 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Time Clustering for High Dimensional Mixtures of Gaussian Clouds
Paper and Code
Mar 01, 2018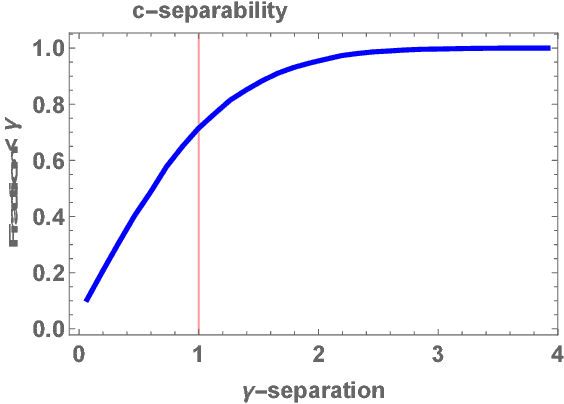

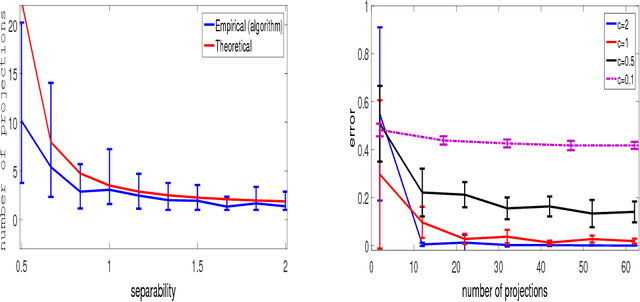
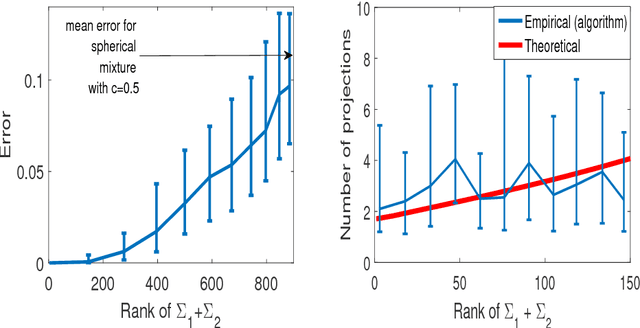
Clustering mixtures of Gaussian distributions is a fundamental and challenging problem that is ubiquitous in various high-dimensional data processing tasks. While state-of-the-art work on learning Gaussian mixture models has focused primarily on improving separation bounds and their generalization to arbitrary classes of mixture models, less emphasis has been paid to practical computational efficiency of the proposed solutions. In this paper, we propose a novel and highly efficient clustering algorithm for $n$ points drawn from a mixture of two arbitrary Gaussian distributions in $\mathbb{R}^p$. The algorithm involves performing random 1-dimensional projections until a direction is found that yields a user-specified clustering error $e$. For a 1-dimensional separation parameter $\gamma$ satisfying $\gamma=Q^{-1}(e)$, the expected number of such projections is shown to be bounded by $o(\ln p)$, when $\gamma$ satisfies $\gamma\leq c\sqrt{\ln{\ln{p}}}$, with $c$ as the separability parameter of the two Gaussians in $\mathbb{R}^p$. Consequently, the expected overall running time of the algorithm is linear in $n$ and quasi-linear in $p$ at $o(\ln{p})O(np)$, and the sample complexity is independent of $p$. This result stands in contrast to prior works which provide polynomial, with at-best quadratic, running time in $p$ and $n$. We show that our bound on the expected number of 1-dimensional projections extends to the case of three or more Gaussian components, and we present a generalization of our results to mixture distributions beyond the Gaussian model.