 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot denoising via neural compression: Theoretical and algorithmic framework
Jun 15, 2025Zero-shot denoising aims to denoise observations without access to training samples or clean reference images. This setting is particularly relevant in practical imaging scenarios involving specialized domains such as medical imaging or biology. In this work, we propose the Zero-Shot Neural Compression Denoiser (ZS-NCD), a novel denoising framework based on neural compression. ZS-NCD treats a neural compression network as an untrained model, optimized directly on patches extracted from a single noisy image. The final reconstruction is then obtained by aggregating the outputs of the trained model over overlapping patches. Thanks to the built-in entropy constraints of compression architectures, our method naturally avoids overfitting and does not require manual regularization or early stopping. Through extensive experiments, we show that ZS-NCD achieves state-of-the-art performance among zero-shot denoisers for both Gaussian and Poisson noise, and generalizes well to both natural and non-natural images. Additionally, we provide new finite-sample theoretical results that characterize upper bounds on the achievable reconstruction error of general maximum-likelihood compression-based denoisers. These results further establish the theoretical foundations of compression-based denoising. Our code is available at: github.com/Computational-Imaging-RU/ZS-NCDenoiser.
Multilook Coherent Imaging: Theoretical Guarantees and Algorithms
May 29, 2025Multilook coherent imaging is a widely used technique in applications such as digital holography, ultrasound imaging, and synthetic aperture radar. A central challenge in these systems is the presence of multiplicative noise, commonly known as speckle, which degrades image quality. Despite the widespread use of coherent imaging systems, their theoretical foundations remain relatively underexplored. In this paper, we study both the theoretical and algorithmic aspects of likelihood-based approaches for multilook coherent imaging, providing a rigorous framework for analysis and method development. Our theoretical contributions include establishing the first theoretical upper bound on the Mean Squared Error (MSE) of the maximum likelihood estimator under the deep image prior hypothesis. Our results capture the dependence of MSE on the number of parameters in the deep image prior, the number of looks, the signal dimension, and the number of measurements per look. On the algorithmic side, we employ projected gradient descent (PGD) as an efficient method for computing the maximum likelihood solution. Furthermore, we introduce two key ideas to enhance the practical performance of PGD. First, we incorporate the Newton-Schulz algorithm to compute matrix inverses within the PGD iterations, significantly reducing computational complexity. Second, we develop a bagging strategy to mitigate projection errors introduced during PGD updates. We demonstrate that combining these techniques with PGD yields state-of-the-art performance. Our code is available at https://github.com/Computational-Imaging-RU/Bagged-DIP-Speckle.
DeCompress: Denoising via Neural Compression
Mar 27, 2025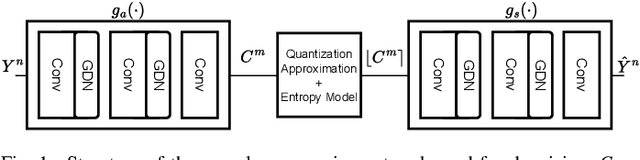



Learning-based denoising algorithms achieve state-of-the-art performance across various denoising tasks. However, training such models relies on access to large training datasets consisting of clean and noisy image pairs. On the other hand, in many imaging applications, such as microscopy, collecting ground truth images is often infeasible. To address this challenge, researchers have recently developed algorithms that can be trained without requiring access to ground truth data. However, training such models remains computationally challenging and still requires access to large noisy training samples. In this work, inspired by compression-based denoising and recent advances in neural compression, we propose a new compression-based denoising algorithm, which we name DeCompress, that i) does not require access to ground truth images, ii) does not require access to large training dataset - only a single noisy image is sufficient, iii) is robust to overfitting, and iv) achieves superior performance compared with zero-shot or unsupervised learning-based denoisers.
Bayesian Despeckling of Structured Sources
Jan 21, 2025Speckle noise is a fundamental challenge in coherent imaging systems, significantly degrading image quality. Over the past decades, numerous despeckling algorithms have been developed for applications such as Synthetic Aperture Radar (SAR) and digital holography. In this paper, we aim to establish a theoretically grounded approach to despeckling. We propose a method applicable to general structured stationary stochastic sources. We demonstrate the effectiveness of the proposed method on piecewise constant sources. Additionally, we theoretically derive a lower bound on the despeckling performance for such sources. The proposed depseckler applied to the 1-Markov structured sources achieves better reconstruction performance with no strong simplification of the ground truth signal model or speckle noise.
Saturation in Snapshot Compressive Imaging
Jan 21, 2025Snapshot Compressive Imaging (SCI) maps three-dimensional (3D) data cubes, such as videos or hyperspectral images, into two-dimensional (2D) measurements via optical modulation, enabling efficient data acquisition and reconstruction. Recent advances have shown the potential of mask optimization to enhance SCI performance, but most studies overlook nonlinear distortions caused by saturation in practical systems. Saturation occurs when high-intensity measurements exceed the sensor's dynamic range, leading to information loss that standard reconstruction algorithms cannot fully recover. This paper addresses the challenge of optimizing binary masks in SCI under saturation. We theoretically characterize the performance of compression-based SCI recovery in the presence of saturation and leverage these insights to optimize masks for such conditions. Our analysis reveals trade-offs between mask statistics and reconstruction quality in saturated systems. Experimental results using a Plug-and-Play (PnP) style network validate the theory, demonstrating improved recovery performance and robustness to saturation with our optimized binary masks.
Theoretical Characterization of Effect of Masks in Snapshot Compressive Imaging
Jan 11, 2025



Snapshot compressive imaging (SCI) refers to the recovery of three-dimensional data cubes-such as videos or hyperspectral images-from their two-dimensional projections, which are generated by a special encoding of the data with a mask. SCI systems commonly use binary-valued masks that follow certain physical constraints. Optimizing these masks subject to these constraints is expected to improve system performance. However, prior theoretical work on SCI systems focuses solely on independently and identically distributed (i.i.d.) Gaussian masks, which do not permit such optimization. On the other hand, existing practical mask optimizations rely on computationally intensive joint optimizations that provide limited insight into the role of masks and are expected to be sub-optimal due to the non-convexity and complexity of the optimization. In this paper, we analytically characterize the performance of SCI systems employing binary masks and leverage our analysis to optimize hardware parameters. Our findings provide a comprehensive and fundamental understanding of the role of binary masks - with both independent and dependent elements - and their optimization. We also present simulation results that confirm our theoretical findings and further illuminate different aspects of mask design.
Comprehensive Examination of Unrolled Networks for Linear Inverse Problems
Jan 08, 2025



Unrolled networks have become prevalent in various computer vision and imaging tasks. Although they have demonstrated remarkable efficacy in solving specific computer vision and computational imaging tasks, their adaptation to other applications presents considerable challenges. This is primarily due to the multitude of design decisions that practitioners working on new applications must navigate, each potentially affecting the network's overall performance. These decisions include selecting the optimization algorithm, defining the loss function, and determining the number of convolutional layers, among others. Compounding the issue, evaluating each design choice requires time-consuming simulations to train, fine-tune the neural network, and optimize for its performance. As a result, the process of exploring multiple options and identifying the optimal configuration becomes time-consuming and computationally demanding. The main objectives of this paper are (1) to unify some ideas and methodologies used in unrolled networks to reduce the number of design choices a user has to make, and (2) to report a comprehensive ablation study to discuss the impact of each of the choices involved in designing unrolled networks and present practical recommendations based on our findings. We anticipate that this study will help scientists and engineers design unrolled networks for their applications and diagnose problems within their networks efficiently.
Untrained Neural Nets for Snapshot Compressive Imaging: Theory and Algorithms
Jun 06, 2024



Snapshot compressive imaging (SCI) recovers high-dimensional (3D) data cubes from a single 2D measurement, enabling diverse applications like video and hyperspectral imaging to go beyond standard techniques in terms of acquisition speed and efficiency. In this paper, we focus on SCI recovery algorithms that employ untrained neural networks (UNNs), such as deep image prior (DIP), to model source structure. Such UNN-based methods are appealing as they have the potential of avoiding the computationally intensive retraining required for different source models and different measurement scenarios. We first develop a theoretical framework for characterizing the performance of such UNN-based methods. The theoretical framework, on the one hand, enables us to optimize the parameters of data-modulating masks, and on the other hand, provides a fundamental connection between the number of data frames that can be recovered from a single measurement to the parameters of the untrained NN. We also employ the recently proposed bagged-deep-image-prior (bagged-DIP) idea to develop SCI Bagged Deep Video Prior (SCI-BDVP) algorithms that address the common challenges faced by standard UNN solutions. Our experimental results show that in video SCI our proposed solution achieves state-of-the-art among UNN methods, and in the case of noisy measurements, it even outperforms supervised solutions.
Bagged Deep Image Prior for Recovering Images in the Presence of Speckle Noise
Feb 23, 2024



We investigate both the theoretical and algorithmic aspects of likelihood-based methods for recovering a complex-valued signal from multiple sets of measurements, referred to as looks, affected by speckle (multiplicative) noise. Our theoretical contributions include establishing the first existing theoretical upper bound on the Mean Squared Error (MSE) of the maximum likelihood estimator under the deep image prior hypothesis. Our theoretical results capture the dependence of MSE upon the number of parameters in the deep image prior, the number of looks, the signal dimension, and the number of measurements per look. On the algorithmic side, we introduce the concept of bagged Deep Image Priors (Bagged-DIP) and integrate them with projected gradient descent. Furthermore, we show how employing Newton-Schulz algorithm for calculating matrix inverses within the iterations of PGD reduces the computational complexity of the algorithm. We will show that this method achieves the state-of-the-art performance.
Theoretical Analysis of Binary Masks in Snapshot Compressive Imaging Systems
Jul 15, 2023

Snapshot compressive imaging (SCI) systems have gained significant attention in recent years. While previous theoretical studies have primarily focused on the performance analysis of Gaussian masks, practical SCI systems often employ binary-valued masks. Furthermore, recent research has demonstrated that optimized binary masks can significantly enhance system performance. In this paper, we present a comprehensive theoretical characterization of binary masks and their impact on SCI system performance. Initially, we investigate the scenario where the masks are binary and independently identically distributed (iid), revealing a noteworthy finding that aligns with prior numerical results. Specifically, we show that the optimal probability of non-zero elements in the masks is smaller than 0.5. This result provides valuable insights into the design and optimization of binary masks for SCI systems, facilitating further advancements in the field. Additionally, we extend our analysis to characterize the performance of SCI systems where the mask entries are not independent but are generated based on a stationary first-order Markov process. Overall, our theoretical framework offers a comprehensive understanding of the performance implications associated with binary masks in SCI systems.