 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Optimization as Probabilistic Inference
Oct 05, 2024
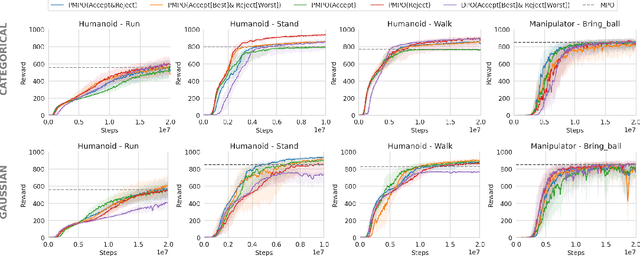
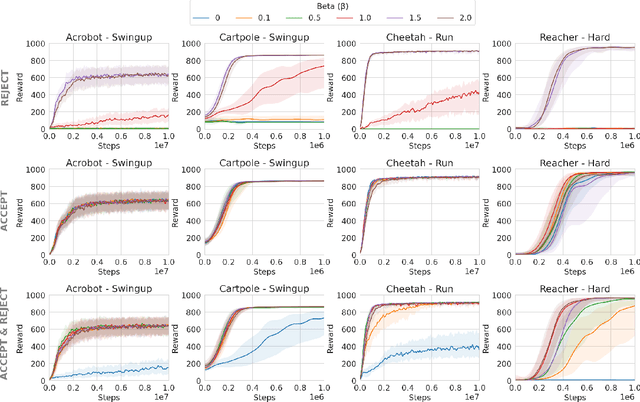
Existing preference optimization methods are mainly designed for directly learning from human feedback with the assumption that paired examples (preferred vs. dis-preferred) are available. In contrast, we propose a method that can leverage unpaired preferred or dis-preferred examples, and works even when only one type of feedback (positive or negative) is available. This flexibility allows us to apply it in scenarios with varying forms of feedback and models, including training generative language models based on human feedback as well as training policies for sequential decision-making problems, where learned (value) functions are available. Our approach builds upon the probabilistic framework introduced in (Dayan and Hinton, 1997), which proposes to use expectation-maximization (EM) to directly optimize the probability of preferred outcomes (as opposed to classic expected reward maximization). To obtain a practical algorithm, we identify and address a key limitation in current EM-based methods: when applied to preference optimization, they solely maximize the likelihood of preferred examples, while neglecting dis-preferred samples. We show how one can extend EM algorithms to explicitly incorporate dis-preferred outcomes, leading to a novel, theoretically grounded, preference optimization algorithm that offers an intuitive and versatile way to learn from both positive and negative feedback.
Mastering Stacking of Diverse Shapes with Large-Scale Iterative Reinforcement Learning on Real Robots
Dec 18, 2023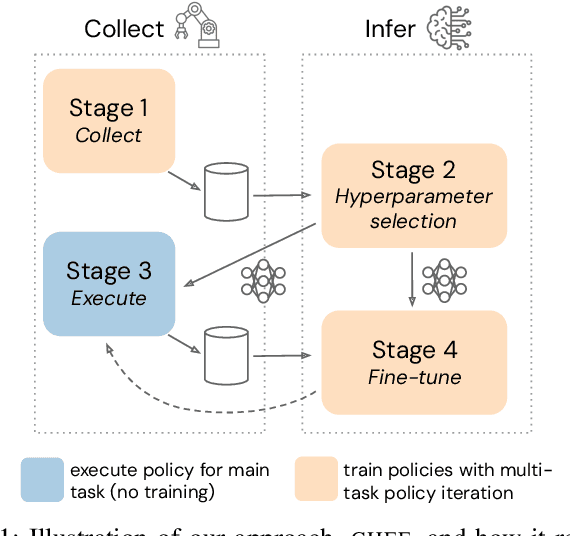


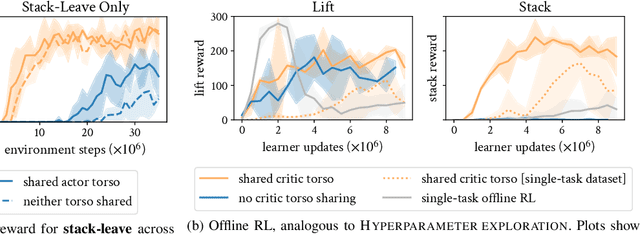
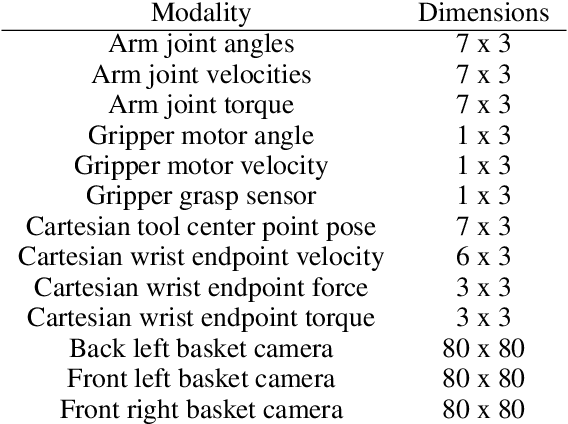
Reinforcement learning solely from an agent's self-generated data is often believed to be infeasible for learning on real robots, due to the amount of data needed. However, if done right, agents learning from real data can be surprisingly efficient through re-using previously collected sub-optimal data. In this paper we demonstrate how the increased understanding of off-policy learning methods and their embedding in an iterative online/offline scheme (``collect and infer'') can drastically improve data-efficiency by using all the collected experience, which empowers learning from real robot experience only. Moreover, the resulting policy improves significantly over the state of the art on a recently proposed real robot manipulation benchmark. Our approach learns end-to-end, directly from pixels, and does not rely on additional human domain knowledge such as a simulator or demonstrations.
Less is more -- the Dispatcher/ Executor principle for multi-task Reinforcement Learning
Dec 14, 2023Humans instinctively know how to neglect details when it comes to solve complex decision making problems in environments with unforeseeable variations. This abstraction process seems to be a vital property for most biological systems and helps to 'abstract away' unnecessary details and boost generalisation. In this work we introduce the dispatcher/ executor principle for the design of multi-task Reinforcement Learning controllers. It suggests to partition the controller in two entities, one that understands the task (the dispatcher) and one that computes the controls for the specific device (the executor) - and to connect these two by a strongly regularizing communication channel. The core rationale behind this position paper is that changes in structure and design principles can improve generalisation properties and drastically enforce data-efficiency. It is in some sense a 'yes, and ...' response to the current trend of using large neural networks trained on vast amounts of data and bet on emerging generalisation properties. While we agree on the power of scaling - in the sense of Sutton's 'bitter lesson' - we will give some evidence, that considering structure and adding design principles can be a valuable and critical component in particular when data is not abundant and infinite, but is a precious resource.
Replay across Experiments: A Natural Extension of Off-Policy RL
Nov 28, 2023



Replaying data is a principal mechanism underlying the stability and data efficiency of off-policy reinforcement learning (RL). We present an effective yet simple framework to extend the use of replays across multiple experiments, minimally adapting the RL workflow for sizeable improvements in controller performance and research iteration times. At its core, Replay Across Experiments (RaE) involves reusing experience from previous experiments to improve exploration and bootstrap learning while reducing required changes to a minimum in comparison to prior work. We empirically show benefits across a number of RL algorithms and challenging control domains spanning both locomotion and manipulation, including hard exploration tasks from egocentric vision. Through comprehensive ablations, we demonstrate robustness to the quality and amount of data available and various hyperparameter choices. Finally, we discuss how our approach can be applied more broadly across research life cycles and can increase resilience by reloading data across random seeds or hyperparameter variations.
SkillS: Adaptive Skill Sequencing for Efficient Temporally-Extended Exploration
Dec 03, 2022


The ability to effectively reuse prior knowledge is a key requirement when building general and flexible Reinforcement Learning (RL) agents. Skill reuse is one of the most common approaches, but current methods have considerable limitations.For example, fine-tuning an existing policy frequently fails, as the policy can degrade rapidly early in training. In a similar vein, distillation of expert behavior can lead to poor results when given sub-optimal experts. We compare several common approaches for skill transfer on multiple domains including changes in task and system dynamics. We identify how existing methods can fail and introduce an alternative approach to mitigate these problems. Our approach learns to sequence existing temporally-extended skills for exploration but learns the final policy directly from the raw experience. This conceptual split enables rapid adaptation and thus efficient data collection but without constraining the final solution.It significantly outperforms many classical methods across a suite of evaluation tasks and we use a broad set of ablations to highlight the importance of differentc omponents of our method.
The Challenges of Exploration for Offline Reinforcement Learning
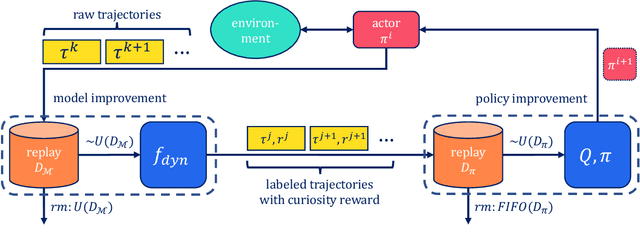
Jan 27, 2022Offline Reinforcement Learning (ORL) enablesus to separately study the two interlinked processes of reinforcement learning: collecting informative experience and inferring optimal behaviour. The second step has been widely studied in the offline setting, but just as critical to data-efficient RL is the collection of informative data. The task-agnostic setting for data collection, where the task is not known a priori, is of particular interest due to the possibility of collecting a single dataset and using it to solve several downstream tasks as they arise. We investigate this setting via curiosity-based intrinsic motivation, a family of exploration methods which encourage the agent to explore those states or transitions it has not yet learned to model. With Explore2Offline, we propose to evaluate the quality of collected data by transferring the collected data and inferring policies with reward relabelling and standard offline RL algorithms. We evaluate a wide variety of data collection strategies, including a new exploration agent, Intrinsic Model Predictive Control (IMPC), using this scheme and demonstrate their performance on various tasks. We use this decoupled framework to strengthen intuitions about exploration and the data prerequisites for effective offline RL.
Is Curiosity All You Need? On the Utility of Emergent Behaviours from Curious Exploration
Sep 17, 2021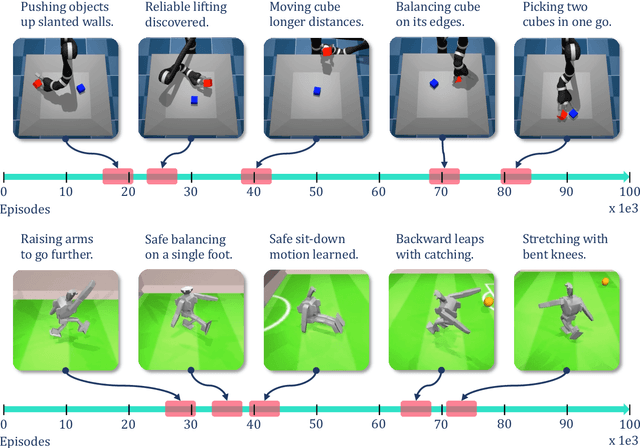


Curiosity-based reward schemes can present powerful exploration mechanisms which facilitate the discovery of solutions for complex, sparse or long-horizon tasks. However, as the agent learns to reach previously unexplored spaces and the objective adapts to reward new areas, many behaviours emerge only to disappear due to being overwritten by the constantly shifting objective. We argue that merely using curiosity for fast environment exploration or as a bonus reward for a specific task does not harness the full potential of this technique and misses useful skills. Instead, we propose to shift the focus towards retaining the behaviours which emerge during curiosity-based learning. We posit that these self-discovered behaviours serve as valuable skills in an agent's repertoire to solve related tasks. Our experiments demonstrate the continuous shift in behaviour throughout training and the benefits of a simple policy snapshot method to reuse discovered behaviour for transfer tasks.
Representation Matters: Improving Perception and Exploration for Robotics
Nov 03, 2020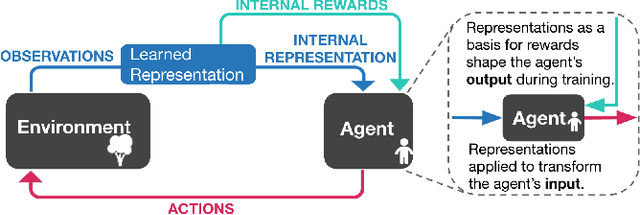
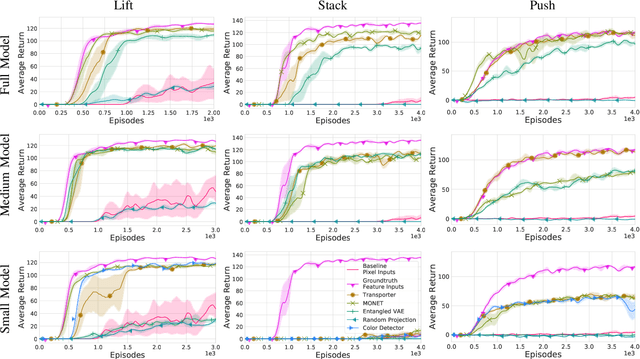
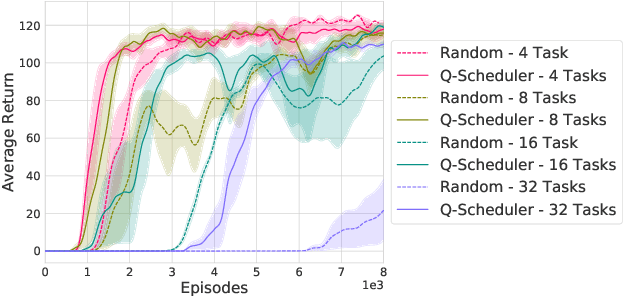

Projecting high-dimensional environment observations into lower-dimensional structured representations can considerably improve data-efficiency for reinforcement learning in domains with limited data such as robotics. Can a single generally useful representation be found? In order to answer this question, it is important to understand how the representation will be used by the agent and what properties such a 'good' representation should have. In this paper we systematically evaluate a number of common learnt and hand-engineered representations in the context of three robotics tasks: lifting, stacking and pushing of 3D blocks. The representations are evaluated in two use-cases: as input to the agent, or as a source of auxiliary tasks. Furthermore, the value of each representation is evaluated in terms of three properties: dimensionality, observability and disentanglement. We can significantly improve performance in both use-cases and demonstrate that some representations can perform commensurate to simulator states as agent inputs. Finally, our results challenge common intuitions by demonstrating that: 1) dimensionality strongly matters for task generation, but is negligible for inputs, 2) observability of task-relevant aspects mostly affects the input representation use-case, and 3) disentanglement leads to better auxiliary tasks, but has only limited benefits for input representations. This work serves as a step towards a more systematic understanding of what makes a 'good' representation for control in robotics, enabling practitioners to make more informed choices for developing new learned or hand-engineered representations.
Towards General and Autonomous Learning of Core Skills: A Case Study in Locomotion
Aug 06, 2020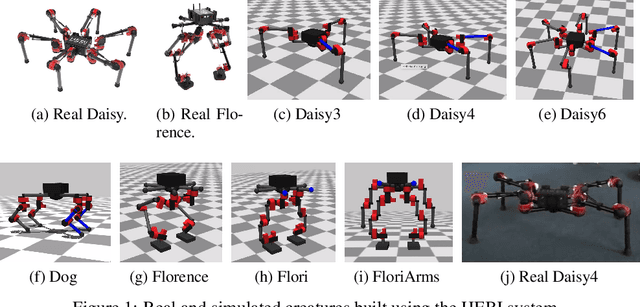
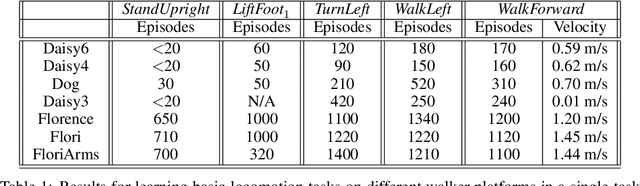
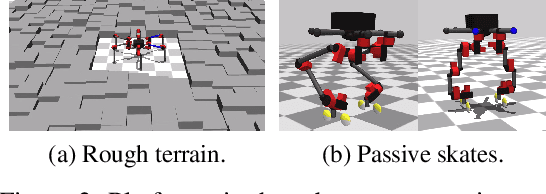

Modern Reinforcement Learning (RL) algorithms promise to solve difficult motor control problems directly from raw sensory inputs. Their attraction is due in part to the fact that they can represent a general class of methods that allow to learn a solution with a reasonably set reward and minimal prior knowledge, even in situations where it is difficult or expensive for a human expert. For RL to truly make good on this promise, however, we need algorithms and learning setups that can work across a broad range of problems with minimal problem specific adjustments or engineering. In this paper, we study this idea of generality in the locomotion domain. We develop a learning framework that can learn sophisticated locomotion behavior for a wide spectrum of legged robots, such as bipeds, tripeds, quadrupeds and hexapods, including wheeled variants. Our learning framework relies on a data-efficient, off-policy multi-task RL algorithm and a small set of reward functions that are semantically identical across robots. To underline the general applicability of the method, we keep the hyper-parameter settings and reward definitions constant across experiments and rely exclusively on on-board sensing. For nine different types of robots, including a real-world quadruped robot, we demonstrate that the same algorithm can rapidly learn diverse and reusable locomotion skills without any platform specific adjustments or additional instrumentation of the learning setup.
Data-efficient Hindsight Off-policy Option Learning
Jul 30, 2020
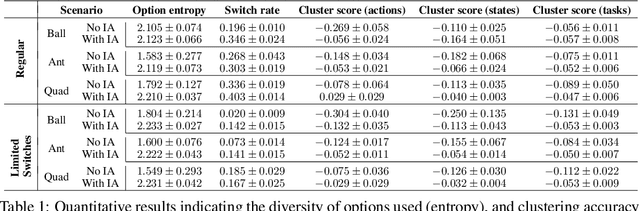


Solutions to most complex tasks can be decomposed into simpler, intermediate skills, reusable across wider ranges of problems. We follow this concept and introduce Hindsight Off-policy Options (HO2), a new algorithm for efficient and robust option learning. The algorithm relies on critic-weighted maximum likelihood estimation and an efficient dynamic programming inference procedure over off-policy trajectories. We can backpropagate through the inference procedure through time and the policy components for every time-step, making it possible to train all component's parameters off-policy, independently of the data-generating behavior policy. Experimentally, we demonstrate that HO2 outperforms competitive baselines and solves demanding robot stacking and ball-in-cup tasks from raw pixel inputs in simulation. We further compare autoregressive option policies with simple mixture policies, providing insights into the relative impact of two types of abstractions common in the options framework: action abstraction and temporal abstraction. Finally, we illustrate challenges caused by stale data in off-policy options learning and provide effective solutions.