 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Robot collaboration in surgery: Advances and challenges towards autonomous surgical assistants
Jul 15, 2025Human-robot collaboration in surgery represents a significant area of research, driven by the increasing capability of autonomous robotic systems to assist surgeons in complex procedures. This systematic review examines the advancements and persistent challenges in the development of autonomous surgical robotic assistants (ASARs), focusing specifically on scenarios where robots provide meaningful and active support to human surgeons. Adhering to the PRISMA guidelines, a comprehensive literature search was conducted across the IEEE Xplore, Scopus, and Web of Science databases, resulting in the selection of 32 studies for detailed analysis. Two primary collaborative setups were identified: teleoperation-based assistance and direct hands-on interaction. The findings reveal a growing research emphasis on ASARs, with predominant applications currently in endoscope guidance, alongside emerging progress in autonomous tool manipulation. Several key challenges hinder wider adoption, including the alignment of robotic actions with human surgeon preferences, the necessity for procedural awareness within autonomous systems, the establishment of seamless human-robot information exchange, and the complexities of skill acquisition in shared workspaces. This review synthesizes current trends, identifies critical limitations, and outlines future research directions essential to improve the reliability, safety, and effectiveness of human-robot collaboration in surgical environments.
* Accepted at 2025 IEEE International Conference on Robot and Human Interactive Communication (ROMAN)
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Apr 10, 2025


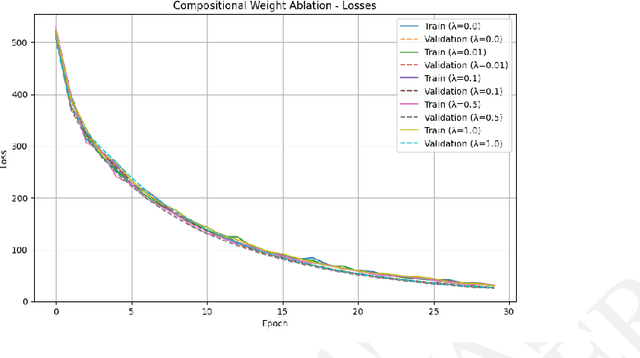
AI is increasingly playing a pivotal role in transforming how scientific discoveries are made. We introduce The AI Scientist-v2, an end-to-end agentic system capable of producing the first entirely AI generated peer-review-accepted workshop paper. This system iteratively formulates scientific hypotheses, designs and executes experiments, analyzes and visualizes data, and autonomously authors scientific manuscripts. Compared to its predecessor (v1, Lu et al., 2024 arXiv:2408.06292), The AI Scientist-v2 eliminates the reliance on human-authored code templates, generalizes effectively across diverse machine learning domains, and leverages a novel progressive agentic tree-search methodology managed by a dedicated experiment manager agent. Additionally, we enhance the AI reviewer component by integrating a Vision-Language Model (VLM) feedback loop for iterative refinement of content and aesthetics of the figures. We evaluated The AI Scientist-v2 by submitting three fully autonomous manuscripts to a peer-reviewed ICLR workshop. Notably, one manuscript achieved high enough scores to exceed the average human acceptance threshold, marking the first instance of a fully AI-generated paper successfully navigating a peer review. This accomplishment highlights the growing capability of AI in conducting all aspects of scientific research. We anticipate that further advancements in autonomous scientific discovery technologies will profoundly impact human knowledge generation, enabling unprecedented scalability in research productivity and significantly accelerating scientific breakthroughs, greatly benefiting society at large. We have open-sourced the code at https://github.com/SakanaAI/AI-Scientist-v2 to foster the future development of this transformative technology. We also discuss the role of AI in science, including AI safety.
Embedded Image-to-Image Translation for Efficient Sim-to-Real Transfer in Learning-based Robot-Assisted Soft Manipulation
Sep 16, 2024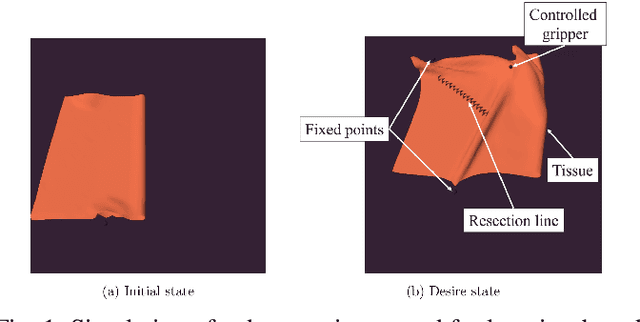

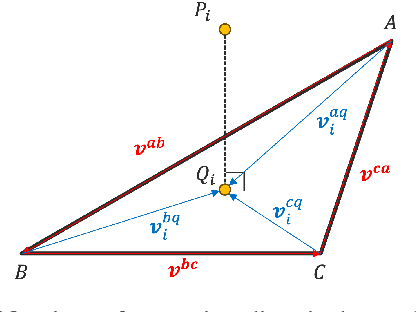

Recent advances in robotic learning in simulation have shown impressive results in accelerating learning complex manipulation skills. However, the sim-to-real gap, caused by discrepancies between simulation and reality, poses significant challenges for the effective deployment of autonomous surgical systems. We propose a novel approach utilizing image translation models to mitigate domain mismatches and facilitate efficient robot skill learning in a simulated environment. Our method involves the use of contrastive unpaired Image-to-image translation, allowing for the acquisition of embedded representations from these transformed images. Subsequently, these embeddings are used to improve the efficiency of training surgical manipulation models. We conducted experiments to evaluate the performance of our approach, demonstrating that it significantly enhances task success rates and reduces the steps required for task completion compared to traditional methods. The results indicate that our proposed system effectively bridges the sim-to-real gap, providing a robust framework for advancing the autonomy of surgical robots in minimally invasive procedures.
Task segmentation based on transition state clustering for surgical robot assistance
Jun 14, 2024Understanding surgical tasks represents an important challenge for autonomy in surgical robotic systems. To achieve this, we propose an online task segmentation framework that uses hierarchical transition state clustering to activate predefined robot assistance. Our approach involves performing a first clustering on visual features and a subsequent clustering on robot kinematic features for each visual cluster. This enables to capture relevant task transition information on each modality independently. The approach is implemented for a pick-and-place task commonly found in surgical training. The validation of the transition segmentation showed high accuracy and fast computation time. We have integrated the transition recognition module with predefined robot-assisted tool positioning. The complete framework has shown benefits in reducing task completion time and cognitive workload.
* Accepted at 2023 International Conference on Control and Robotics Engineering (ICCRE)
L3GO: Language Agents with Chain-of-3D-Thoughts for Generating Unconventional Objects
Feb 14, 2024Diffusion-based image generation models such as DALL-E 3 and Stable Diffusion-XL demonstrate remarkable capabilities in generating images with realistic and unique compositions. Yet, these models are not robust in precisely reasoning about physical and spatial configurations of objects, especially when instructed with unconventional, thereby out-of-distribution descriptions, such as "a chair with five legs". In this paper, we propose a language agent with chain-of-3D-thoughts (L3GO), an inference-time approach that can reason about part-based 3D mesh generation of unconventional objects that current data-driven diffusion models struggle with. More concretely, we use large language models as agents to compose a desired object via trial-and-error within the 3D simulation environment. To facilitate our investigation, we develop a new benchmark, Unconventionally Feasible Objects (UFO), as well as SimpleBlenv, a wrapper environment built on top of Blender where language agents can build and compose atomic building blocks via API calls. Human and automatic GPT-4V evaluations show that our approach surpasses the standard GPT-4 and other language agents (e.g., ReAct and Reflexion) for 3D mesh generation on ShapeNet. Moreover, when tested on our UFO benchmark, our approach outperforms other state-of-the-art text-to-2D image and text-to-3D models based on human evaluation.
Evaluating Spatial Understanding of Large Language Models
Oct 23, 2023Large language models (LLMs) show remarkable capabilities across a variety of tasks. Despite the models only seeing text in training, several recent studies suggest that LLM representations implicitly capture aspects of the underlying grounded concepts. Here, we explore LLM representations of a particularly salient kind of grounded knowledge -- spatial relationships. We design natural-language navigation tasks and evaluate the ability of LLMs, in particular GPT-3.5-turbo, GPT-4, and Llama2 series models, to represent and reason about spatial structures, and compare these abilities to human performance on the same tasks. These tasks reveal substantial variability in LLM performance across different spatial structures, including square, hexagonal, and triangular grids, rings, and trees. We also discover that, similar to humans, LLMs utilize object names as landmarks for maintaining spatial maps. Finally, in extensive error analysis, we find that LLMs' mistakes reflect both spatial and non-spatial factors. These findings suggest that LLMs appear to capture certain aspects of spatial structure implicitly, but room for improvement remains.
Evaluating GPT-4 and ChatGPT on Japanese Medical Licensing Examinations
Apr 05, 2023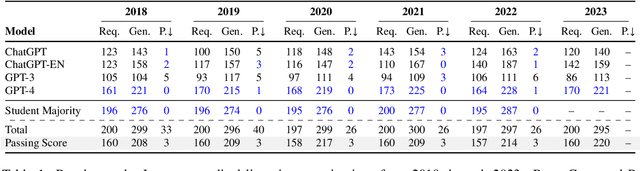
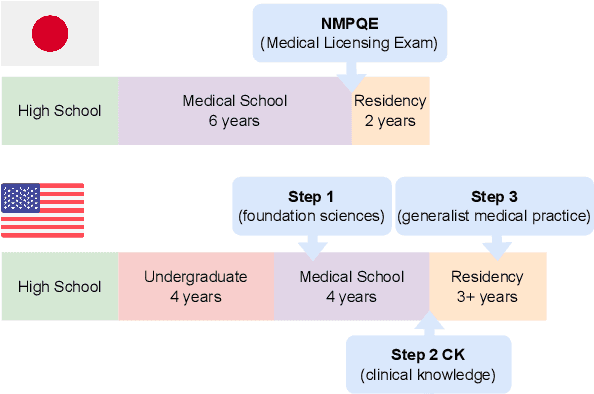
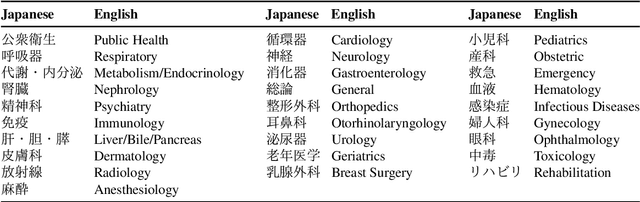
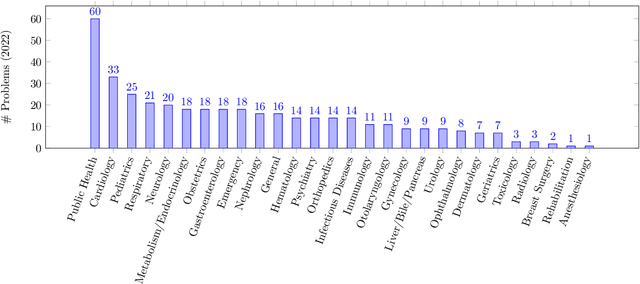
As large language models (LLMs) gain popularity among speakers of diverse languages, we believe that it is crucial to benchmark them to better understand model behaviors, failures, and limitations in languages beyond English. In this work, we evaluate LLM APIs (ChatGPT, GPT-3, and GPT-4) on the Japanese national medical licensing examinations from the past five years, including the current year. Our team comprises native Japanese-speaking NLP researchers and a practicing cardiologist based in Japan. Our experiments show that GPT-4 outperforms ChatGPT and GPT-3 and passes all six years of the exams, highlighting LLMs' potential in a language that is typologically distant from English. However, our evaluation also exposes critical limitations of the current LLM APIs. First, LLMs sometimes select prohibited choices that should be strictly avoided in medical practice in Japan, such as suggesting euthanasia. Further, our analysis shows that the API costs are generally higher and the maximum context size is smaller for Japanese because of the way non-Latin scripts are currently tokenized in the pipeline. We release our benchmark as Igaku QA as well as all model outputs and exam metadata. We hope that our results and benchmark will spur progress on more diverse applications of LLMs. Our benchmark is available at https://github.com/jungokasai/IgakuQA.
When are Lemons Purple? The Concept Association Bias of CLIP
Dec 22, 2022Large-scale vision-language models such as CLIP have shown impressive performance on zero-shot image classification and image-to-text retrieval. However, such zero-shot performance of CLIP-based models does not realize in tasks that require a finer-grained correspondence between vision and language, such as Visual Question Answering (VQA). We investigate why this is the case, and report an interesting phenomenon of CLIP, which we call the Concept Association Bias (CAB), as a potential cause of the difficulty of applying CLIP to VQA and similar tasks. CAB is especially apparent when two concepts are present in the given image while a text prompt only contains a single concept. In such a case, we find that CLIP tends to treat input as a bag of concepts and attempts to fill in the other missing concept crossmodally, leading to an unexpected zero-shot prediction. For example, when asked for the color of a lemon in an image, CLIP predicts ``purple'' if the image contains a lemon and an eggplant. We demonstrate the Concept Association Bias of CLIP by showing that CLIP's zero-shot classification performance greatly suffers when there is a strong concept association between an object (e.g. lemon) and an attribute (e.g. its color). On the other hand, when the association between object and attribute is weak, we do not see this phenomenon. Furthermore, we show that CAB is significantly mitigated when we enable CLIP to learn deeper structure across image and text embeddings by adding an additional Transformer on top of CLIP and fine-tuning it on VQA. We find that across such fine-tuned variants of CLIP, the strength of CAB in a model predicts how well it performs on VQA.
Does Robustness on ImageNet Transfer to Downstream Tasks?
Apr 08, 2022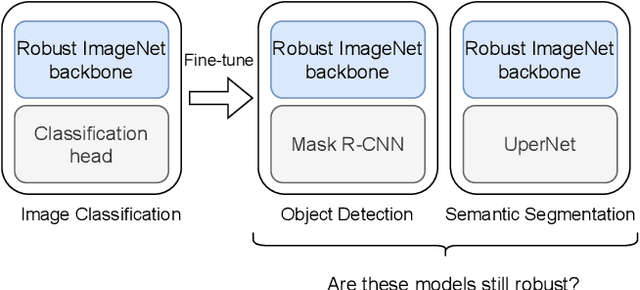
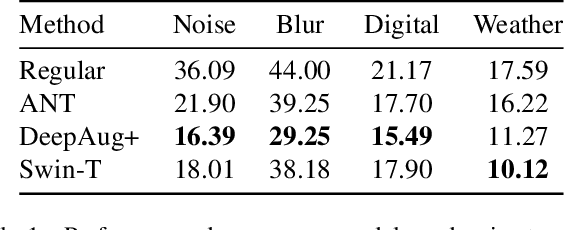
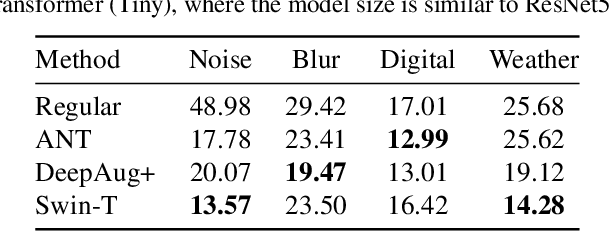
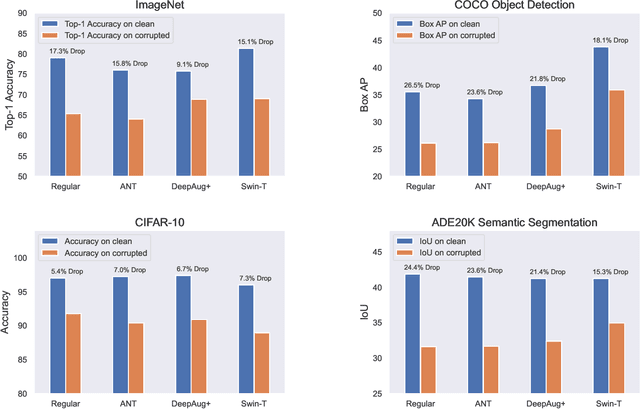
As clean ImageNet accuracy nears its ceiling, the research community is increasingly more concerned about robust accuracy under distributional shifts. While a variety of methods have been proposed to robustify neural networks, these techniques often target models trained on ImageNet classification. At the same time, it is a common practice to use ImageNet pretrained backbones for downstream tasks such as object detection, semantic segmentation, and image classification from different domains. This raises a question: Can these robust image classifiers transfer robustness to downstream tasks? For object detection and semantic segmentation, we find that a vanilla Swin Transformer, a variant of Vision Transformer tailored for dense prediction tasks, transfers robustness better than Convolutional Neural Networks that are trained to be robust to the corrupted version of ImageNet. For CIFAR10 classification, we find that models that are robustified for ImageNet do not retain robustness when fully fine-tuned. These findings suggest that current robustification techniques tend to emphasize ImageNet evaluations. Moreover, network architecture is a strong source of robustness when we consider transfer learning.
Can Wikipedia Help Offline Reinforcement Learning?
Jan 28, 2022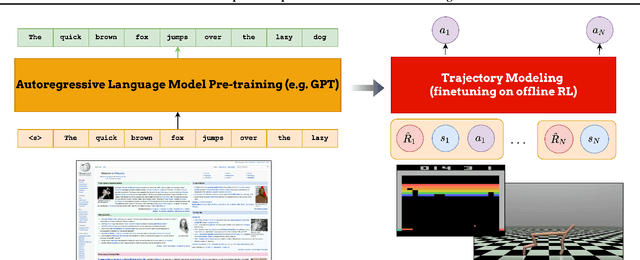
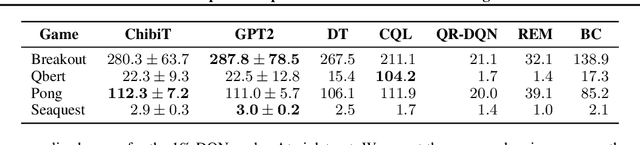
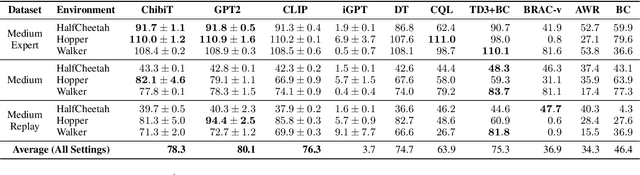
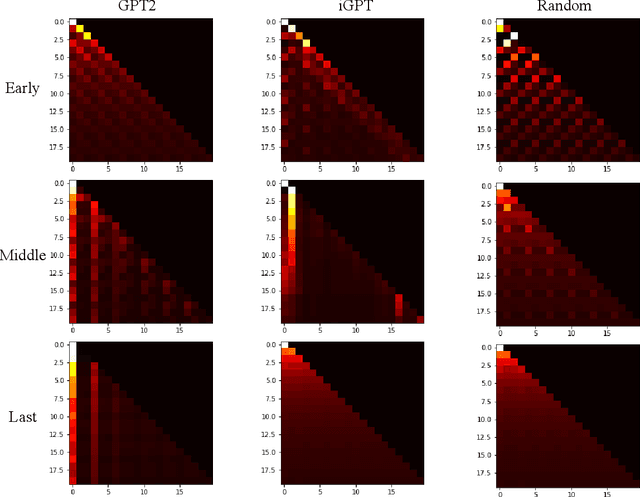
Fine-tuning reinforcement learning (RL) models has been challenging because of a lack of large scale off-the-shelf datasets as well as high variance in transferability among different environments. Recent work has looked at tackling offline RL from the perspective of sequence modeling with improved results as result of the introduction of the Transformer architecture. However, when the model is trained from scratch, it suffers from slow convergence speeds. In this paper, we look to take advantage of this formulation of reinforcement learning as sequence modeling and investigate the transferability of pre-trained sequence models on other domains (vision, language) when finetuned on offline RL tasks (control, games). To this end, we also propose techniques to improve transfer between these domains. Results show consistent performance gains in terms of both convergence speed and reward on a variety of environments, accelerating training by 3-6x and achieving state-of-the-art performance in a variety of tasks using Wikipedia-pretrained and GPT2 language models. We hope that this work not only brings light to the potentials of leveraging generic sequence modeling techniques and pre-trained models for RL, but also inspires future work on sharing knowledge between generative modeling tasks of completely different domains.