 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving math word problems with process- and outcome-based feedback
Nov 25, 2022



Recent work has shown that asking language models to generate reasoning steps improves performance on many reasoning tasks. When moving beyond prompting, this raises the question of how we should supervise such models: outcome-based approaches which supervise the final result, or process-based approaches which supervise the reasoning process itself? Differences between these approaches might naturally be expected not just in final-answer errors but also in reasoning errors, which can be difficult to detect and are problematic in many real-world domains such as education. We run the first comprehensive comparison between process- and outcome-based approaches trained on a natural language task, GSM8K. We find that pure outcome-based supervision produces similar final-answer error rates with less label supervision. However, for correct reasoning steps we find it necessary to use process-based supervision or supervision from learned reward models that emulate process-based feedback. In total, we improve the previous best results from 16.8% $\to$ 12.7% final-answer error and 14.0% $\to$ 3.4% reasoning error among final-answer-correct solutions.
Imitate and Repurpose: Learning Reusable Robot Movement Skills From Human and Animal Behaviors
Mar 31, 2022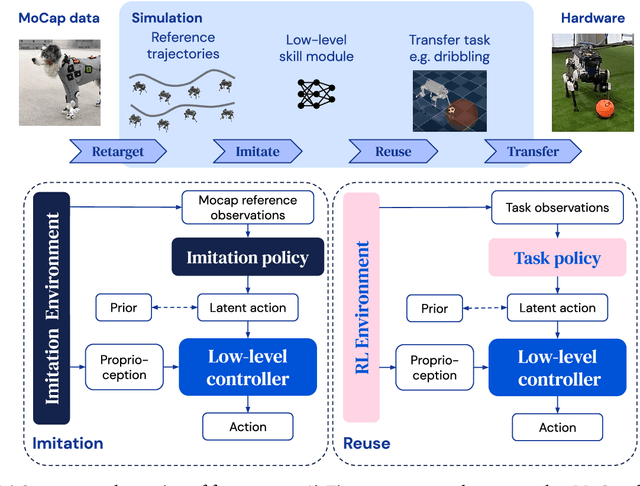

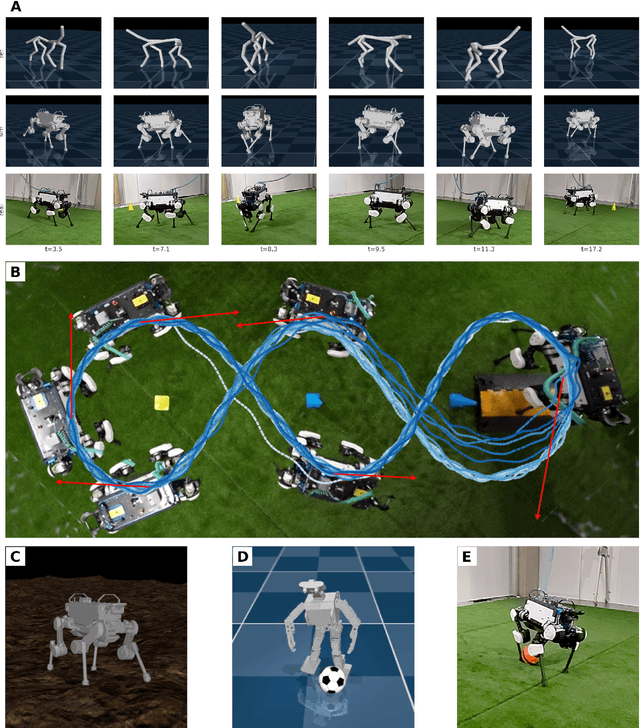
We investigate the use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach builds upon previous work on imitating human or dog Motion Capture (MoCap) data to learn a movement skill module. Once learned, this skill module can be reused for complex downstream tasks. Importantly, due to the prior imposed by the MoCap data, our approach does not require extensive reward engineering to produce sensible and natural looking behavior at the time of reuse. This makes it easy to create well-regularized, task-oriented controllers that are suitable for deployment on real robots. We demonstrate how our skill module can be used for imitation, and train controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. These policies are then deployed on hardware via zero-shot simulation-to-reality transfer. Accompanying videos are available at https://bit.ly/robot-npmp.
"What, not how": Solving an under-actuated insertion task from scratch
Oct 30, 2020

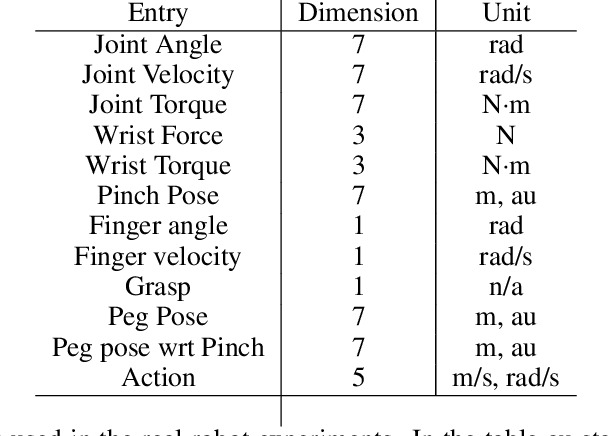
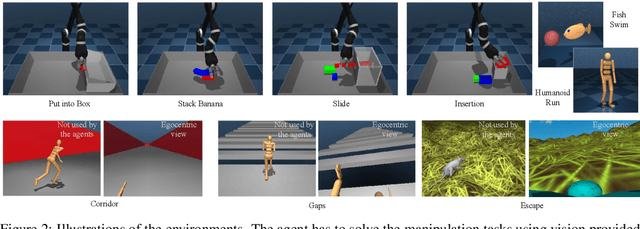
Robot manipulation requires a complex set of skills that need to be carefully combined and coordinated to solve a task. Yet, most ReinforcementLearning (RL) approaches in robotics study tasks which actually consist only of a single manipulation skill, such as grasping an object or inserting a pre-grasped object. As a result the skill ('how' to solve the task) but not the actual goal of a complete manipulation ('what' to solve) is specified. In contrast, we study a complex manipulation goal that requires an agent to learn and combine diverse manipulation skills. We propose a challenging, highly under-actuated peg-in-hole task with a free, rotational asymmetrical peg, requiring a broad range of manipulation skills. While correct peg (re-)orientation is a requirement for successful insertion, there is no reward associated with it. Hence an agent needs to understand this pre-condition and learn the skill to fulfil it. The final insertion reward is sparse, allowing freedom in the solution and leading to complex emerging behaviour not envisioned during the task design. We tackle the problem in a multi-task RL framework using Scheduled Auxiliary Control (SAC-X) combined with Regularized Hierarchical Policy Optimization (RHPO) which successfully solves the task in simulation and from scratch on a single robot where data is severely limited.
Data-efficient Hindsight Off-policy Option Learning
Jul 30, 2020
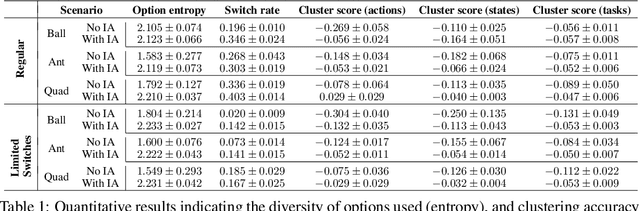


Solutions to most complex tasks can be decomposed into simpler, intermediate skills, reusable across wider ranges of problems. We follow this concept and introduce Hindsight Off-policy Options (HO2), a new algorithm for efficient and robust option learning. The algorithm relies on critic-weighted maximum likelihood estimation and an efficient dynamic programming inference procedure over off-policy trajectories. We can backpropagate through the inference procedure through time and the policy components for every time-step, making it possible to train all component's parameters off-policy, independently of the data-generating behavior policy. Experimentally, we demonstrate that HO2 outperforms competitive baselines and solves demanding robot stacking and ball-in-cup tasks from raw pixel inputs in simulation. We further compare autoregressive option policies with simple mixture policies, providing insights into the relative impact of two types of abstractions common in the options framework: action abstraction and temporal abstraction. Finally, we illustrate challenges caused by stale data in off-policy options learning and provide effective solutions.
Critic Regularized Regression
Jun 26, 2020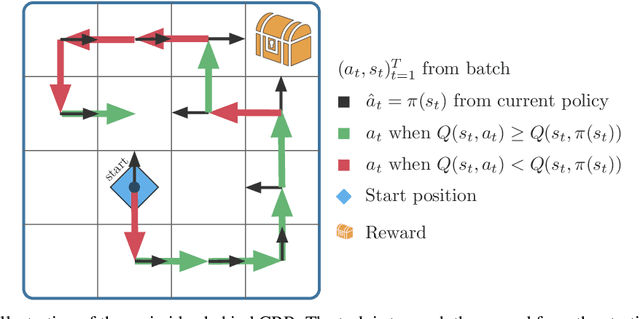

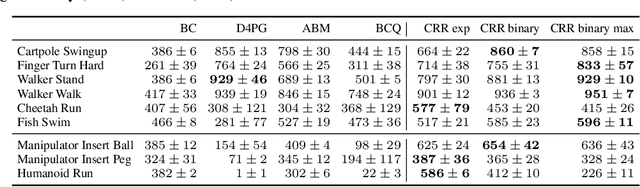
Offline reinforcement learning (RL), also known as batch RL, offers the prospect of policy optimization from large pre-recorded datasets without online environment interaction. It addresses challenges with regard to the cost of data collection and safety, both of which are particularly pertinent to real-world applications of RL. Unfortunately, most off-policy algorithms perform poorly when learning from a fixed dataset. In this paper, we propose a novel offline RL algorithm to learn policies from data using a form of critic-regularized regression (CRR). We find that CRR performs surprisingly well and scales to tasks with high-dimensional state and action spaces -- outperforming several state-of-the-art offline RL algorithms by a significant margin on a wide range of benchmark tasks.
Simple Sensor Intentions for Exploration
May 15, 2020
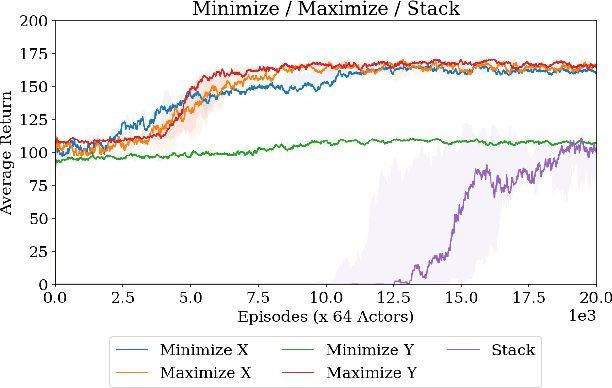
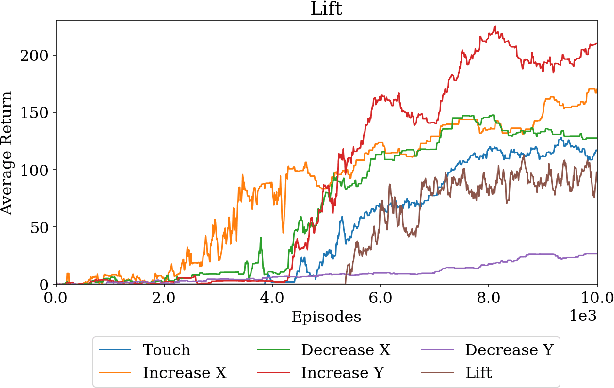
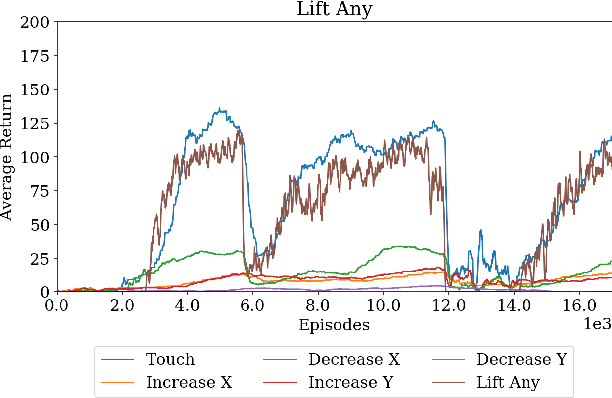
Modern reinforcement learning algorithms can learn solutions to increasingly difficult control problems while at the same time reduce the amount of prior knowledge needed for their application. One of the remaining challenges is the definition of reward schemes that appropriately facilitate exploration without biasing the solution in undesirable ways, and that can be implemented on real robotic systems without expensive instrumentation. In this paper we focus on a setting in which goal tasks are defined via simple sparse rewards, and exploration is facilitated via agent-internal auxiliary tasks. We introduce the idea of simple sensor intentions (SSIs) as a generic way to define auxiliary tasks. SSIs reduce the amount of prior knowledge that is required to define suitable rewards. They can further be computed directly from raw sensor streams and thus do not require expensive and possibly brittle state estimation on real systems. We demonstrate that a learning system based on these rewards can solve complex robotic tasks in simulation and in real world settings. In particular, we show that a real robotic arm can learn to grasp and lift and solve a Ball-in-a-Cup task from scratch, when only raw sensor streams are used for both controller input and in the auxiliary reward definition.
Imagined Value Gradients: Model-Based Policy Optimization with Transferable Latent Dynamics Models
Oct 09, 2019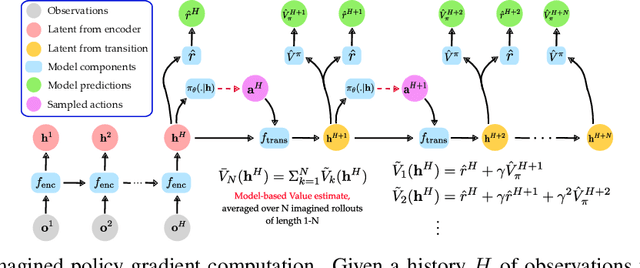



Humans are masters at quickly learning many complex tasks, relying on an approximate understanding of the dynamics of their environments. In much the same way, we would like our learning agents to quickly adapt to new tasks. In this paper, we explore how model-based Reinforcement Learning (RL) can facilitate transfer to new tasks. We develop an algorithm that learns an action-conditional, predictive model of expected future observations, rewards and values from which a policy can be derived by following the gradient of the estimated value along imagined trajectories. We show how robust policy optimization can be achieved in robot manipulation tasks even with approximate models that are learned directly from vision and proprioception. We evaluate the efficacy of our approach in a transfer learning scenario, re-using previously learned models on tasks with different reward structures and visual distractors, and show a significant improvement in learning speed compared to strong off-policy baselines. Videos with results can be found at https://sites.google.com/view/ivg-corl19
Regularized Hierarchical Policies for Compositional Transfer in Robotics
Jun 27, 2019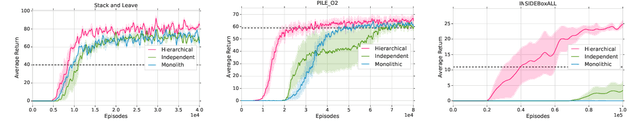

The successful application of flexible, general learning algorithms -- such as deep reinforcement learning -- to real-world robotics applications is often limited by their poor data-efficiency. Domains with more than a single dominant task of interest encourage algorithms that share partial solutions across tasks to limit the required experiment time. We develop and investigate simple hierarchical inductive biases -- in the form of structured policies -- as a mechanism for knowledge transfer across tasks in reinforcement learning (RL). To leverage the power of these structured policies we design an RL algorithm that enables stable and fast learning. We demonstrate the success of our method both in simulated robot environments (using locomotion and manipulation domains) as well as real robot experiments, demonstrating substantially better data-efficiency than competitive baselines.
Extracting Scientific Figures with Distantly Supervised Neural Networks
May 30, 2018
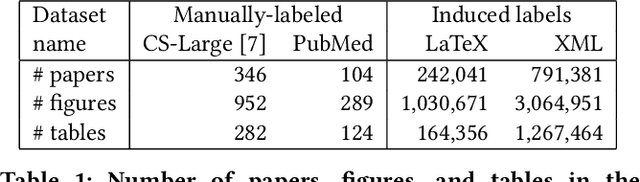
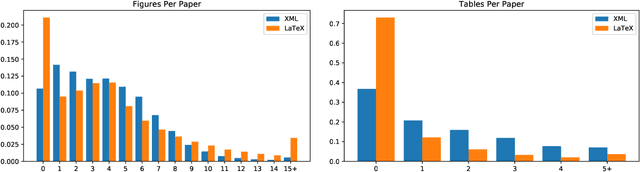
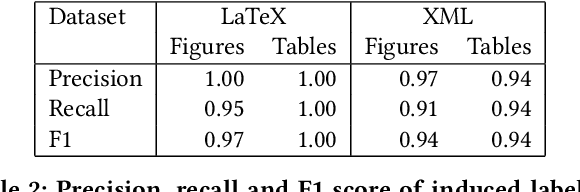
Non-textual components such as charts, diagrams and tables provide key information in many scientific documents, but the lack of large labeled datasets has impeded the development of data-driven methods for scientific figure extraction. In this paper, we induce high-quality training labels for the task of figure extraction in a large number of scientific documents, with no human intervention. To accomplish this we leverage the auxiliary data provided in two large web collections of scientific documents (arXiv and PubMed) to locate figures and their associated captions in the rasterized PDF. We share the resulting dataset of over 5.5 million induced labels---4,000 times larger than the previous largest figure extraction dataset---with an average precision of 96.8%, to enable the development of modern data-driven methods for this task. We use this dataset to train a deep neural network for end-to-end figure detection, yielding a model that can be more easily extended to new domains compared to previous work. The model was successfully deployed in Semantic Scholar, a large-scale academic search engine, and used to extract figures in 13 million scientific documents.