 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleDoCTR: Domain-Specific and Contextual Troubleshooting for Telecommunications
Jan 02, 2026Ticket troubleshooting refers to the process of analyzing and resolving problems that are reported through a ticketing system. In large organizations offering a wide range of services, this task is highly complex due to the diversity of submitted tickets and the need for specialized domain knowledge. In particular, troubleshooting in telecommunications (telecom) is a very time-consuming task as it requires experts to interpret ticket content, consult documentation, and search historical records to identify appropriate resolutions. This human-intensive approach not only delays issue resolution but also hinders overall operational efficiency. To enhance the effectiveness and efficiency of ticket troubleshooting in telecom, we propose TeleDoCTR, a novel telecom-related, domain-specific, and contextual troubleshooting system tailored for end-to-end ticket resolution in telecom. TeleDoCTR integrates both domain-specific ranking and generative models to automate key steps of the troubleshooting workflow which are: routing tickets to the appropriate expert team responsible for resolving the ticket (classification task), retrieving contextually and semantically similar historical tickets (retrieval task), and generating a detailed fault analysis report outlining the issue, root cause, and potential solutions (generation task). We evaluate TeleDoCTR on a real-world dataset from a telecom infrastructure and demonstrate that it achieves superior performance over existing state-of-the-art methods, significantly enhancing the accuracy and efficiency of the troubleshooting process.
Time Series Language Model for Descriptive Caption Generation
Jan 03, 2025



The automatic generation of representative natural language descriptions for observable patterns in time series data enhances interpretability, simplifies analysis and increases cross-domain utility of temporal data. While pre-trained foundation models have made considerable progress in natural language processing (NLP) and computer vision (CV), their application to time series analysis has been hindered by data scarcity. Although several large language model (LLM)-based methods have been proposed for time series forecasting, time series captioning is under-explored in the context of LLMs. In this paper, we introduce TSLM, a novel time series language model designed specifically for time series captioning. TSLM operates as an encoder-decoder model, leveraging both text prompts and time series data representations to capture subtle temporal patterns across multiple phases and generate precise textual descriptions of time series inputs. TSLM addresses the data scarcity problem in time series captioning by first leveraging an in-context prompting synthetic data generation, and second denoising the generated data via a novel cross-modal dense retrieval scoring applied to time series-caption pairs. Experimental findings on various time series captioning datasets demonstrate that TSLM outperforms existing state-of-the-art approaches from multiple data modalities by a significant margin.
Increasing Interpretability of Neural Networks By Approximating Human Visual Saliency
Oct 21, 2024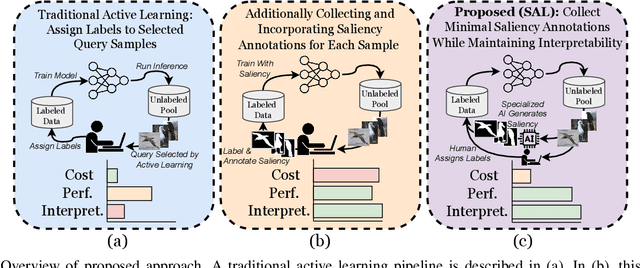

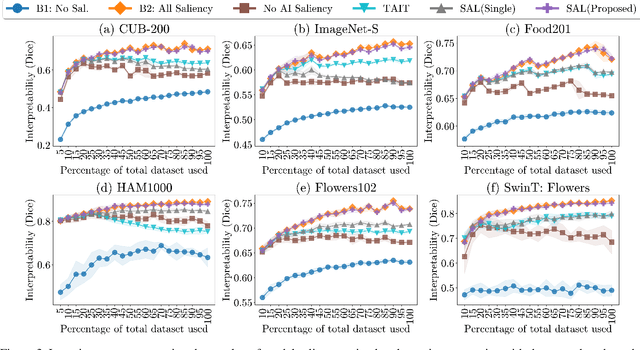
Understanding specifically where a model focuses on within an image is critical for human interpretability of the decision-making process. Deep learning-based solutions are prone to learning coincidental correlations in training datasets, causing over-fitting and reducing the explainability. Recent advances have shown that guiding models to human-defined regions of saliency within individual images significantly increases performance and interpretability. Human-guided models also exhibit greater generalization capabilities, as coincidental dataset features are avoided. Results show that models trained with saliency incorporation display an increase in interpretability of up to 30% over models trained without saliency information. The collection of this saliency information, however, can be costly, laborious and in some cases infeasible. To address this limitation, we propose a combination strategy of saliency incorporation and active learning to reduce the human annotation data required by 80% while maintaining the interpretability and performance increase from human saliency. Extensive experimentation outlines the effectiveness of the proposed approach across five public datasets and six active learning criteria.
Absformer: Transformer-based Model for Unsupervised Multi-Document Abstractive Summarization
Jun 07, 2023

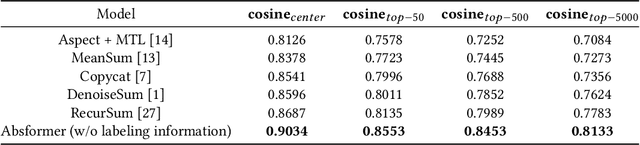
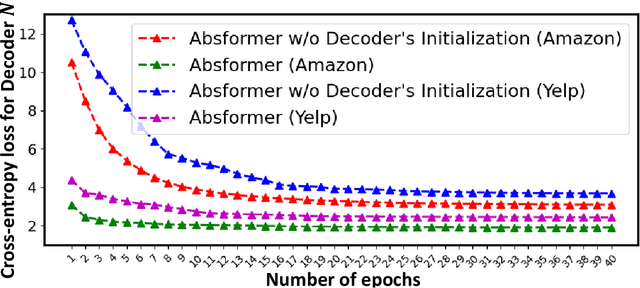
Multi-document summarization (MDS) refers to the task of summarizing the text in multiple documents into a concise summary. The generated summary can save the time of reading many documents by providing the important content in the form of a few sentences. Abstractive MDS aims to generate a coherent and fluent summary for multiple documents using natural language generation techniques. In this paper, we consider the unsupervised abstractive MDS setting where there are only documents with no groundtruh summaries provided, and we propose Absformer, a new Transformer-based method for unsupervised abstractive summary generation. Our method consists of a first step where we pretrain a Transformer-based encoder using the masked language modeling (MLM) objective as the pretraining task in order to cluster the documents into semantically similar groups; and a second step where we train a Transformer-based decoder to generate abstractive summaries for the clusters of documents. To our knowledge, we are the first to successfully incorporate a Transformer-based model to solve the unsupervised abstractive MDS task. We evaluate our approach using three real-world datasets from different domains, and we demonstrate both substantial improvements in terms of evaluation metrics over state-of-the-art abstractive-based methods, and generalization to datasets from different domains.
Augmented Data Science: Towards Industrialization and Democratization of Data Science
Sep 12, 2019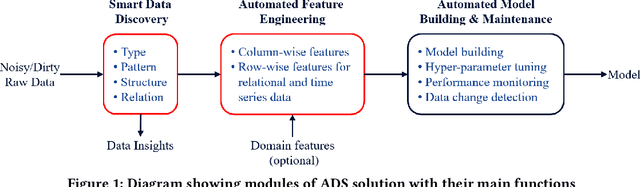

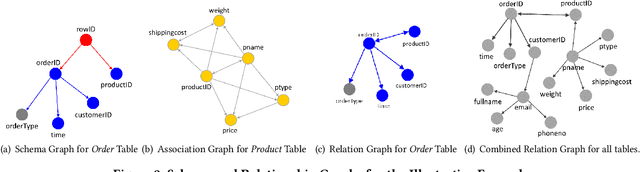
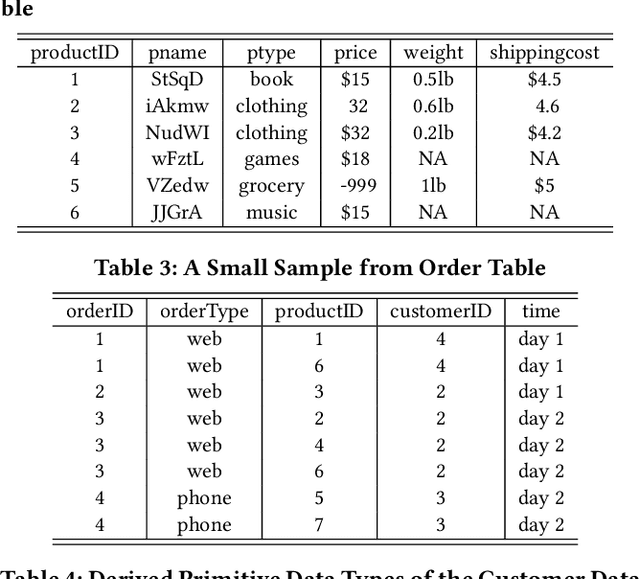
Conversion of raw data into insights and knowledge requires substantial amounts of effort from data scientists. Despite breathtaking advances in Machine Learning (ML) and Artificial Intelligence (AI), data scientists still spend the majority of their effort in understanding and then preparing the raw data for ML/AI. The effort is often manual and ad hoc, and requires some level of domain knowledge. The complexity of the effort increases dramatically when data diversity, both in form and context, increases. In this paper, we introduce our solution, Augmented Data Science (ADS), towards addressing this "human bottleneck" in creating value from diverse datasets. ADS is a data-driven approach and relies on statistics and ML to extract insights from any data set in a domain-agnostic way to facilitate the data science process. Key features of ADS are the replacement of rudimentary data exploration and processing steps with automation and the augmentation of data scientist judgment with automatically-generated insights. We present building blocks of our end-to-end solution and provide a case study to exemplify its capabilities.