 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing Interpretability of Neural Networks By Approximating Human Visual Saliency
Oct 21, 2024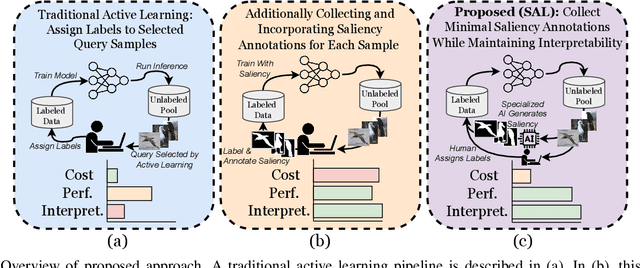
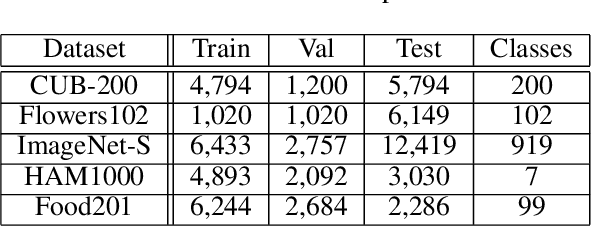

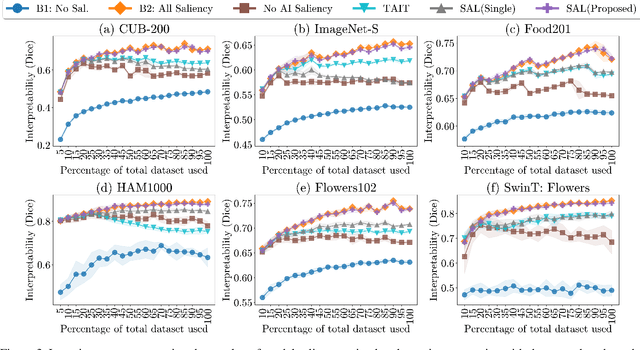
Understanding specifically where a model focuses on within an image is critical for human interpretability of the decision-making process. Deep learning-based solutions are prone to learning coincidental correlations in training datasets, causing over-fitting and reducing the explainability. Recent advances have shown that guiding models to human-defined regions of saliency within individual images significantly increases performance and interpretability. Human-guided models also exhibit greater generalization capabilities, as coincidental dataset features are avoided. Results show that models trained with saliency incorporation display an increase in interpretability of up to 30% over models trained without saliency information. The collection of this saliency information, however, can be costly, laborious and in some cases infeasible. To address this limitation, we propose a combination strategy of saliency incorporation and active learning to reduce the human annotation data required by 80% while maintaining the interpretability and performance increase from human saliency. Extensive experimentation outlines the effectiveness of the proposed approach across five public datasets and six active learning criteria.
Diffusion-based Deep Active Learning
Mar 23, 2020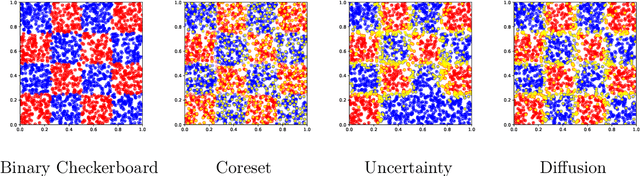
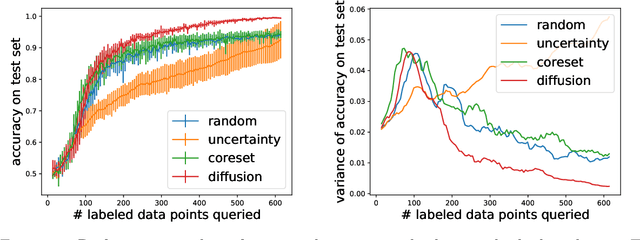
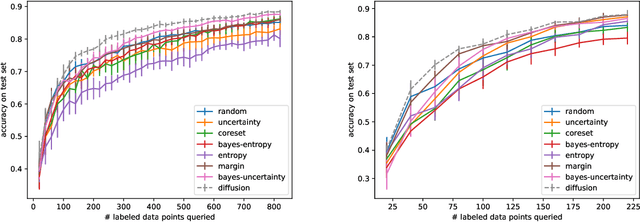
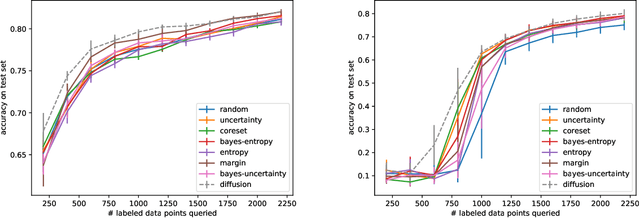
The remarkable performance of deep neural networks depends on the availability of massive labeled data. To alleviate the load of data annotation, active deep learning aims to select a minimal set of training points to be labelled which yields maximal model accuracy. Most existing approaches implement either an `exploration'-type selection criterion, which aims at exploring the joint distribution of data and labels, or a `refinement'-type criterion which aims at localizing the detected decision boundaries. We propose a versatile and efficient criterion that automatically switches from exploration to refinement when the distribution has been sufficiently mapped. Our criterion relies on a process of diffusing the existing label information over a graph constructed from the hidden representation of the data set as provided by the neural network. This graph representation captures the intrinsic geometry of the approximated labeling function. The diffusion-based criterion is shown to be advantageous as it outperforms existing criteria for deep active learning.
Linear Time Clustering for High Dimensional Mixtures of Gaussian Clouds
Mar 01, 2018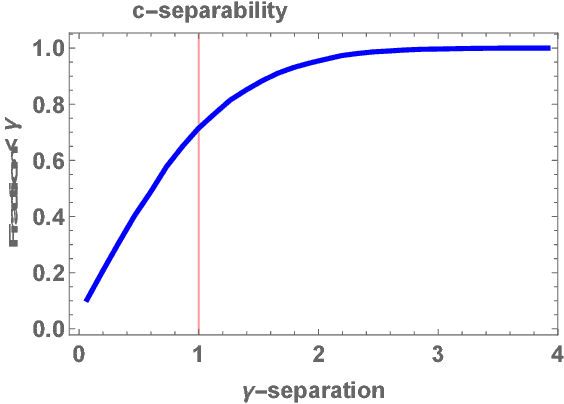

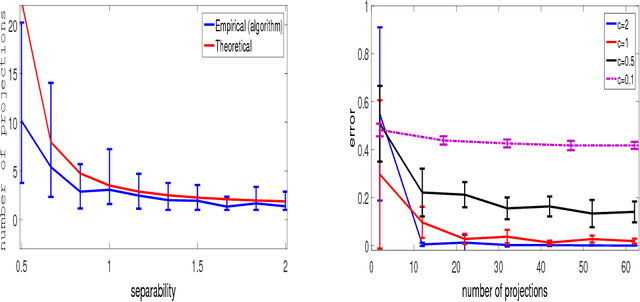
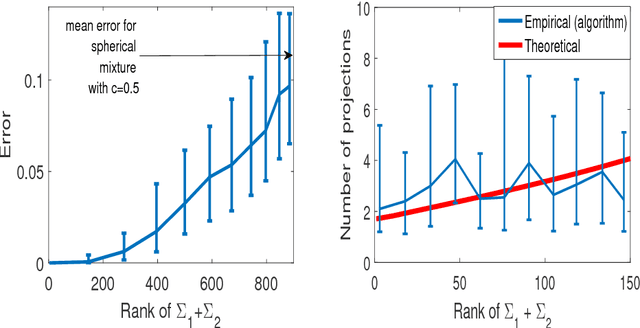
Clustering mixtures of Gaussian distributions is a fundamental and challenging problem that is ubiquitous in various high-dimensional data processing tasks. While state-of-the-art work on learning Gaussian mixture models has focused primarily on improving separation bounds and their generalization to arbitrary classes of mixture models, less emphasis has been paid to practical computational efficiency of the proposed solutions. In this paper, we propose a novel and highly efficient clustering algorithm for $n$ points drawn from a mixture of two arbitrary Gaussian distributions in $\mathbb{R}^p$. The algorithm involves performing random 1-dimensional projections until a direction is found that yields a user-specified clustering error $e$. For a 1-dimensional separation parameter $\gamma$ satisfying $\gamma=Q^{-1}(e)$, the expected number of such projections is shown to be bounded by $o(\ln p)$, when $\gamma$ satisfies $\gamma\leq c\sqrt{\ln{\ln{p}}}$, with $c$ as the separability parameter of the two Gaussians in $\mathbb{R}^p$. Consequently, the expected overall running time of the algorithm is linear in $n$ and quasi-linear in $p$ at $o(\ln{p})O(np)$, and the sample complexity is independent of $p$. This result stands in contrast to prior works which provide polynomial, with at-best quadratic, running time in $p$ and $n$. We show that our bound on the expected number of 1-dimensional projections extends to the case of three or more Gaussian components, and we present a generalization of our results to mixture distributions beyond the Gaussian model.
Active Community Detection: A Maximum Likelihood Approach
Jan 11, 2018



We propose novel semi-supervised and active learning algorithms for the problem of community detection on networks. The algorithms are based on optimizing the likelihood function of the community assignments given a graph and an estimate of the statistical model that generated it. The optimization framework is inspired by prior work on the unsupervised community detection problem in Stochastic Block Models (SBM) using Semi-Definite Programming (SDP). In this paper we provide the next steps in the evolution of learning communities in this context which involves a constrained semi-definite programming algorithm, and a newly presented active learning algorithm. The active learner intelligently queries nodes that are expected to maximize the change in the model likelihood. Experimental results show that this active learning algorithm outperforms the random-selection semi-supervised version of the same algorithm as well as other state-of-the-art active learning algorithms. Our algorithms significantly improved performance is demonstrated on both real-world and SBM-generated networks even when the SBM has a signal to noise ratio (SNR) below the known unsupervised detectability threshold.