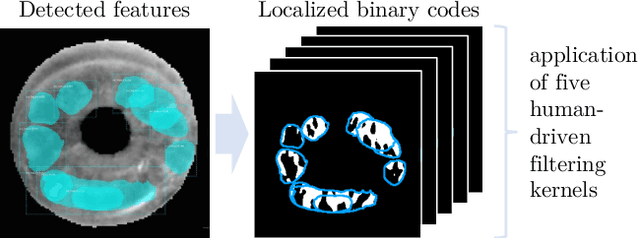
Forensic iris recognition, as opposed to live iris recognition, is an emerging research area that leverages the discriminative power of iris biometrics to aid human examiners in their efforts to identify deceased persons. As a machine learning-based technique in a predominantly human-controlled task, forensic recognition serves as "back-up" to human expertise in the task of post-mortem identification. As such, the machine learning model must be (a) interpretable, and (b) post-mortem-specific, to account for changes in decaying eye tissue. In this work, we propose a method that satisfies both requirements, and that approaches the creation of a post-mortem-specific feature extractor in a novel way employing human perception. We first train a deep learning-based feature detector on post-mortem iris images, using annotations of image regions highlighted by humans as salient for their decision making. In effect, the method learns interpretable features directly from humans, rather than purely data-driven features. Second, regional iris codes (again, with human-driven filtering kernels) are used to pair detected iris patches, which are translated into pairwise, patch-based comparison scores. In this way, our method presents human examiners with human-understandable visual cues in order to justify the identification decision and corresponding confidence score. When tested on a dataset of post-mortem iris images collected from 259 deceased subjects, the proposed method places among the three best iris matchers, demonstrating better results than the commercial (non-human-interpretable) VeriEye approach. We propose a unique post-mortem iris recognition method trained with human saliency to give fully-interpretable comparison outcomes for use in the context of forensic examination, achieving state-of-the-art recognition performance.