 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Jun 11, 2025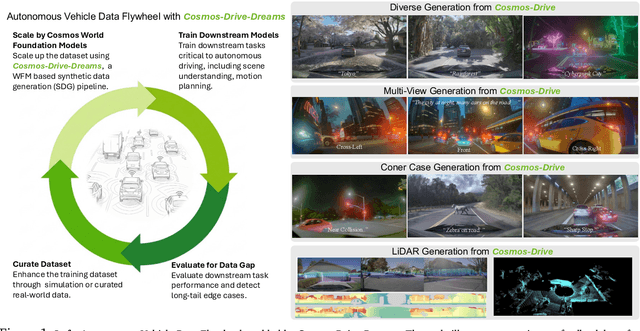
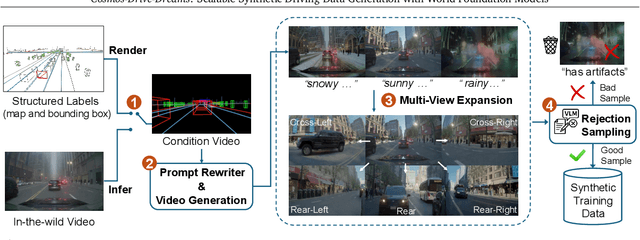
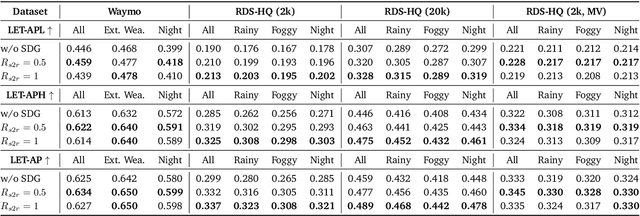
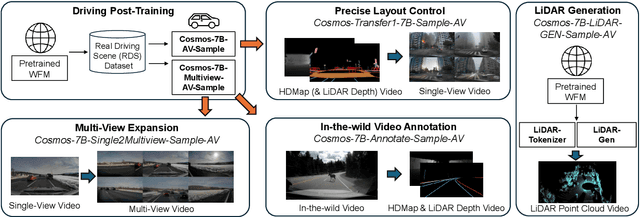
Collecting and annotating real-world data for safety-critical physical AI systems, such as Autonomous Vehicle (AV), is time-consuming and costly. It is especially challenging to capture rare edge cases, which play a critical role in training and testing of an AV system. To address this challenge, we introduce the Cosmos-Drive-Dreams - a synthetic data generation (SDG) pipeline that aims to generate challenging scenarios to facilitate downstream tasks such as perception and driving policy training. Powering this pipeline is Cosmos-Drive, a suite of models specialized from NVIDIA Cosmos world foundation model for the driving domain and are capable of controllable, high-fidelity, multi-view, and spatiotemporally consistent driving video generation. We showcase the utility of these models by applying Cosmos-Drive-Dreams to scale the quantity and diversity of driving datasets with high-fidelity and challenging scenarios. Experimentally, we demonstrate that our generated data helps in mitigating long-tail distribution problems and enhances generalization in downstream tasks such as 3D lane detection, 3D object detection and driving policy learning. We open source our pipeline toolkit, dataset and model weights through the NVIDIA's Cosmos platform. Project page: https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams
Motion Prompting: Controlling Video Generation with Motion Trajectories
Dec 03, 2024Motion control is crucial for generating expressive and compelling video content; however, most existing video generation models rely mainly on text prompts for control, which struggle to capture the nuances of dynamic actions and temporal compositions. To this end, we train a video generation model conditioned on spatio-temporally sparse or dense motion trajectories. In contrast to prior motion conditioning work, this flexible representation can encode any number of trajectories, object-specific or global scene motion, and temporally sparse motion; due to its flexibility we refer to this conditioning as motion prompts. While users may directly specify sparse trajectories, we also show how to translate high-level user requests into detailed, semi-dense motion prompts, a process we term motion prompt expansion. We demonstrate the versatility of our approach through various applications, including camera and object motion control, "interacting" with an image, motion transfer, and image editing. Our results showcase emergent behaviors, such as realistic physics, suggesting the potential of motion prompts for probing video models and interacting with future generative world models. Finally, we evaluate quantitatively, conduct a human study, and demonstrate strong performance. Video results are available on our webpage: https://motion-prompting.github.io/
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Learning rigid-body simulators over implicit shapes for large-scale scenes and vision
May 22, 2024Simulating large scenes with many rigid objects is crucial for a variety of applications, such as robotics, engineering, film and video games. Rigid interactions are notoriously hard to model: small changes to the initial state or the simulation parameters can lead to large changes in the final state. Recently, learned simulators based on graph networks (GNNs) were developed as an alternative to hand-designed simulators like MuJoCo and PyBullet. They are able to accurately capture dynamics of real objects directly from real-world observations. However, current state-of-the-art learned simulators operate on meshes and scale poorly to scenes with many objects or detailed shapes. Here we present SDF-Sim, the first learned rigid-body simulator designed for scale. We use learned signed-distance functions (SDFs) to represent the object shapes and to speed up distance computation. We design the simulator to leverage SDFs and avoid the fundamental bottleneck of the previous simulators associated with collision detection. For the first time in literature, we demonstrate that we can scale the GNN-based simulators to scenes with hundreds of objects and up to 1.1 million nodes, where mesh-based approaches run out of memory. Finally, we show that SDF-Sim can be applied to real world scenes by extracting SDFs from multi-view images.
Scaling Face Interaction Graph Networks to Real World Scenes
Jan 22, 2024Accurately simulating real world object dynamics is essential for various applications such as robotics, engineering, graphics, and design. To better capture complex real dynamics such as contact and friction, learned simulators based on graph networks have recently shown great promise. However, applying these learned simulators to real scenes comes with two major challenges: first, scaling learned simulators to handle the complexity of real world scenes which can involve hundreds of objects each with complicated 3D shapes, and second, handling inputs from perception rather than 3D state information. Here we introduce a method which substantially reduces the memory required to run graph-based learned simulators. Based on this memory-efficient simulation model, we then present a perceptual interface in the form of editable NeRFs which can convert real-world scenes into a structured representation that can be processed by graph network simulator. We show that our method uses substantially less memory than previous graph-based simulators while retaining their accuracy, and that the simulators learned in synthetic environments can be applied to real world scenes captured from multiple camera angles. This paves the way for expanding the application of learned simulators to settings where only perceptual information is available at inference time.
Learning 3D Particle-based Simulators from RGB-D Videos
Dec 08, 2023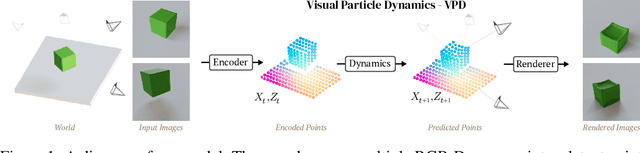

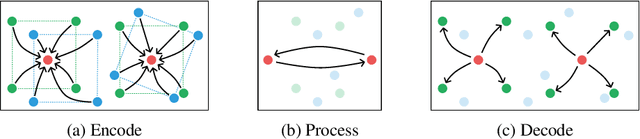
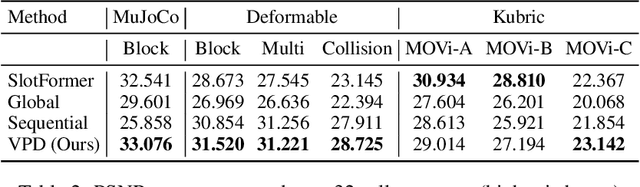
Realistic simulation is critical for applications ranging from robotics to animation. Traditional analytic simulators sometimes struggle to capture sufficiently realistic simulation which can lead to problems including the well known "sim-to-real" gap in robotics. Learned simulators have emerged as an alternative for better capturing real-world physical dynamics, but require access to privileged ground truth physics information such as precise object geometry or particle tracks. Here we propose a method for learning simulators directly from observations. Visual Particle Dynamics (VPD) jointly learns a latent particle-based representation of 3D scenes, a neural simulator of the latent particle dynamics, and a renderer that can produce images of the scene from arbitrary views. VPD learns end to end from posed RGB-D videos and does not require access to privileged information. Unlike existing 2D video prediction models, we show that VPD's 3D structure enables scene editing and long-term predictions. These results pave the way for downstream applications ranging from video editing to robotic planning.
Learning rigid dynamics with face interaction graph networks
Dec 07, 2022



Simulating rigid collisions among arbitrary shapes is notoriously difficult due to complex geometry and the strong non-linearity of the interactions. While graph neural network (GNN)-based models are effective at learning to simulate complex physical dynamics, such as fluids, cloth and articulated bodies, they have been less effective and efficient on rigid-body physics, except with very simple shapes. Existing methods that model collisions through the meshes' nodes are often inaccurate because they struggle when collisions occur on faces far from nodes. Alternative approaches that represent the geometry densely with many particles are prohibitively expensive for complex shapes. Here we introduce the Face Interaction Graph Network (FIGNet) which extends beyond GNN-based methods, and computes interactions between mesh faces, rather than nodes. Compared to learned node- and particle-based methods, FIGNet is around 4x more accurate in simulating complex shape interactions, while also 8x more computationally efficient on sparse, rigid meshes. Moreover, FIGNet can learn frictional dynamics directly from real-world data, and can be more accurate than analytical solvers given modest amounts of training data. FIGNet represents a key step forward in one of the few remaining physical domains which have seen little competition from learned simulators, and offers allied fields such as robotics, graphics and mechanical design a new tool for simulation and model-based planning.
MultiScale MeshGraphNets
Oct 02, 2022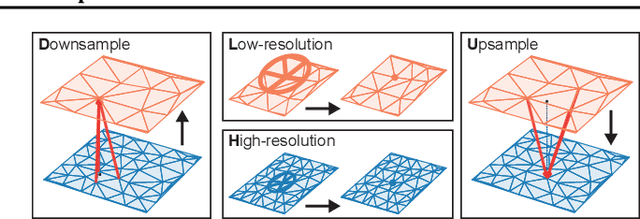
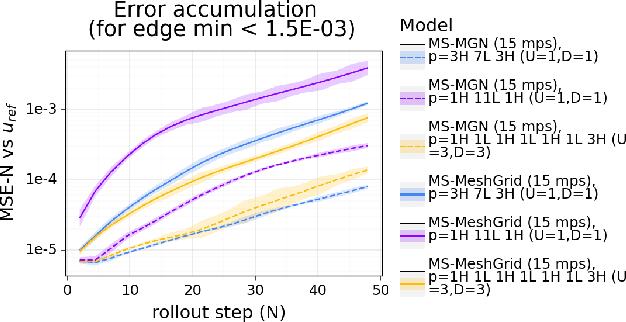
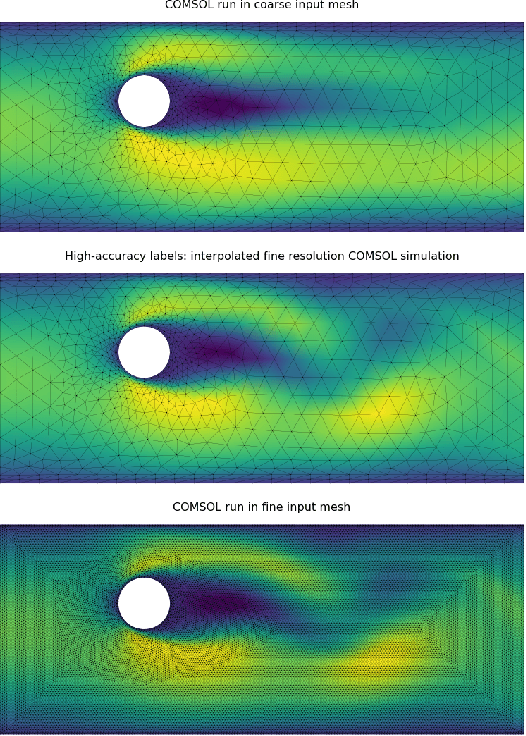
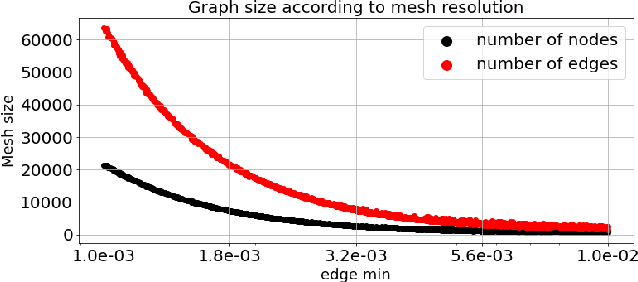
In recent years, there has been a growing interest in using machine learning to overcome the high cost of numerical simulation, with some learned models achieving impressive speed-ups over classical solvers whilst maintaining accuracy. However, these methods are usually tested at low-resolution settings, and it remains to be seen whether they can scale to the costly high-resolution simulations that we ultimately want to tackle. In this work, we propose two complementary approaches to improve the framework from MeshGraphNets, which demonstrated accurate predictions in a broad range of physical systems. MeshGraphNets relies on a message passing graph neural network to propagate information, and this structure becomes a limiting factor for high-resolution simulations, as equally distant points in space become further apart in graph space. First, we demonstrate that it is possible to learn accurate surrogate dynamics of a high-resolution system on a much coarser mesh, both removing the message passing bottleneck and improving performance; and second, we introduce a hierarchical approach (MultiScale MeshGraphNets) which passes messages on two different resolutions (fine and coarse), significantly improving the accuracy of MeshGraphNets while requiring less computational resources.
Physical Design using Differentiable Learned Simulators
Feb 01, 2022Designing physical artifacts that serve a purpose - such as tools and other functional structures - is central to engineering as well as everyday human behavior. Though automating design has tremendous promise, general-purpose methods do not yet exist. Here we explore a simple, fast, and robust approach to inverse design which combines learned forward simulators based on graph neural networks with gradient-based design optimization. Our approach solves high-dimensional problems with complex physical dynamics, including designing surfaces and tools to manipulate fluid flows and optimizing the shape of an airfoil to minimize drag. This framework produces high-quality designs by propagating gradients through trajectories of hundreds of steps, even when using models that were pre-trained for single-step predictions on data substantially different from the design tasks. In our fluid manipulation tasks, the resulting designs outperformed those found by sampling-based optimization techniques. In airfoil design, they matched the quality of those obtained with a specialized solver. Our results suggest that despite some remaining challenges, machine learning-based simulators are maturing to the point where they can support general-purpose design optimization across a variety of domains.
Learned Coarse Models for Efficient Turbulence Simulation
Jan 04, 2022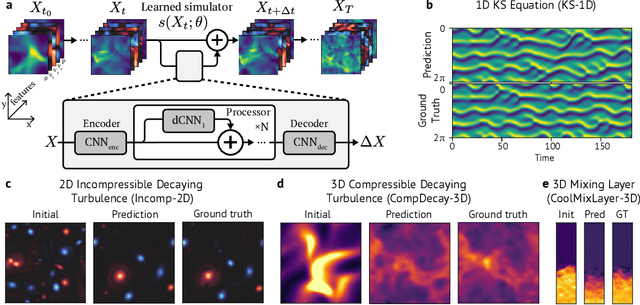
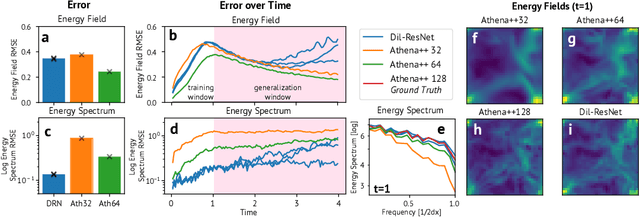
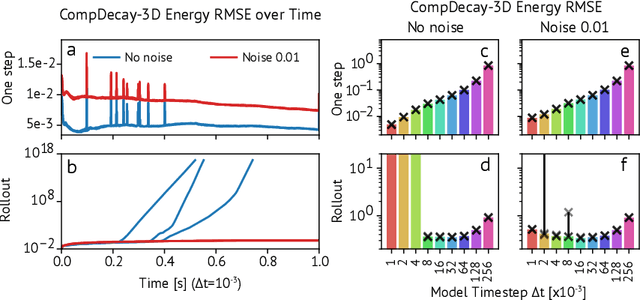

Turbulence simulation with classical numerical solvers requires very high-resolution grids to accurately resolve dynamics. Here we train learned simulators at low spatial and temporal resolutions to capture turbulent dynamics generated at high resolution. We show that our proposed model can simulate turbulent dynamics more accurately than classical numerical solvers at the same low resolutions across various scientifically relevant metrics. Our model is trained end-to-end from data and is capable of learning a range of challenging chaotic and turbulent dynamics at low resolution, including trajectories generated by the state-of-the-art Athena++ engine. We show that our simpler, general-purpose architecture outperforms various more specialized, turbulence-specific architectures from the learned turbulence simulation literature. In general, we see that learned simulators yield unstable trajectories; however, we show that tuning training noise and temporal downsampling solves this problem. We also find that while generalization beyond the training distribution is a challenge for learned models, training noise, convolutional architectures, and added loss constraints can help. Broadly, we conclude that our learned simulator outperforms traditional solvers run on coarser grids, and emphasize that simple design choices can offer stability and robust generalization.