 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning rigid dynamics with face interaction graph networks
Dec 07, 2022



Simulating rigid collisions among arbitrary shapes is notoriously difficult due to complex geometry and the strong non-linearity of the interactions. While graph neural network (GNN)-based models are effective at learning to simulate complex physical dynamics, such as fluids, cloth and articulated bodies, they have been less effective and efficient on rigid-body physics, except with very simple shapes. Existing methods that model collisions through the meshes' nodes are often inaccurate because they struggle when collisions occur on faces far from nodes. Alternative approaches that represent the geometry densely with many particles are prohibitively expensive for complex shapes. Here we introduce the Face Interaction Graph Network (FIGNet) which extends beyond GNN-based methods, and computes interactions between mesh faces, rather than nodes. Compared to learned node- and particle-based methods, FIGNet is around 4x more accurate in simulating complex shape interactions, while also 8x more computationally efficient on sparse, rigid meshes. Moreover, FIGNet can learn frictional dynamics directly from real-world data, and can be more accurate than analytical solvers given modest amounts of training data. FIGNet represents a key step forward in one of the few remaining physical domains which have seen little competition from learned simulators, and offers allied fields such as robotics, graphics and mechanical design a new tool for simulation and model-based planning.
The Challenges of Exploration for Offline Reinforcement Learning
Jan 27, 2022Offline Reinforcement Learning (ORL) enablesus to separately study the two interlinked processes of reinforcement learning: collecting informative experience and inferring optimal behaviour. The second step has been widely studied in the offline setting, but just as critical to data-efficient RL is the collection of informative data. The task-agnostic setting for data collection, where the task is not known a priori, is of particular interest due to the possibility of collecting a single dataset and using it to solve several downstream tasks as they arise. We investigate this setting via curiosity-based intrinsic motivation, a family of exploration methods which encourage the agent to explore those states or transitions it has not yet learned to model. With Explore2Offline, we propose to evaluate the quality of collected data by transferring the collected data and inferring policies with reward relabelling and standard offline RL algorithms. We evaluate a wide variety of data collection strategies, including a new exploration agent, Intrinsic Model Predictive Control (IMPC), using this scheme and demonstrate their performance on various tasks. We use this decoupled framework to strengthen intuitions about exploration and the data prerequisites for effective offline RL.
Dynamics-aware Embeddings
Sep 01, 2019
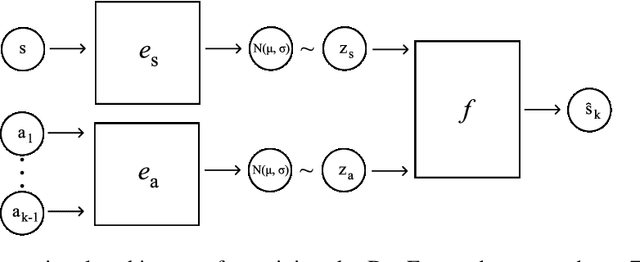
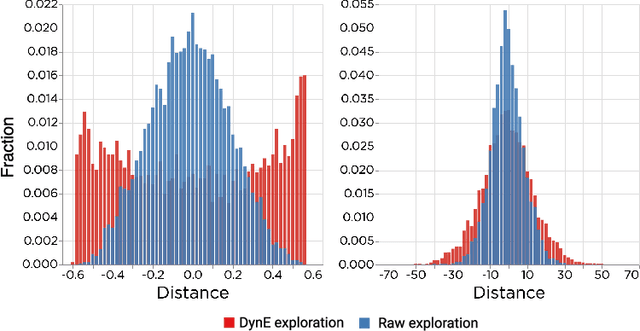
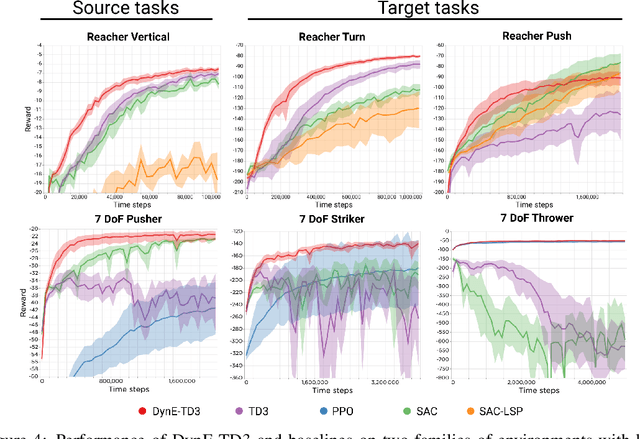
In this paper we consider self-supervised representation learning to improve sample efficiency in reinforcement learning (RL). We propose a forward prediction objective for simultaneously learning embeddings of states and actions. These embeddings capture the structure of the environment's dynamics, enabling efficient policy learning. We demonstrate that our action embeddings alone improve the sample efficiency and peak performance of model-free RL on control from low-dimensional states. By combining state and action embeddings, we achieve efficient learning of high-quality policies on goal-conditioned continuous control from pixel observations in only 1-2 million environment steps.
Disentangled Representations in Neural Models
Feb 07, 2016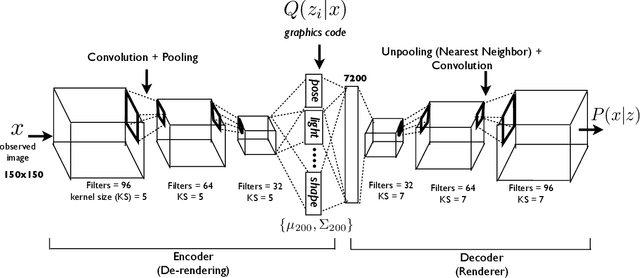


Representation learning is the foundation for the recent success of neural network models. However, the distributed representations generated by neural networks are far from ideal. Due to their highly entangled nature, they are di cult to reuse and interpret, and they do a poor job of capturing the sparsity which is present in real- world transformations. In this paper, I describe methods for learning disentangled representations in the two domains of graphics and computation. These methods allow neural methods to learn representations which are easy to interpret and reuse, yet they incur little or no penalty to performance. In the Graphics section, I demonstrate the ability of these methods to infer the generating parameters of images and rerender those images under novel conditions. In the Computation section, I describe a model which is able to factorize a multitask learning problem into subtasks and which experiences no catastrophic forgetting. Together these techniques provide the tools to design a wide range of models that learn disentangled representations and better model the factors of variation in the real world.