 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3GO: Language Agents with Chain-of-3D-Thoughts for Generating Unconventional Objects
Feb 14, 2024Diffusion-based image generation models such as DALL-E 3 and Stable Diffusion-XL demonstrate remarkable capabilities in generating images with realistic and unique compositions. Yet, these models are not robust in precisely reasoning about physical and spatial configurations of objects, especially when instructed with unconventional, thereby out-of-distribution descriptions, such as "a chair with five legs". In this paper, we propose a language agent with chain-of-3D-thoughts (L3GO), an inference-time approach that can reason about part-based 3D mesh generation of unconventional objects that current data-driven diffusion models struggle with. More concretely, we use large language models as agents to compose a desired object via trial-and-error within the 3D simulation environment. To facilitate our investigation, we develop a new benchmark, Unconventionally Feasible Objects (UFO), as well as SimpleBlenv, a wrapper environment built on top of Blender where language agents can build and compose atomic building blocks via API calls. Human and automatic GPT-4V evaluations show that our approach surpasses the standard GPT-4 and other language agents (e.g., ReAct and Reflexion) for 3D mesh generation on ShapeNet. Moreover, when tested on our UFO benchmark, our approach outperforms other state-of-the-art text-to-2D image and text-to-3D models based on human evaluation.
How does the primate brain combine generative and discriminative computations in vision?
Jan 11, 2024Vision is widely understood as an inference problem. However, two contrasting conceptions of the inference process have each been influential in research on biological vision as well as the engineering of machine vision. The first emphasizes bottom-up signal flow, describing vision as a largely feedforward, discriminative inference process that filters and transforms the visual information to remove irrelevant variation and represent behaviorally relevant information in a format suitable for downstream functions of cognition and behavioral control. In this conception, vision is driven by the sensory data, and perception is direct because the processing proceeds from the data to the latent variables of interest. The notion of "inference" in this conception is that of the engineering literature on neural networks, where feedforward convolutional neural networks processing images are said to perform inference. The alternative conception is that of vision as an inference process in Helmholtz's sense, where the sensory evidence is evaluated in the context of a generative model of the causal processes giving rise to it. In this conception, vision inverts a generative model through an interrogation of the evidence in a process often thought to involve top-down predictions of sensory data to evaluate the likelihood of alternative hypotheses. The authors include scientists rooted in roughly equal numbers in each of the conceptions and motivated to overcome what might be a false dichotomy between them and engage the other perspective in the realm of theory and experiment. The primate brain employs an unknown algorithm that may combine the advantages of both conceptions. We explain and clarify the terminology, review the key empirical evidence, and propose an empirical research program that transcends the dichotomy and sets the stage for revealing the mysterious hybrid algorithm of primate vision.
Evaluating Spatial Understanding of Large Language Models
Oct 23, 2023Large language models (LLMs) show remarkable capabilities across a variety of tasks. Despite the models only seeing text in training, several recent studies suggest that LLM representations implicitly capture aspects of the underlying grounded concepts. Here, we explore LLM representations of a particularly salient kind of grounded knowledge -- spatial relationships. We design natural-language navigation tasks and evaluate the ability of LLMs, in particular GPT-3.5-turbo, GPT-4, and Llama2 series models, to represent and reason about spatial structures, and compare these abilities to human performance on the same tasks. These tasks reveal substantial variability in LLM performance across different spatial structures, including square, hexagonal, and triangular grids, rings, and trees. We also discover that, similar to humans, LLMs utilize object names as landmarks for maintaining spatial maps. Finally, in extensive error analysis, we find that LLMs' mistakes reflect both spatial and non-spatial factors. These findings suggest that LLMs appear to capture certain aspects of spatial structure implicitly, but room for improvement remains.
From task structures to world models: What do LLMs know?
Oct 06, 2023

In what sense does a large language model have knowledge? The answer to this question extends beyond the capabilities of a particular AI system, and challenges our assumptions about the nature of knowledge and intelligence. We answer by granting LLMs "instrumental knowledge"; knowledge defined by a certain set of abilities. We then ask how such knowledge is related to the more ordinary, "worldly" knowledge exhibited by human agents, and explore this in terms of the degree to which instrumental knowledge can be said to incorporate the structured world models of cognitive science. We discuss ways LLMs could recover degrees of worldly knowledge, and suggest such recovery will be governed by an implicit, resource-rational tradeoff between world models and task demands.
From seeing to remembering: Images with harder-to-reconstruct representations leave stronger memory traces
Feb 21, 2023Much of what we remember is not due to intentional selection, but simply a by-product of perceiving. This raises a foundational question about the architecture of the mind: How does perception interface with and influence memory? Here, inspired by a classic proposal relating perceptual processing to memory durability, the level-of-processing theory, we present a sparse coding model for compressing feature embeddings of images, and show that the reconstruction residuals from this model predict how well images are encoded into memory. In an open memorability dataset of scene images, we show that reconstruction error not only explains memory accuracy but also response latencies during retrieval, subsuming, in the latter case, all of the variance explained by powerful vision-only models. We also confirm a prediction of this account with 'model-driven psychophysics'. This work establishes reconstruction error as a novel signal interfacing perception and memory, possibly through adaptive modulation of perceptual processing.
3D Shape Perception Integrates Intuitive Physics and Analysis-by-Synthesis
Jan 09, 2023Many surface cues support three-dimensional shape perception, but people can sometimes still see shape when these features are missing -- in extreme cases, even when an object is completely occluded, as when covered with a draped cloth. We propose a framework for 3D shape perception that explains perception in both typical and atypical cases as analysis-by-synthesis, or inference in a generative model of image formation: the model integrates intuitive physics to explain how shape can be inferred from deformations it causes to other objects, as in cloth-draping. Behavioral and computational studies comparing this account with several alternatives show that it best matches human observers in both accuracy and response times, and is the only model that correlates significantly with human performance on difficult discriminations. Our results suggest that bottom-up deep neural network models are not fully adequate accounts of human shape perception, and point to how machine vision systems might achieve more human-like robustness.
When are Lemons Purple? The Concept Association Bias of CLIP
Dec 22, 2022Large-scale vision-language models such as CLIP have shown impressive performance on zero-shot image classification and image-to-text retrieval. However, such zero-shot performance of CLIP-based models does not realize in tasks that require a finer-grained correspondence between vision and language, such as Visual Question Answering (VQA). We investigate why this is the case, and report an interesting phenomenon of CLIP, which we call the Concept Association Bias (CAB), as a potential cause of the difficulty of applying CLIP to VQA and similar tasks. CAB is especially apparent when two concepts are present in the given image while a text prompt only contains a single concept. In such a case, we find that CLIP tends to treat input as a bag of concepts and attempts to fill in the other missing concept crossmodally, leading to an unexpected zero-shot prediction. For example, when asked for the color of a lemon in an image, CLIP predicts ``purple'' if the image contains a lemon and an eggplant. We demonstrate the Concept Association Bias of CLIP by showing that CLIP's zero-shot classification performance greatly suffers when there is a strong concept association between an object (e.g. lemon) and an attribute (e.g. its color). On the other hand, when the association between object and attribute is weak, we do not see this phenomenon. Furthermore, we show that CAB is significantly mitigated when we enable CLIP to learn deeper structure across image and text embeddings by adding an additional Transformer on top of CLIP and fine-tuning it on VQA. We find that across such fine-tuned variants of CLIP, the strength of CAB in a model predicts how well it performs on VQA.
Explaining intuitive difficulty judgments by modeling physical effort and risk
May 14, 2019



The ability to estimate task difficulty is critical for many real-world decisions such as setting appropriate goals for ourselves or appreciating others' accomplishments. Here we give a computational account of how humans judge the difficulty of a range of physical construction tasks (e.g., moving 10 loose blocks from their initial configuration to their target configuration, such as a vertical tower) by quantifying two key factors that influence construction difficulty: physical effort and physical risk. Physical effort captures the minimal work needed to transport all objects to their final positions, and is computed using a hybrid task-and-motion planner. Physical risk corresponds to stability of the structure, and is computed using noisy physics simulations to capture the costs for precision (e.g., attention, coordination, fine motor movements) required for success. We show that the full effort-risk model captures human estimates of difficulty and construction time better than either component alone.
Modeling human intuitions about liquid flow with particle-based simulation
Sep 05, 2018


Humans can easily describe, imagine, and, crucially, predict a wide variety of behaviors of liquids--splashing, squirting, gushing, sloshing, soaking, dripping, draining, trickling, pooling, and pouring--despite tremendous variability in their material and dynamical properties. Here we propose and test a computational model of how people perceive and predict these liquid dynamics, based on coarse approximate simulations of fluids as collections of interacting particles. Our model is analogous to a "game engine in the head", drawing on techniques for interactive simulations (as in video games) that optimize for efficiency and natural appearance rather than physical accuracy. In two behavioral experiments, we found that the model accurately captured people's predictions about how liquids flow among complex solid obstacles, and was significantly better than two alternatives based on simple heuristics and deep neural networks. Our model was also able to explain how people's predictions varied as a function of the liquids' properties (e.g., viscosity and stickiness). Together, the model and empirical results extend the recent proposal that human physical scene understanding for the dynamics of rigid, solid objects can be supported by approximate probabilistic simulation, to the more complex and unexplored domain of fluid dynamics.
Self-Supervised Intrinsic Image Decomposition
Feb 05, 2018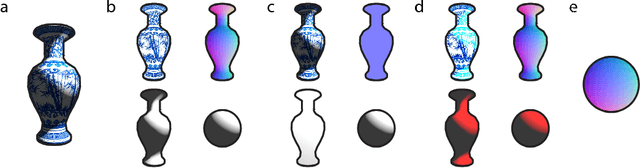
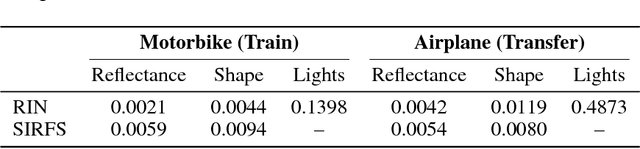
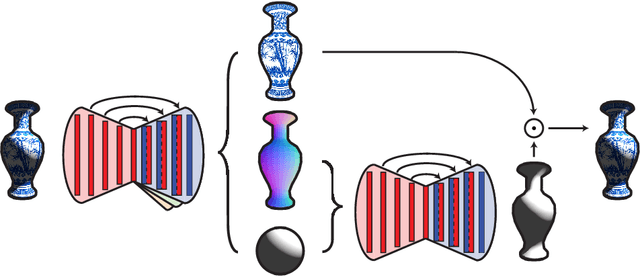

Intrinsic decomposition from a single image is a highly challenging task, due to its inherent ambiguity and the scarcity of training data. In contrast to traditional fully supervised learning approaches, in this paper we propose learning intrinsic image decomposition by explaining the input image. Our model, the Rendered Intrinsics Network (RIN), joins together an image decomposition pipeline, which predicts reflectance, shape, and lighting conditions given a single image, with a recombination function, a learned shading model used to recompose the original input based off of intrinsic image predictions. Our network can then use unsupervised reconstruction error as an additional signal to improve its intermediate representations. This allows large-scale unlabeled data to be useful during training, and also enables transferring learned knowledge to images of unseen object categories, lighting conditions, and shapes. Extensive experiments demonstrate that our method performs well on both intrinsic image decomposition and knowledge transfer.