 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactor Informed Double Deep Learning For Average Treatment Effect Estimation
Aug 23, 2025We investigate the problem of estimating the average treatment effect (ATE) under a very general setup where the covariates can be high-dimensional, highly correlated, and can have sparse nonlinear effects on the propensity and outcome models. We present the use of a Double Deep Learning strategy for estimation, which involves combining recently developed factor-augmented deep learning-based estimators, FAST-NN, for both the response functions and propensity scores to achieve our goal. By using FAST-NN, our method can select variables that contribute to propensity and outcome models in a completely nonparametric and algorithmic manner and adaptively learn low-dimensional function structures through neural networks. Our proposed novel estimator, FIDDLE (Factor Informed Double Deep Learning Estimator), estimates ATE based on the framework of augmented inverse propensity weighting AIPW with the FAST-NN-based response and propensity estimates. FIDDLE consistently estimates ATE even under model misspecification and is flexible to also allow for low-dimensional covariates. Our method achieves semiparametric efficiency under a very flexible family of propensity and outcome models. We present extensive numerical studies on synthetic and real datasets to support our theoretical guarantees and establish the advantages of our methods over other traditional choices, especially when the data dimension is large.
Multilook Coherent Imaging: Theoretical Guarantees and Algorithms
May 29, 2025Multilook coherent imaging is a widely used technique in applications such as digital holography, ultrasound imaging, and synthetic aperture radar. A central challenge in these systems is the presence of multiplicative noise, commonly known as speckle, which degrades image quality. Despite the widespread use of coherent imaging systems, their theoretical foundations remain relatively underexplored. In this paper, we study both the theoretical and algorithmic aspects of likelihood-based approaches for multilook coherent imaging, providing a rigorous framework for analysis and method development. Our theoretical contributions include establishing the first theoretical upper bound on the Mean Squared Error (MSE) of the maximum likelihood estimator under the deep image prior hypothesis. Our results capture the dependence of MSE on the number of parameters in the deep image prior, the number of looks, the signal dimension, and the number of measurements per look. On the algorithmic side, we employ projected gradient descent (PGD) as an efficient method for computing the maximum likelihood solution. Furthermore, we introduce two key ideas to enhance the practical performance of PGD. First, we incorporate the Newton-Schulz algorithm to compute matrix inverses within the PGD iterations, significantly reducing computational complexity. Second, we develop a bagging strategy to mitigate projection errors introduced during PGD updates. We demonstrate that combining these techniques with PGD yields state-of-the-art performance. Our code is available at https://github.com/Computational-Imaging-RU/Bagged-DIP-Speckle.
Factor Adjusted Spectral Clustering for Mixture Models
Aug 22, 2024This paper studies a factor modeling-based approach for clustering high-dimensional data generated from a mixture of strongly correlated variables. Statistical modeling with correlated structures pervades modern applications in economics, finance, genomics, wireless sensing, etc., with factor modeling being one of the popular techniques for explaining the common dependence. Standard techniques for clustering high-dimensional data, e.g., naive spectral clustering, often fail to yield insightful results as their performances heavily depend on the mixture components having a weakly correlated structure. To address the clustering problem in the presence of a latent factor model, we propose the Factor Adjusted Spectral Clustering (FASC) algorithm, which uses an additional data denoising step via eliminating the factor component to cope with the data dependency. We prove this method achieves an exponentially low mislabeling rate, with respect to the signal to noise ratio under a general set of assumptions. Our assumption bridges many classical factor models in the literature, such as the pervasive factor model, the weak factor model, and the sparse factor model. The FASC algorithm is also computationally efficient, requiring only near-linear sample complexity with respect to the data dimension. We also show the applicability of the FASC algorithm with real data experiments and numerical studies, and establish that FASC provides significant results in many cases where traditional spectral clustering fails.
A general theory for robust clustering via trimmed mean
Jan 10, 2024



Clustering is a fundamental tool in statistical machine learning in the presence of heterogeneous data. Many recent results focus primarily on optimal mislabeling guarantees, when data are distributed around centroids with sub-Gaussian errors. Yet, the restrictive sub-Gaussian model is often invalid in practice, since various real-world applications exhibit heavy tail distributions around the centroids or suffer from possible adversarial attacks that call for robust clustering with a robust data-driven initialization. In this paper, we introduce a hybrid clustering technique with a novel multivariate trimmed mean type centroid estimate to produce mislabeling guarantees under a weak initialization condition for general error distributions around the centroids. A matching lower bound is derived, up to factors depending on the number of clusters. In addition, our approach also produces the optimal mislabeling even in the presence of adversarial outliers. Our results reduce to the sub-Gaussian case when errors follow sub-Gaussian distributions. To solve the problem thoroughly, we also present novel data-driven robust initialization techniques and show that, with probabilities approaching one, these initial centroid estimates are sufficiently good for the subsequent clustering algorithm to achieve the optimal mislabeling rates. Furthermore, we demonstrate that the Lloyd algorithm is suboptimal for more than two clusters even when errors are Gaussian, and for two clusters when errors distributions have heavy tails. Both simulated data and real data examples lend further support to both of our robust initialization procedure and clustering algorithm.
Adversarially robust clustering with optimality guarantees
Jun 16, 2023



We consider the problem of clustering data points coming from sub-Gaussian mixtures. Existing methods that provably achieve the optimal mislabeling error, such as the Lloyd algorithm, are usually vulnerable to outliers. In contrast, clustering methods seemingly robust to adversarial perturbations are not known to satisfy the optimal statistical guarantees. We propose a simple algorithm that obtains the optimal mislabeling rate even when we allow adversarial outliers to be present. Our algorithm achieves the optimal error rate in constant iterations when a weak initialization condition is satisfied. In the absence of outliers, in fixed dimensions, our theoretical guarantees are similar to that of the Lloyd algorithm. Extensive experiments on various simulated data sets are conducted to support the theoretical guarantees of our method.
Support Recovery with Stochastic Gates: Theory and Application for Linear Models
Nov 01, 2021
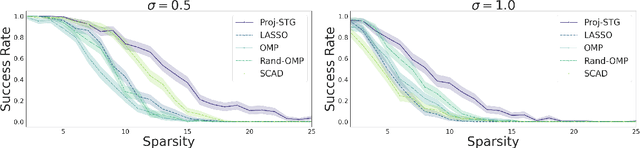

We analyze the problem of simultaneous support recovery and estimation of the coefficient vector ($\beta^*$) in a linear model with independent and identically distributed Normal errors. We apply the penalized least square estimator based on non-linear penalties of stochastic gates (STG) [YLNK20] to estimate the coefficients. Considering Gaussian design matrices we show that under reasonable conditions on dimension and sparsity of $\beta^*$ the STG based estimator converges to the true data generating coefficient vector and also detects its support set with high probability. We propose a new projection based algorithm for linear models setup to improve upon the existing STG estimator that was originally designed for general non-linear models. Our new procedure outperforms many classical estimators for support recovery in synthetic data analysis.
Extrapolating the profile of a finite population
May 21, 2020We study a prototypical problem in empirical Bayes. Namely, consider a population consisting of $k$ individuals each belonging to one of $k$ types (some types can be empty). Without any structural restrictions, it is impossible to learn the composition of the full population having observed only a small (random) subsample of size $m = o(k)$. Nevertheless, we show that in the sublinear regime of $m =\omega(k/\log k)$, it is possible to consistently estimate in total variation the \emph{profile} of the population, defined as the empirical distribution of the sizes of each type, which determines many symmetric properties of the population. We also prove that in the linear regime of $m=c k$ for any constant $c$ the optimal rate is $\Theta(1/\log k)$. Our estimator is based on Wolfowitz's minimum distance method, which entails solving a linear program (LP) of size $k$. We show that there is a single infinite-dimensional LP whose value simultaneously characterizes the risk of the minimum distance estimator and certifies its minimax optimality. The sharp convergence rate is obtained by evaluating this LP using complex-analytic techniques.