 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleDoCTR: Domain-Specific and Contextual Troubleshooting for Telecommunications
Jan 02, 2026Ticket troubleshooting refers to the process of analyzing and resolving problems that are reported through a ticketing system. In large organizations offering a wide range of services, this task is highly complex due to the diversity of submitted tickets and the need for specialized domain knowledge. In particular, troubleshooting in telecommunications (telecom) is a very time-consuming task as it requires experts to interpret ticket content, consult documentation, and search historical records to identify appropriate resolutions. This human-intensive approach not only delays issue resolution but also hinders overall operational efficiency. To enhance the effectiveness and efficiency of ticket troubleshooting in telecom, we propose TeleDoCTR, a novel telecom-related, domain-specific, and contextual troubleshooting system tailored for end-to-end ticket resolution in telecom. TeleDoCTR integrates both domain-specific ranking and generative models to automate key steps of the troubleshooting workflow which are: routing tickets to the appropriate expert team responsible for resolving the ticket (classification task), retrieving contextually and semantically similar historical tickets (retrieval task), and generating a detailed fault analysis report outlining the issue, root cause, and potential solutions (generation task). We evaluate TeleDoCTR on a real-world dataset from a telecom infrastructure and demonstrate that it achieves superior performance over existing state-of-the-art methods, significantly enhancing the accuracy and efficiency of the troubleshooting process.
Time Series Language Model for Descriptive Caption Generation
Jan 03, 2025



The automatic generation of representative natural language descriptions for observable patterns in time series data enhances interpretability, simplifies analysis and increases cross-domain utility of temporal data. While pre-trained foundation models have made considerable progress in natural language processing (NLP) and computer vision (CV), their application to time series analysis has been hindered by data scarcity. Although several large language model (LLM)-based methods have been proposed for time series forecasting, time series captioning is under-explored in the context of LLMs. In this paper, we introduce TSLM, a novel time series language model designed specifically for time series captioning. TSLM operates as an encoder-decoder model, leveraging both text prompts and time series data representations to capture subtle temporal patterns across multiple phases and generate precise textual descriptions of time series inputs. TSLM addresses the data scarcity problem in time series captioning by first leveraging an in-context prompting synthetic data generation, and second denoising the generated data via a novel cross-modal dense retrieval scoring applied to time series-caption pairs. Experimental findings on various time series captioning datasets demonstrate that TSLM outperforms existing state-of-the-art approaches from multiple data modalities by a significant margin.
Increasing Interpretability of Neural Networks By Approximating Human Visual Saliency
Oct 21, 2024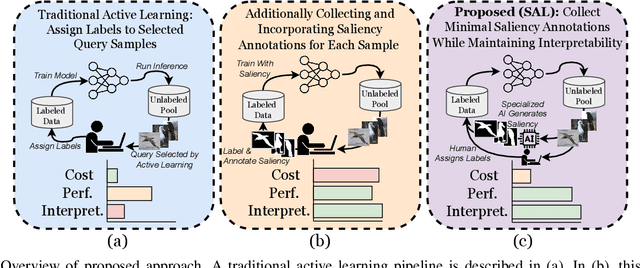
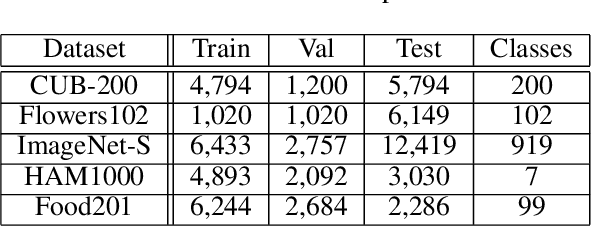

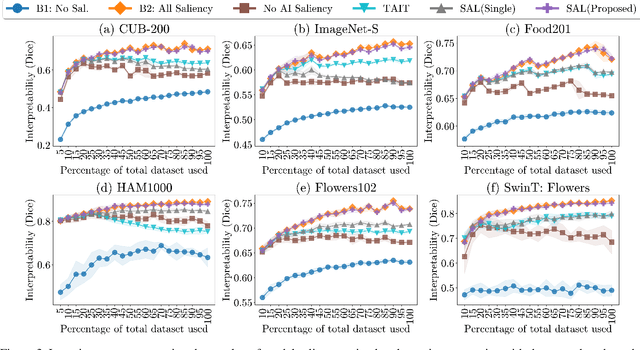
Understanding specifically where a model focuses on within an image is critical for human interpretability of the decision-making process. Deep learning-based solutions are prone to learning coincidental correlations in training datasets, causing over-fitting and reducing the explainability. Recent advances have shown that guiding models to human-defined regions of saliency within individual images significantly increases performance and interpretability. Human-guided models also exhibit greater generalization capabilities, as coincidental dataset features are avoided. Results show that models trained with saliency incorporation display an increase in interpretability of up to 30% over models trained without saliency information. The collection of this saliency information, however, can be costly, laborious and in some cases infeasible. To address this limitation, we propose a combination strategy of saliency incorporation and active learning to reduce the human annotation data required by 80% while maintaining the interpretability and performance increase from human saliency. Extensive experimentation outlines the effectiveness of the proposed approach across five public datasets and six active learning criteria.
LogGPT: Log Anomaly Detection via GPT
Sep 25, 2023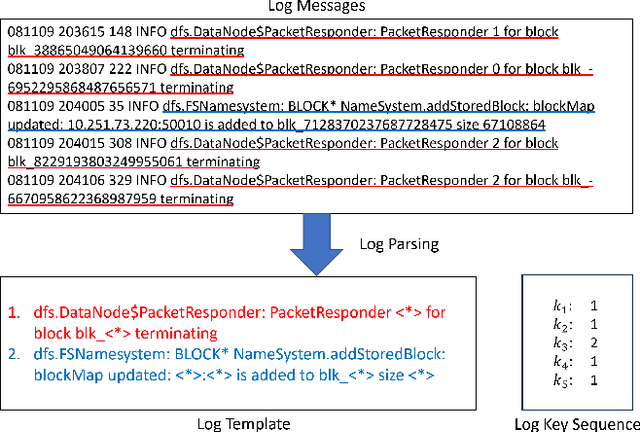
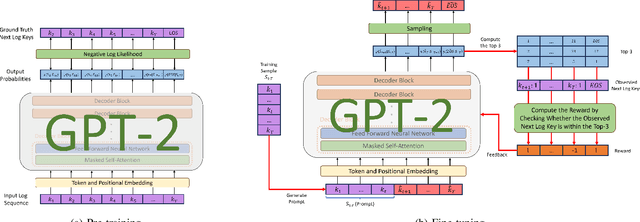
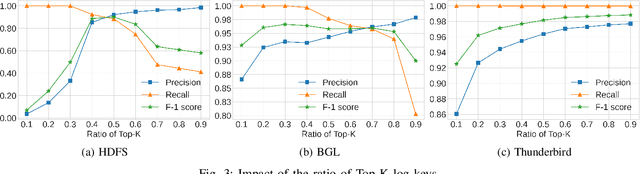
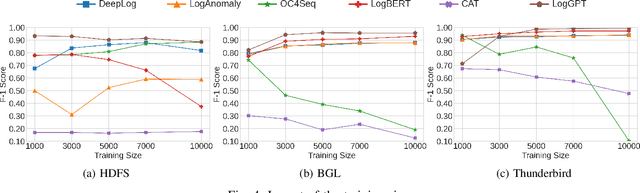
Detecting system anomalies based on log data is important for ensuring the security and reliability of computer systems. Recently, deep learning models have been widely used for log anomaly detection. The core idea is to model the log sequences as natural language and adopt deep sequential models, such as LSTM or Transformer, to encode the normal patterns in log sequences via language modeling. However, there is a gap between language modeling and anomaly detection as the objective of training a sequential model via a language modeling loss is not directly related to anomaly detection. To fill up the gap, we propose LogGPT, a novel framework that employs GPT for log anomaly detection. LogGPT is first trained to predict the next log entry based on the preceding sequence. To further enhance the performance of LogGPT, we propose a novel reinforcement learning strategy to finetune the model specifically for the log anomaly detection task. The experimental results on three datasets show that LogGPT significantly outperforms existing state-of-the-art approaches.
Absformer: Transformer-based Model for Unsupervised Multi-Document Abstractive Summarization
Jun 07, 2023

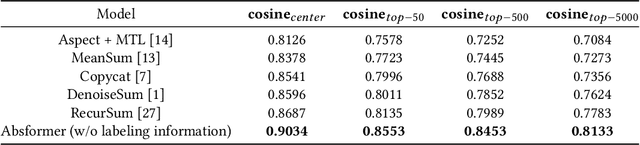
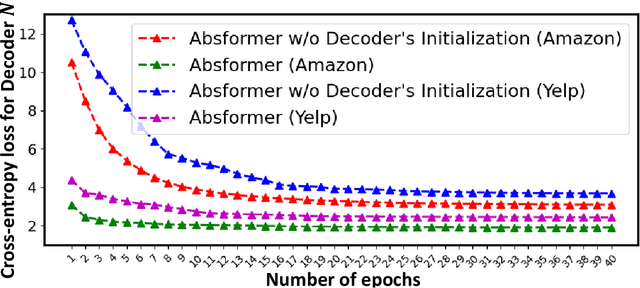
Multi-document summarization (MDS) refers to the task of summarizing the text in multiple documents into a concise summary. The generated summary can save the time of reading many documents by providing the important content in the form of a few sentences. Abstractive MDS aims to generate a coherent and fluent summary for multiple documents using natural language generation techniques. In this paper, we consider the unsupervised abstractive MDS setting where there are only documents with no groundtruh summaries provided, and we propose Absformer, a new Transformer-based method for unsupervised abstractive summary generation. Our method consists of a first step where we pretrain a Transformer-based encoder using the masked language modeling (MLM) objective as the pretraining task in order to cluster the documents into semantically similar groups; and a second step where we train a Transformer-based decoder to generate abstractive summaries for the clusters of documents. To our knowledge, we are the first to successfully incorporate a Transformer-based model to solve the unsupervised abstractive MDS task. We evaluate our approach using three real-world datasets from different domains, and we demonstrate both substantial improvements in terms of evaluation metrics over state-of-the-art abstractive-based methods, and generalization to datasets from different domains.
Time-Frequency Distributions of Heart Sound Signals: A Comparative Study using Convolutional Neural Networks
Aug 05, 2022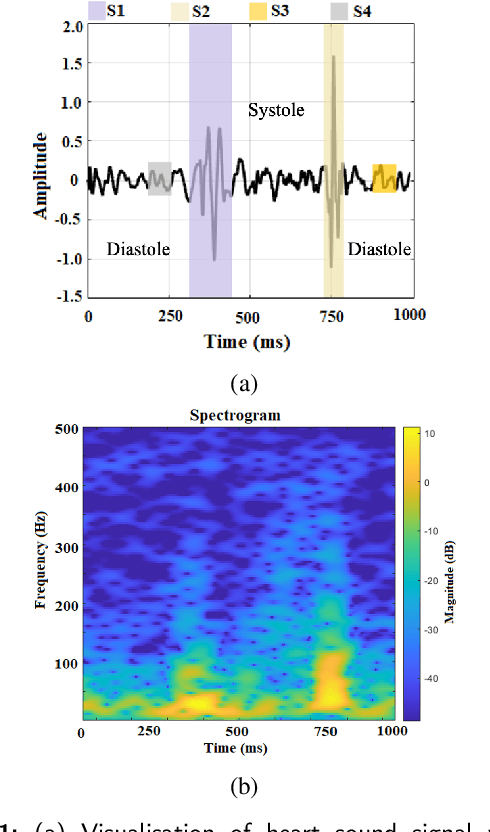
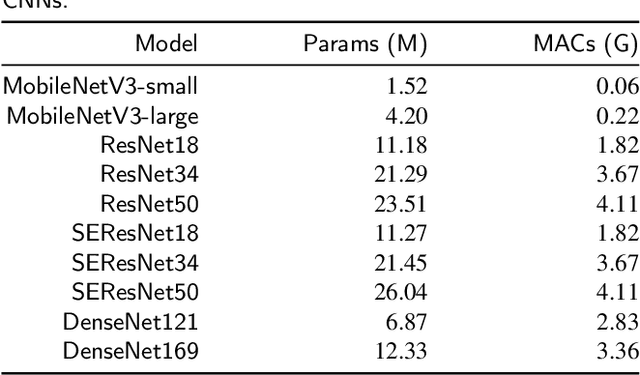
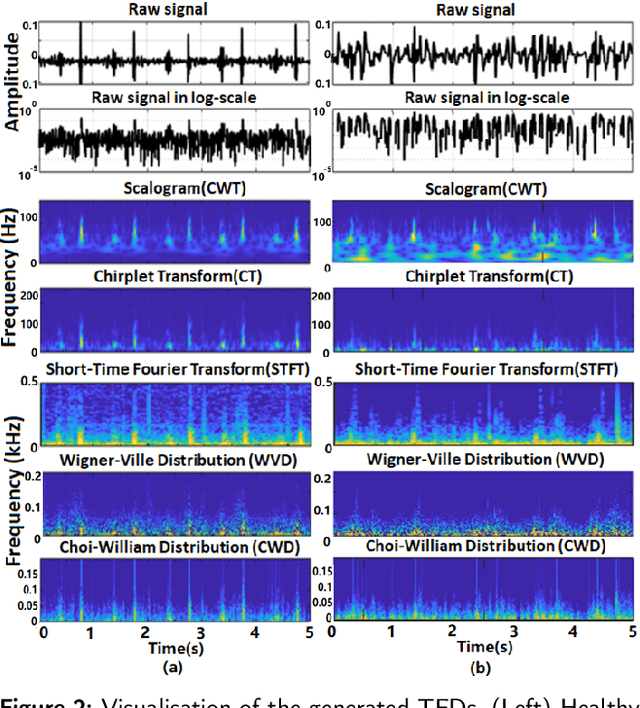

Time-Frequency Distributions (TFDs) support the heart sound characterisation and classification in early cardiac screening. However, despite the frequent use of TFDs in signal analysis, no study comprehensively compared their performances on deep learning for automatic diagnosis. Furthermore, the combination of signal processing methods as inputs for Convolutional Neural Networks (CNNs) has been proved as a practical approach to increasing signal classification performance. Therefore, this study aimed to investigate the optimal use of TFD/ combined TFDs as input for CNNs. The presented results revealed that: 1) The transformation of the heart sound signal into the TF domain achieves higher classification performance than using of raw signals. Among the TFDs, the difference in the performance was slight for all the CNN models (within $1.3\%$ in average accuracy). However, Continuous wavelet transform (CWT) and Chirplet transform (CT) outperformed the rest. 2) The appropriate increase of the CNN capacity and architecture optimisation can improve the performance, while the network architecture should not be overly complicated. Based on the ResNet or SEResNet family results, the increase in the number of parameters and the depth of the structure do not improve the performance apparently. 3) Combining TFDs as CNN inputs did not significantly improve the classification results. The findings of this study provided the knowledge for selecting TFDs as CNN input and designing CNN architecture for heart sound classification.
DAME: Domain Adaptation for Matching Entities
Apr 20, 2022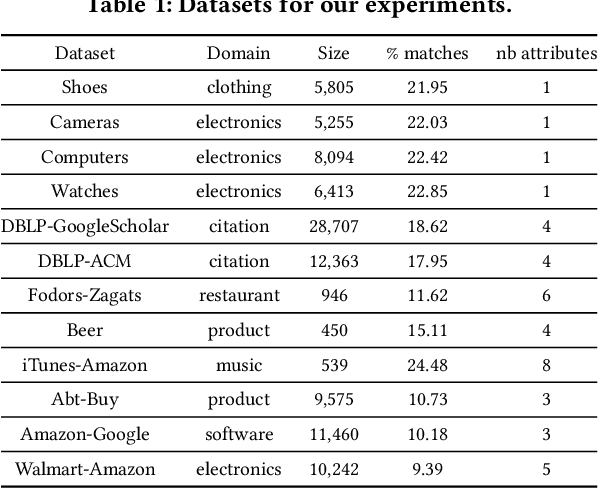
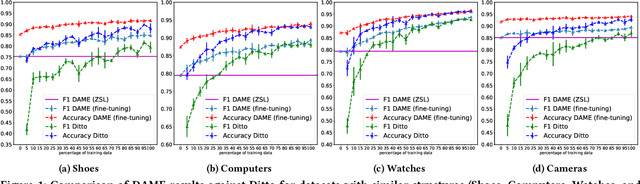

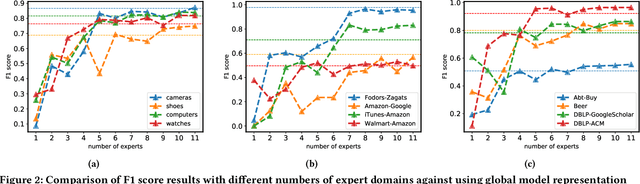
Entity matching (EM) identifies data records that refer to the same real-world entity. Despite the effort in the past years to improve the performance in EM, the existing methods still require a huge amount of labeled data in each domain during the training phase. These methods treat each domain individually, and capture the specific signals for each dataset in EM, and this leads to overfitting on just one dataset. The knowledge that is learned from one dataset is not utilized to better understand the EM task in order to make predictions on the unseen datasets with fewer labeled samples. In this paper, we propose a new domain adaptation-based method that transfers the task knowledge from multiple source domains to a target domain. Our method presents a new setting for EM where the objective is to capture the task-specific knowledge from pretraining our model using multiple source domains, then testing our model on a target domain. We study the zero-shot learning case on the target domain, and demonstrate that our method learns the EM task and transfers knowledge to the target domain. We extensively study fine-tuning our model on the target dataset from multiple domains, and demonstrate that our model generalizes better than state-of-the-art methods in EM.
StruBERT: Structure-aware BERT for Table Search and Matching
Mar 27, 2022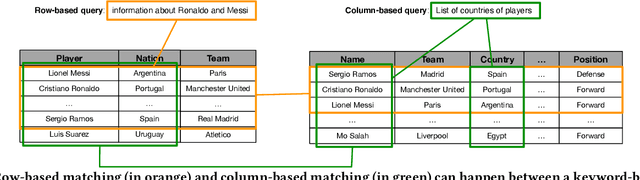
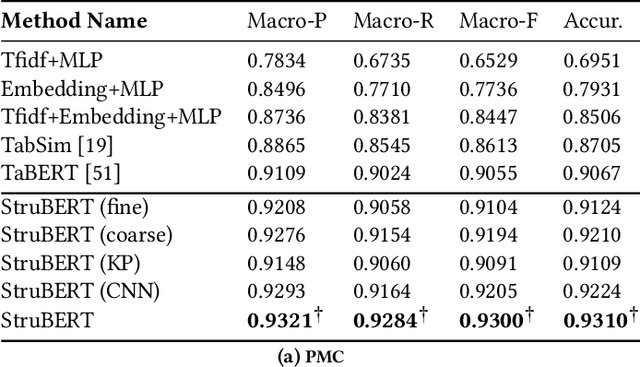
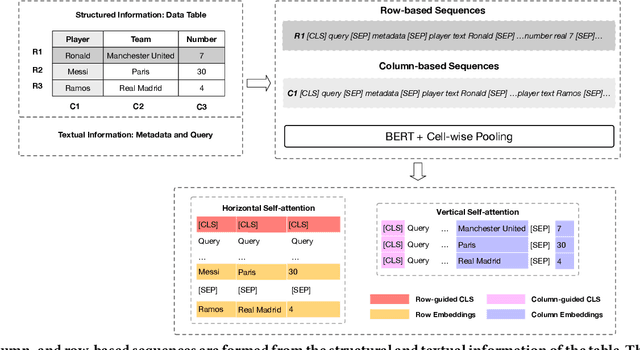
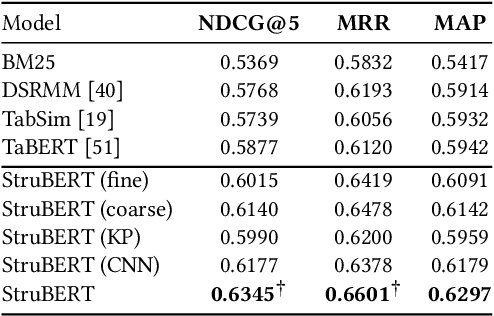
A large amount of information is stored in data tables. Users can search for data tables using a keyword-based query. A table is composed primarily of data values that are organized in rows and columns providing implicit structural information. A table is usually accompanied by secondary information such as the caption, page title, etc., that form the textual information. Understanding the connection between the textual and structural information is an important yet neglected aspect in table retrieval as previous methods treat each source of information independently. In addition, users can search for data tables that are similar to an existing table, and this setting can be seen as a content-based table retrieval. In this paper, we propose StruBERT, a structure-aware BERT model that fuses the textual and structural information of a data table to produce context-aware representations for both textual and tabular content of a data table. StruBERT features are integrated in a new end-to-end neural ranking model to solve three table-related downstream tasks: keyword- and content-based table retrieval, and table similarity. We evaluate our approach using three datasets, and we demonstrate substantial improvements in terms of retrieval and classification metrics over state-of-the-art methods.
Neural Ranking Models for Document Retrieval
Feb 23, 2021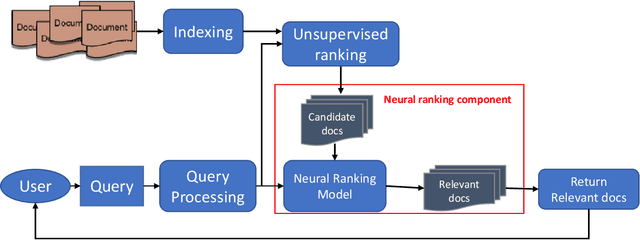
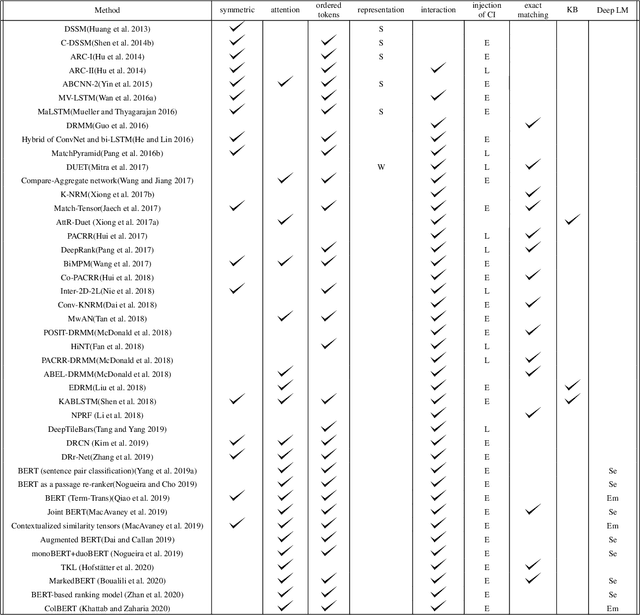
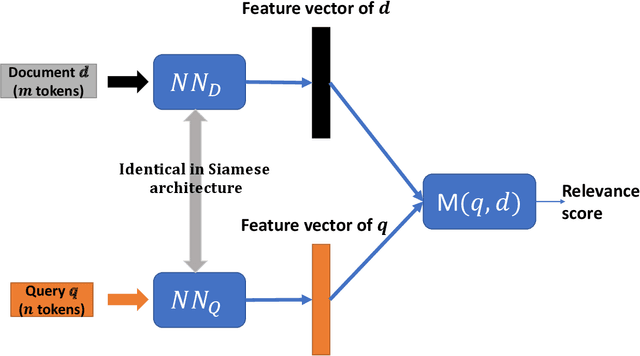
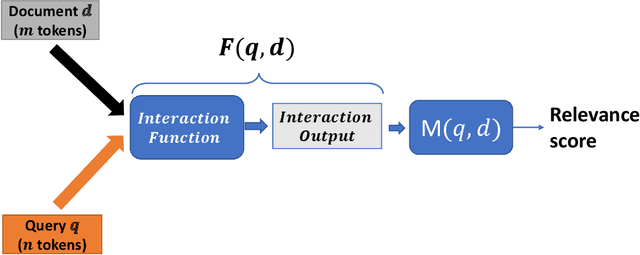
Ranking models are the main components of information retrieval systems. Several approaches to ranking are based on traditional machine learning algorithms using a set of hand-crafted features. Recently, researchers have leveraged deep learning models in information retrieval. These models are trained end-to-end to extract features from the raw data for ranking tasks, so that they overcome the limitations of hand-crafted features. A variety of deep learning models have been proposed, and each model presents a set of neural network components to extract features that are used for ranking. In this paper, we compare the proposed models in the literature along different dimensions in order to understand the major contributions and limitations of each model. In our discussion of the literature, we analyze the promising neural components, and propose future research directions. We also show the analogy between document retrieval and other retrieval tasks where the items to be ranked are structured documents, answers, images and videos.
Semantic Labeling Using a Deep Contextualized Language Model
Oct 30, 2020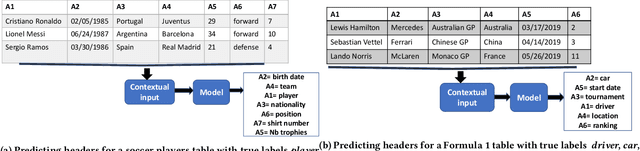

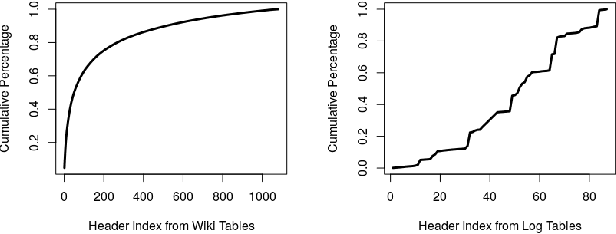
Generating schema labels automatically for column values of data tables has many data science applications such as schema matching, and data discovery and linking. For example, automatically extracted tables with missing headers can be filled by the predicted schema labels which significantly minimizes human effort. Furthermore, the predicted labels can reduce the impact of inconsistent names across multiple data tables. Understanding the connection between column values and contextual information is an important yet neglected aspect as previously proposed methods treat each column independently. In this paper, we propose a context-aware semantic labeling method using both the column values and context. Our new method is based on a new setting for semantic labeling, where we sequentially predict labels for an input table with missing headers. We incorporate both the values and context of each data column using the pre-trained contextualized language model, BERT, that has achieved significant improvements in multiple natural language processing tasks. To our knowledge, we are the first to successfully apply BERT to solve the semantic labeling task. We evaluate our approach using two real-world datasets from different domains, and we demonstrate substantial improvements in terms of evaluation metrics over state-of-the-art feature-based methods.