 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational reasoning and inductive bias in transformers trained on a transitive inference task
Jun 04, 2025



Transformer-based models have demonstrated remarkable reasoning abilities, but the mechanisms underlying relational reasoning in different learning regimes remain poorly understood. In this work, we investigate how transformers perform a classic relational reasoning task from the Psychology literature, \textit{transitive inference}, which requires inference about indirectly related items by integrating information across observed adjacent item pairs (e.g., if A>B and B>C, then A>C). We compare transitive inference behavior across two distinct learning regimes: in-weights learning (IWL), where models store information in network parameters, and in-context learning (ICL), where models flexibly utilize information presented within the input sequence. Our findings reveal that IWL naturally induces a generalization bias towards transitive inference, despite being trained only on adjacent items, whereas ICL models trained solely on adjacent items do not generalize transitively. Mechanistic analysis shows that ICL models develop induction circuits that implement a simple match-and-copy strategy that performs well at relating adjacent pairs, but does not encoding hierarchical relationships among indirectly related items. Interestingly, when pre-trained on in-context linear regression tasks, transformers successfully exhibit in-context generalizable transitive inference. Moreover, like IWL, they display both \textit{symbolic distance} and \textit{terminal item effects} characteristic of human and animal performance, without forming induction circuits. These results suggest that pre-training on tasks with underlying structure promotes the development of representations that can scaffold in-context relational reasoning.
Learning rigid-body simulators over implicit shapes for large-scale scenes and vision
May 22, 2024Simulating large scenes with many rigid objects is crucial for a variety of applications, such as robotics, engineering, film and video games. Rigid interactions are notoriously hard to model: small changes to the initial state or the simulation parameters can lead to large changes in the final state. Recently, learned simulators based on graph networks (GNNs) were developed as an alternative to hand-designed simulators like MuJoCo and PyBullet. They are able to accurately capture dynamics of real objects directly from real-world observations. However, current state-of-the-art learned simulators operate on meshes and scale poorly to scenes with many objects or detailed shapes. Here we present SDF-Sim, the first learned rigid-body simulator designed for scale. We use learned signed-distance functions (SDFs) to represent the object shapes and to speed up distance computation. We design the simulator to leverage SDFs and avoid the fundamental bottleneck of the previous simulators associated with collision detection. For the first time in literature, we demonstrate that we can scale the GNN-based simulators to scenes with hundreds of objects and up to 1.1 million nodes, where mesh-based approaches run out of memory. Finally, we show that SDF-Sim can be applied to real world scenes by extracting SDFs from multi-view images.
Scaling Face Interaction Graph Networks to Real World Scenes
Jan 22, 2024Accurately simulating real world object dynamics is essential for various applications such as robotics, engineering, graphics, and design. To better capture complex real dynamics such as contact and friction, learned simulators based on graph networks have recently shown great promise. However, applying these learned simulators to real scenes comes with two major challenges: first, scaling learned simulators to handle the complexity of real world scenes which can involve hundreds of objects each with complicated 3D shapes, and second, handling inputs from perception rather than 3D state information. Here we introduce a method which substantially reduces the memory required to run graph-based learned simulators. Based on this memory-efficient simulation model, we then present a perceptual interface in the form of editable NeRFs which can convert real-world scenes into a structured representation that can be processed by graph network simulator. We show that our method uses substantially less memory than previous graph-based simulators while retaining their accuracy, and that the simulators learned in synthetic environments can be applied to real world scenes captured from multiple camera angles. This paves the way for expanding the application of learned simulators to settings where only perceptual information is available at inference time.
How does the primate brain combine generative and discriminative computations in vision?
Jan 11, 2024Vision is widely understood as an inference problem. However, two contrasting conceptions of the inference process have each been influential in research on biological vision as well as the engineering of machine vision. The first emphasizes bottom-up signal flow, describing vision as a largely feedforward, discriminative inference process that filters and transforms the visual information to remove irrelevant variation and represent behaviorally relevant information in a format suitable for downstream functions of cognition and behavioral control. In this conception, vision is driven by the sensory data, and perception is direct because the processing proceeds from the data to the latent variables of interest. The notion of "inference" in this conception is that of the engineering literature on neural networks, where feedforward convolutional neural networks processing images are said to perform inference. The alternative conception is that of vision as an inference process in Helmholtz's sense, where the sensory evidence is evaluated in the context of a generative model of the causal processes giving rise to it. In this conception, vision inverts a generative model through an interrogation of the evidence in a process often thought to involve top-down predictions of sensory data to evaluate the likelihood of alternative hypotheses. The authors include scientists rooted in roughly equal numbers in each of the conceptions and motivated to overcome what might be a false dichotomy between them and engage the other perspective in the realm of theory and experiment. The primate brain employs an unknown algorithm that may combine the advantages of both conceptions. We explain and clarify the terminology, review the key empirical evidence, and propose an empirical research program that transcends the dichotomy and sets the stage for revealing the mysterious hybrid algorithm of primate vision.
Learning 3D Particle-based Simulators from RGB-D Videos
Dec 08, 2023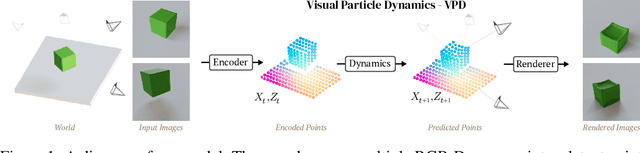

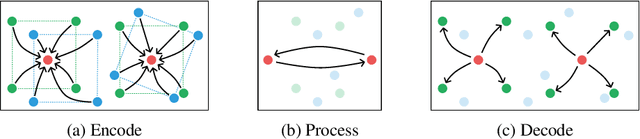
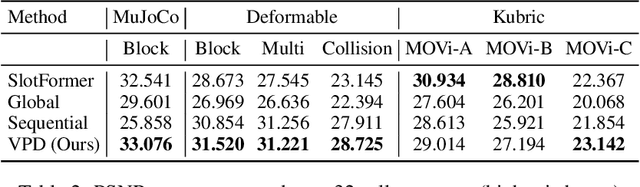
Realistic simulation is critical for applications ranging from robotics to animation. Traditional analytic simulators sometimes struggle to capture sufficiently realistic simulation which can lead to problems including the well known "sim-to-real" gap in robotics. Learned simulators have emerged as an alternative for better capturing real-world physical dynamics, but require access to privileged ground truth physics information such as precise object geometry or particle tracks. Here we propose a method for learning simulators directly from observations. Visual Particle Dynamics (VPD) jointly learns a latent particle-based representation of 3D scenes, a neural simulator of the latent particle dynamics, and a renderer that can produce images of the scene from arbitrary views. VPD learns end to end from posed RGB-D videos and does not require access to privileged information. Unlike existing 2D video prediction models, we show that VPD's 3D structure enables scene editing and long-term predictions. These results pave the way for downstream applications ranging from video editing to robotic planning.
Physical Design using Differentiable Learned Simulators
Feb 01, 2022Designing physical artifacts that serve a purpose - such as tools and other functional structures - is central to engineering as well as everyday human behavior. Though automating design has tremendous promise, general-purpose methods do not yet exist. Here we explore a simple, fast, and robust approach to inverse design which combines learned forward simulators based on graph neural networks with gradient-based design optimization. Our approach solves high-dimensional problems with complex physical dynamics, including designing surfaces and tools to manipulate fluid flows and optimizing the shape of an airfoil to minimize drag. This framework produces high-quality designs by propagating gradients through trajectories of hundreds of steps, even when using models that were pre-trained for single-step predictions on data substantially different from the design tasks. In our fluid manipulation tasks, the resulting designs outperformed those found by sampling-based optimization techniques. In airfoil design, they matched the quality of those obtained with a specialized solver. Our results suggest that despite some remaining challenges, machine learning-based simulators are maturing to the point where they can support general-purpose design optimization across a variety of domains.
Learned Coarse Models for Efficient Turbulence Simulation
Jan 04, 2022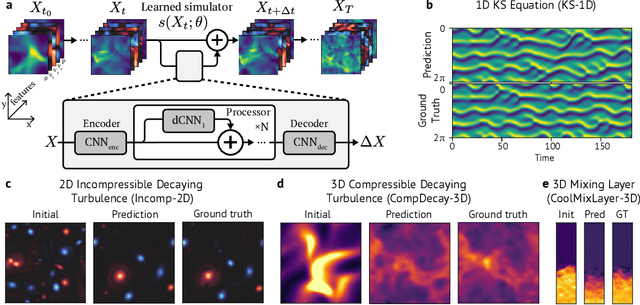
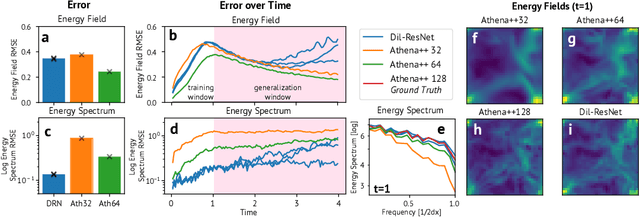
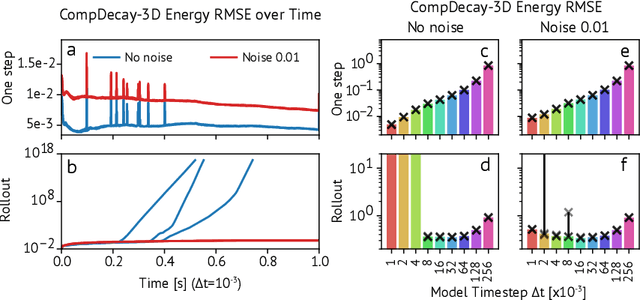

Turbulence simulation with classical numerical solvers requires very high-resolution grids to accurately resolve dynamics. Here we train learned simulators at low spatial and temporal resolutions to capture turbulent dynamics generated at high resolution. We show that our proposed model can simulate turbulent dynamics more accurately than classical numerical solvers at the same low resolutions across various scientifically relevant metrics. Our model is trained end-to-end from data and is capable of learning a range of challenging chaotic and turbulent dynamics at low resolution, including trajectories generated by the state-of-the-art Athena++ engine. We show that our simpler, general-purpose architecture outperforms various more specialized, turbulence-specific architectures from the learned turbulence simulation literature. In general, we see that learned simulators yield unstable trajectories; however, we show that tuning training noise and temporal downsampling solves this problem. We also find that while generalization beyond the training distribution is a challenge for learned models, training noise, convolutional architectures, and added loss constraints can help. Broadly, we conclude that our learned simulator outperforms traditional solvers run on coarser grids, and emphasize that simple design choices can offer stability and robust generalization.
Graph Networks with Spectral Message Passing
Dec 31, 2020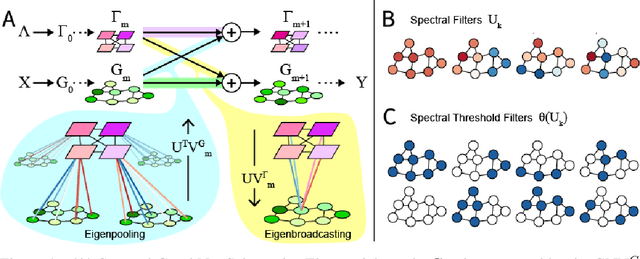
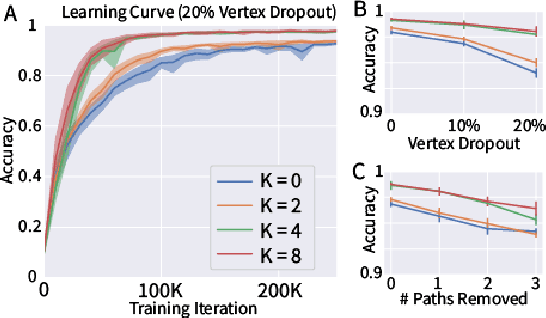
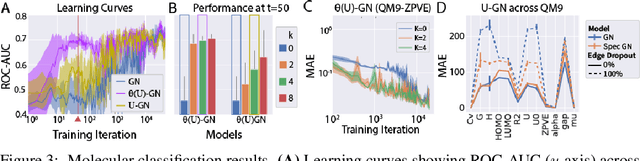
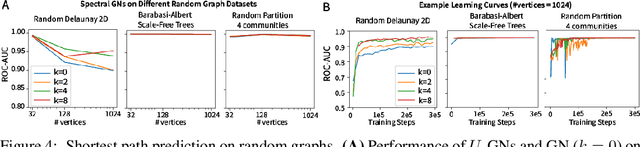
Graph Neural Networks (GNNs) are the subject of intense focus by the machine learning community for problems involving relational reasoning. GNNs can be broadly divided into spatial and spectral approaches. Spatial approaches use a form of learned message-passing, in which interactions among vertices are computed locally, and information propagates over longer distances on the graph with greater numbers of message-passing steps. Spectral approaches use eigendecompositions of the graph Laplacian to produce a generalization of spatial convolutions to graph structured data which access information over short and long time scales simultaneously. Here we introduce the Spectral Graph Network, which applies message passing to both the spatial and spectral domains. Our model projects vertices of the spatial graph onto the Laplacian eigenvectors, which are each represented as vertices in a fully connected "spectral graph", and then applies learned message passing to them. We apply this model to various benchmark tasks including a graph-based variant of MNIST classification, molecular property prediction on MoleculeNet and QM9, and shortest path problems on random graphs. Our results show that the Spectral GN promotes efficient training, reaching high performance with fewer training iterations despite having more parameters. The model also provides robustness to edge dropout and outperforms baselines for the classification tasks. We also explore how these performance benefits depend on properties of the dataset.
Object-oriented state editing for HRL
Oct 31, 2019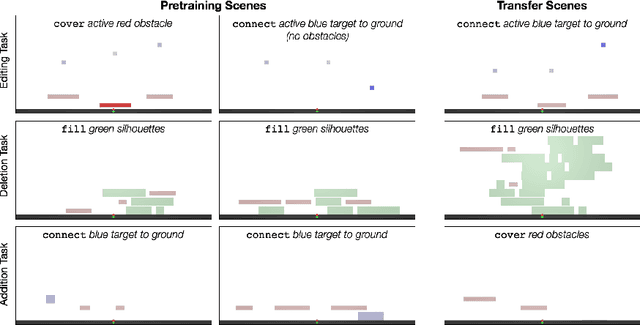
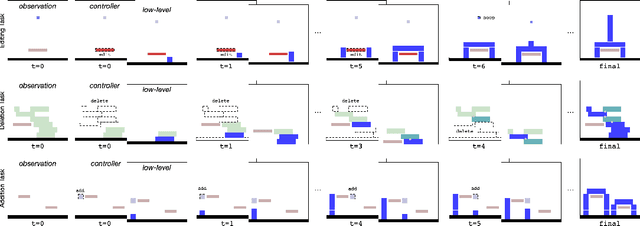
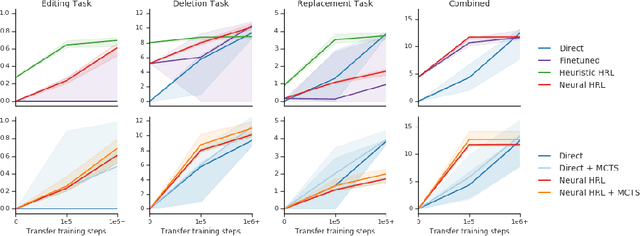

We introduce agents that use object-oriented reasoning to consider alternate states of the world in order to more quickly find solutions to problems. Specifically, a hierarchical controller directs a low-level agent to behave as if objects in the scene were added, deleted, or modified. The actions taken by the controller are defined over a graph-based representation of the scene, with actions corresponding to adding, deleting, or editing the nodes of a graph. We present preliminary results on three environments, demonstrating that our approach can achieve similar levels of reward as non-hierarchical agents, but with better data efficiency.