 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deep Learning of GMMs
Feb 15, 2019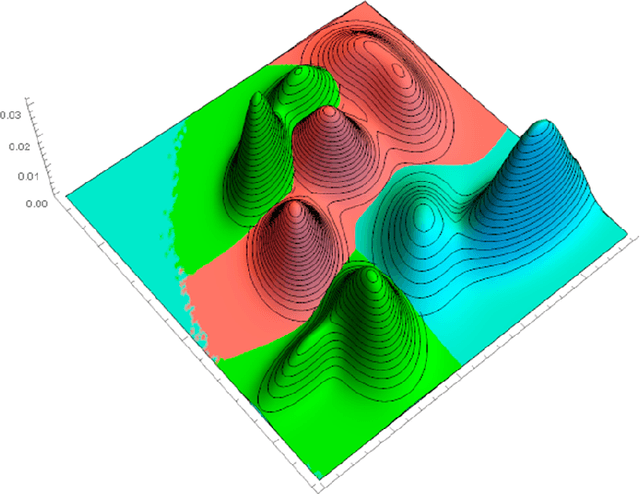
We show that a collection of Gaussian mixture models (GMMs) in $R^{n}$ can be optimally classified using $O(n)$ neurons in a neural network with two hidden layers (deep neural network), whereas in contrast, a neural network with a single hidden layer (shallow neural network) would require at least $O(\exp(n))$ neurons or possibly exponentially large coefficients. Given the universality of the Gaussian distribution in the feature spaces of data, e.g., in speech, image and text, our result sheds light on the observed efficiency of deep neural networks in practical classification problems.
Linear Time Clustering for High Dimensional Mixtures of Gaussian Clouds
Mar 01, 2018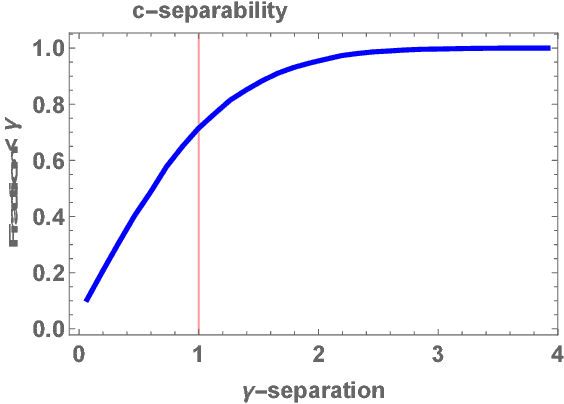

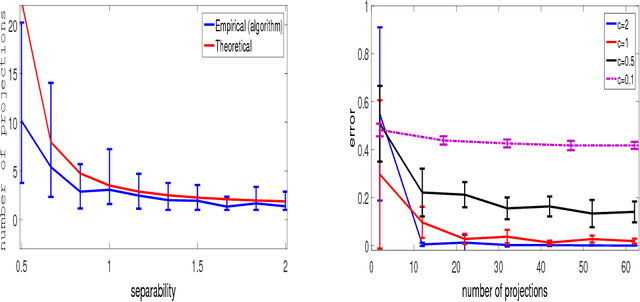
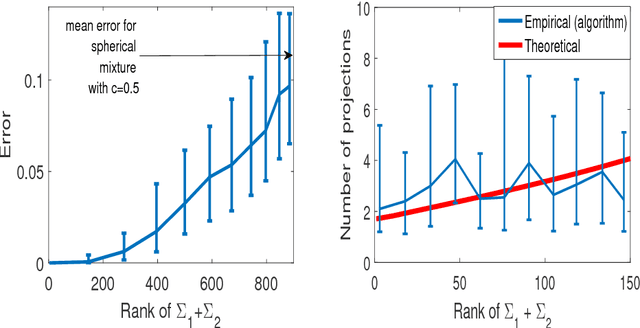
Clustering mixtures of Gaussian distributions is a fundamental and challenging problem that is ubiquitous in various high-dimensional data processing tasks. While state-of-the-art work on learning Gaussian mixture models has focused primarily on improving separation bounds and their generalization to arbitrary classes of mixture models, less emphasis has been paid to practical computational efficiency of the proposed solutions. In this paper, we propose a novel and highly efficient clustering algorithm for $n$ points drawn from a mixture of two arbitrary Gaussian distributions in $\mathbb{R}^p$. The algorithm involves performing random 1-dimensional projections until a direction is found that yields a user-specified clustering error $e$. For a 1-dimensional separation parameter $\gamma$ satisfying $\gamma=Q^{-1}(e)$, the expected number of such projections is shown to be bounded by $o(\ln p)$, when $\gamma$ satisfies $\gamma\leq c\sqrt{\ln{\ln{p}}}$, with $c$ as the separability parameter of the two Gaussians in $\mathbb{R}^p$. Consequently, the expected overall running time of the algorithm is linear in $n$ and quasi-linear in $p$ at $o(\ln{p})O(np)$, and the sample complexity is independent of $p$. This result stands in contrast to prior works which provide polynomial, with at-best quadratic, running time in $p$ and $n$. We show that our bound on the expected number of 1-dimensional projections extends to the case of three or more Gaussian components, and we present a generalization of our results to mixture distributions beyond the Gaussian model.
A New Family of Near-metrics for Universal Similarity
Oct 17, 2017



We propose a family of near-metrics based on local graph diffusion to capture similarity for a wide class of data sets. These quasi-metametrics, as their names suggest, dispense with one or two standard axioms of metric spaces, specifically distinguishability and symmetry, so that similarity between data points of arbitrary type and form could be measured broadly and effectively. The proposed near-metric family includes the forward k-step diffusion and its reverse, typically on the graph consisting of data objects and their features. By construction, this family of near-metrics is particularly appropriate for categorical data, continuous data, and vector representations of images and text extracted via deep learning approaches. We conduct extensive experiments to evaluate the performance of this family of similarity measures and compare and contrast with traditional measures of similarity used for each specific application and with the ground truth when available. We show that for structured data including categorical and continuous data, the near-metrics corresponding to normalized forward k-step diffusion (k small) work as one of the best performing similarity measures; for vector representations of text and images including those extracted from deep learning, the near-metrics derived from normalized and reverse k-step graph diffusion (k very small) exhibit outstanding ability to distinguish data points from different classes.