 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAME: Domain Adaptation for Matching Entities
Apr 20, 2022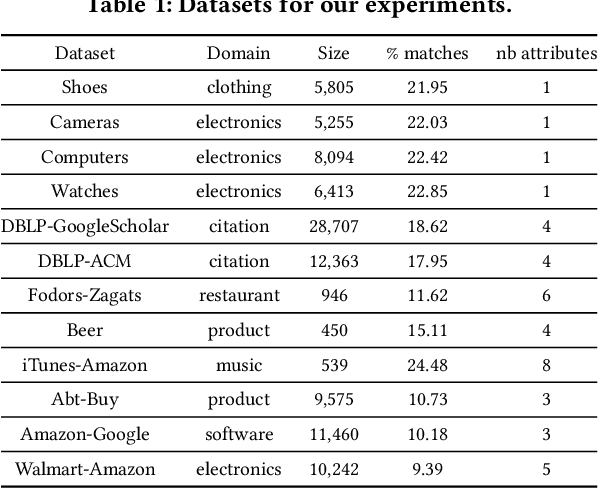
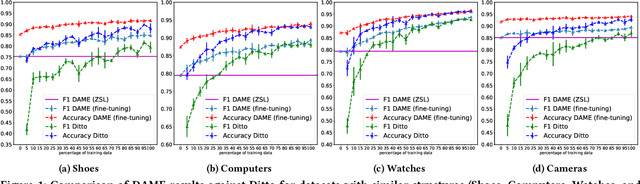

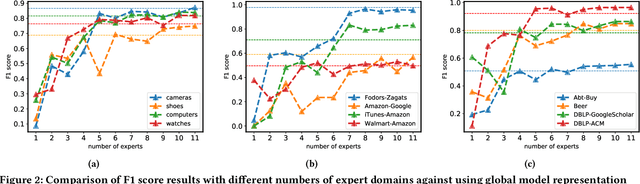
Entity matching (EM) identifies data records that refer to the same real-world entity. Despite the effort in the past years to improve the performance in EM, the existing methods still require a huge amount of labeled data in each domain during the training phase. These methods treat each domain individually, and capture the specific signals for each dataset in EM, and this leads to overfitting on just one dataset. The knowledge that is learned from one dataset is not utilized to better understand the EM task in order to make predictions on the unseen datasets with fewer labeled samples. In this paper, we propose a new domain adaptation-based method that transfers the task knowledge from multiple source domains to a target domain. Our method presents a new setting for EM where the objective is to capture the task-specific knowledge from pretraining our model using multiple source domains, then testing our model on a target domain. We study the zero-shot learning case on the target domain, and demonstrate that our method learns the EM task and transfers knowledge to the target domain. We extensively study fine-tuning our model on the target dataset from multiple domains, and demonstrate that our model generalizes better than state-of-the-art methods in EM.
StruBERT: Structure-aware BERT for Table Search and Matching
Mar 27, 2022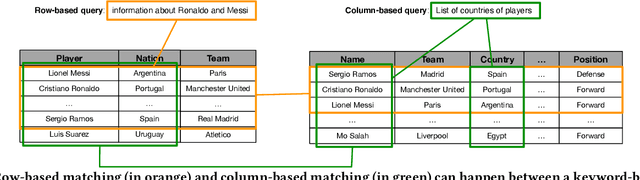
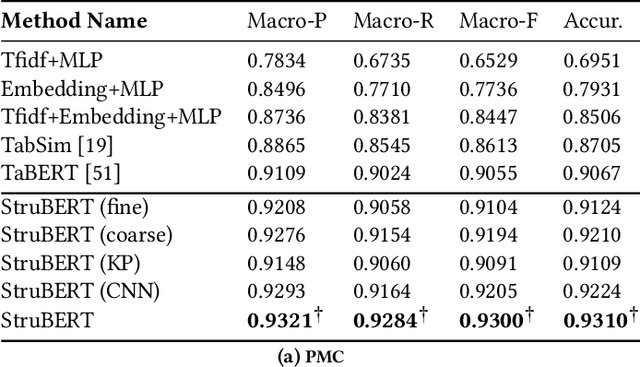
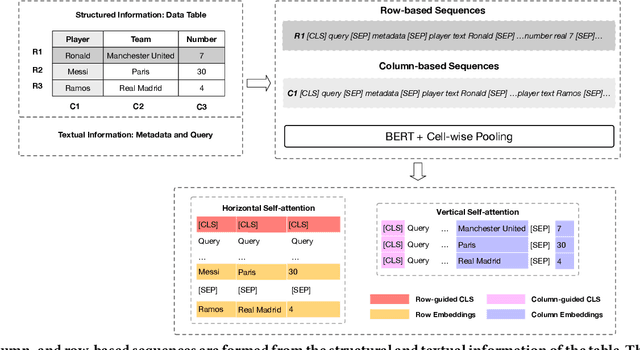
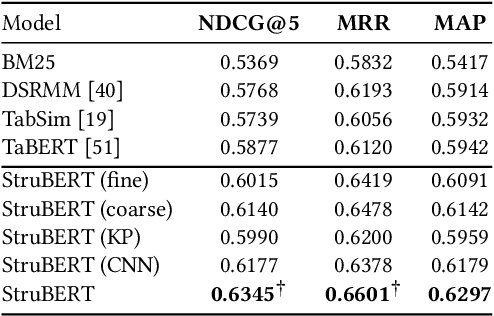
A large amount of information is stored in data tables. Users can search for data tables using a keyword-based query. A table is composed primarily of data values that are organized in rows and columns providing implicit structural information. A table is usually accompanied by secondary information such as the caption, page title, etc., that form the textual information. Understanding the connection between the textual and structural information is an important yet neglected aspect in table retrieval as previous methods treat each source of information independently. In addition, users can search for data tables that are similar to an existing table, and this setting can be seen as a content-based table retrieval. In this paper, we propose StruBERT, a structure-aware BERT model that fuses the textual and structural information of a data table to produce context-aware representations for both textual and tabular content of a data table. StruBERT features are integrated in a new end-to-end neural ranking model to solve three table-related downstream tasks: keyword- and content-based table retrieval, and table similarity. We evaluate our approach using three datasets, and we demonstrate substantial improvements in terms of retrieval and classification metrics over state-of-the-art methods.
Neural Ranking Models for Document Retrieval
Feb 23, 2021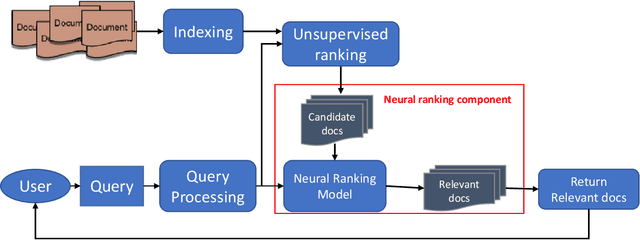
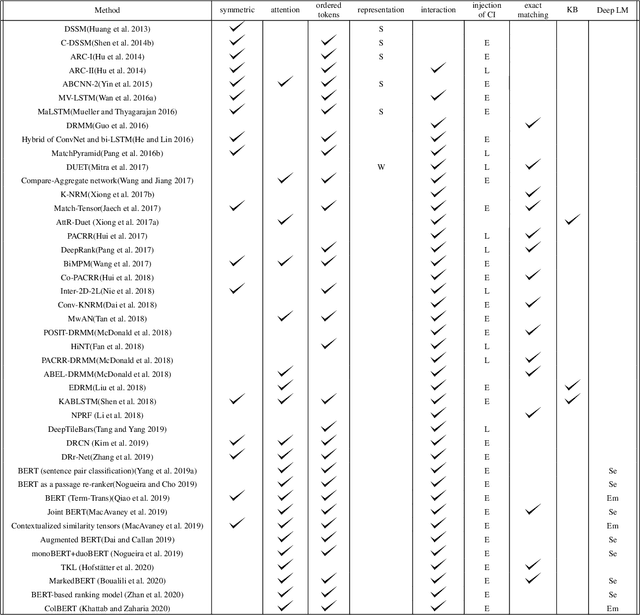
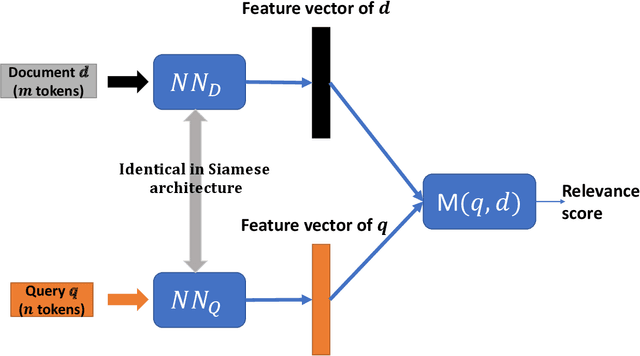
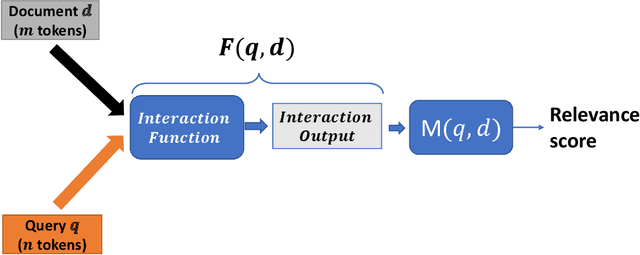
Ranking models are the main components of information retrieval systems. Several approaches to ranking are based on traditional machine learning algorithms using a set of hand-crafted features. Recently, researchers have leveraged deep learning models in information retrieval. These models are trained end-to-end to extract features from the raw data for ranking tasks, so that they overcome the limitations of hand-crafted features. A variety of deep learning models have been proposed, and each model presents a set of neural network components to extract features that are used for ranking. In this paper, we compare the proposed models in the literature along different dimensions in order to understand the major contributions and limitations of each model. In our discussion of the literature, we analyze the promising neural components, and propose future research directions. We also show the analogy between document retrieval and other retrieval tasks where the items to be ranked are structured documents, answers, images and videos.
Semantic Labeling Using a Deep Contextualized Language Model
Oct 30, 2020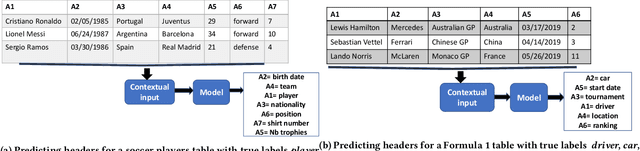

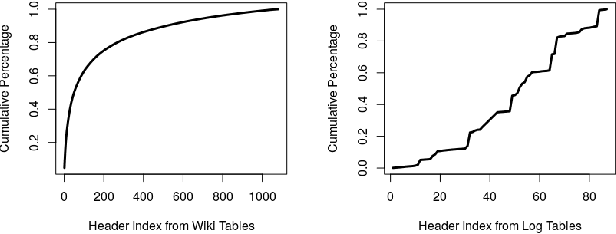
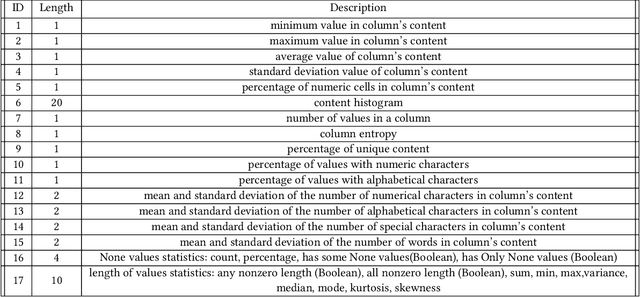
Generating schema labels automatically for column values of data tables has many data science applications such as schema matching, and data discovery and linking. For example, automatically extracted tables with missing headers can be filled by the predicted schema labels which significantly minimizes human effort. Furthermore, the predicted labels can reduce the impact of inconsistent names across multiple data tables. Understanding the connection between column values and contextual information is an important yet neglected aspect as previously proposed methods treat each column independently. In this paper, we propose a context-aware semantic labeling method using both the column values and context. Our new method is based on a new setting for semantic labeling, where we sequentially predict labels for an input table with missing headers. We incorporate both the values and context of each data column using the pre-trained contextualized language model, BERT, that has achieved significant improvements in multiple natural language processing tasks. To our knowledge, we are the first to successfully apply BERT to solve the semantic labeling task. We evaluate our approach using two real-world datasets from different domains, and we demonstrate substantial improvements in terms of evaluation metrics over state-of-the-art feature-based methods.
Table Search Using a Deep Contextualized Language Model
May 26, 2020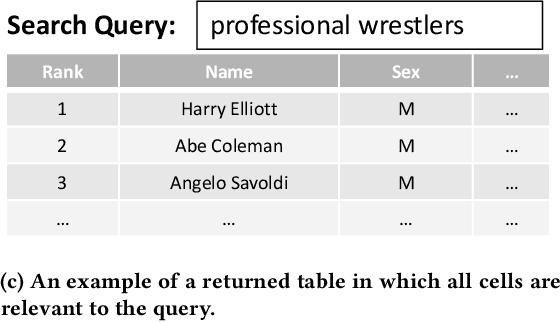
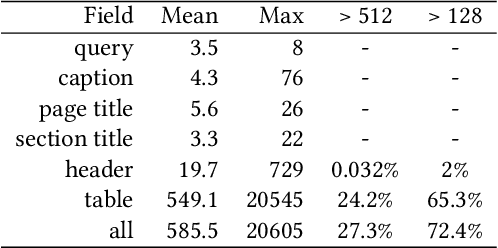
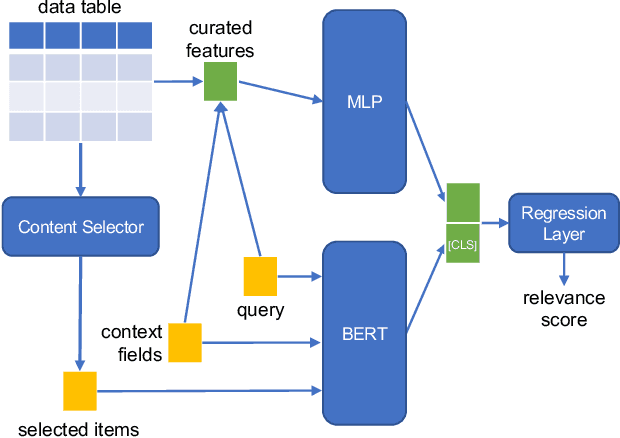

Pretrained contextualized language models such as BERT have achieved impressive results on various natural language processing benchmarks. Benefiting from multiple pretraining tasks and large scale training corpora, pretrained models can capture complex syntactic word relations. In this paper, we use the deep contextualized language model BERT for the task of ad hoc table retrieval. We investigate how to encode table content considering the table structure and input length limit of BERT. We also propose an approach that incorporates features from prior literature on table retrieval and jointly trains them with BERT. In experiments on public datasets, we show that our best approach can outperform the previous state-of-the-art method and BERT baselines with a large margin under different evaluation metrics.
Leveraging Schema Labels to Enhance Dataset Search
Jan 27, 2020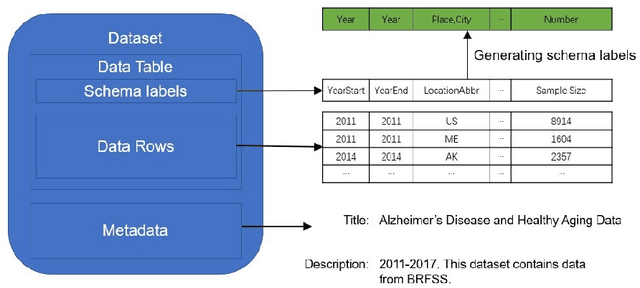
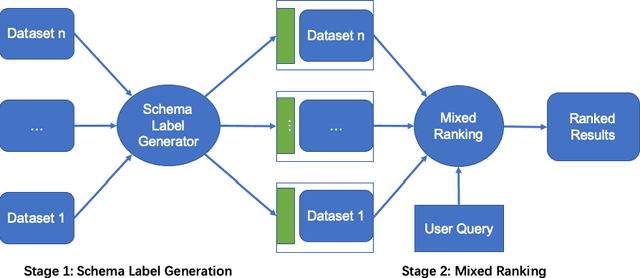
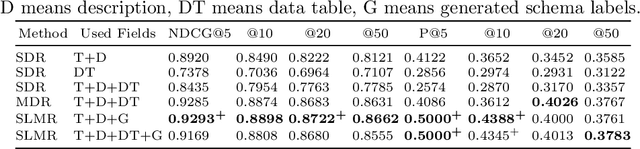
A search engine's ability to retrieve desirable datasets is important for data sharing and reuse. Existing dataset search engines typically rely on matching queries to dataset descriptions. However, a user may not have enough prior knowledge to write a query using terms that match with description text.We propose a novel schema label generation model which generates possible schema labels based on dataset table content. We incorporate the generated schema labels into a mixed ranking model which not only considers the relevance between the query and dataset metadata but also the similarity between the query and generated schema labels. To evaluate our method on real-world datasets, we create a new benchmark specifically for the dataset retrieval task. Experiments show that our approach can effectively improve the precision and NDCG scores of the dataset retrieval task compared with baseline methods. We also test on a collection of Wikipedia tables to show that the features generated from schema labels can improve the unsupervised and supervised web table retrieval task as well.