 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing Interpretability of Neural Networks By Approximating Human Visual Saliency
Paper and Code
Oct 21, 2024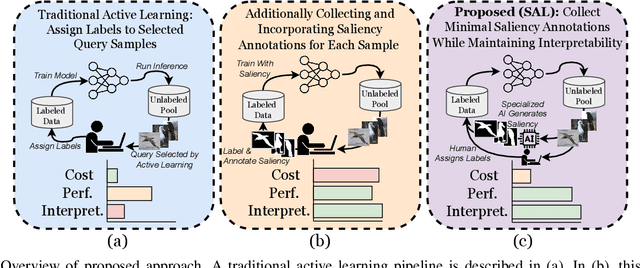
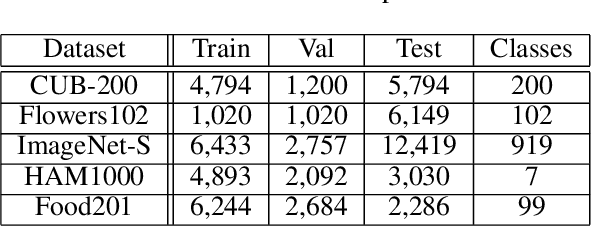

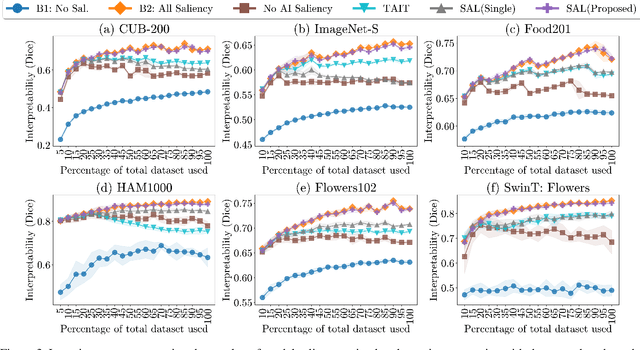
Understanding specifically where a model focuses on within an image is critical for human interpretability of the decision-making process. Deep learning-based solutions are prone to learning coincidental correlations in training datasets, causing over-fitting and reducing the explainability. Recent advances have shown that guiding models to human-defined regions of saliency within individual images significantly increases performance and interpretability. Human-guided models also exhibit greater generalization capabilities, as coincidental dataset features are avoided. Results show that models trained with saliency incorporation display an increase in interpretability of up to 30% over models trained without saliency information. The collection of this saliency information, however, can be costly, laborious and in some cases infeasible. To address this limitation, we propose a combination strategy of saliency incorporation and active learning to reduce the human annotation data required by 80% while maintaining the interpretability and performance increase from human saliency. Extensive experimentation outlines the effectiveness of the proposed approach across five public datasets and six active learning criteria.