 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Solving math word problems with process- and outcome-based feedback
Nov 25, 2022



Recent work has shown that asking language models to generate reasoning steps improves performance on many reasoning tasks. When moving beyond prompting, this raises the question of how we should supervise such models: outcome-based approaches which supervise the final result, or process-based approaches which supervise the reasoning process itself? Differences between these approaches might naturally be expected not just in final-answer errors but also in reasoning errors, which can be difficult to detect and are problematic in many real-world domains such as education. We run the first comprehensive comparison between process- and outcome-based approaches trained on a natural language task, GSM8K. We find that pure outcome-based supervision produces similar final-answer error rates with less label supervision. However, for correct reasoning steps we find it necessary to use process-based supervision or supervision from learned reward models that emulate process-based feedback. In total, we improve the previous best results from 16.8% $\to$ 12.7% final-answer error and 14.0% $\to$ 3.4% reasoning error among final-answer-correct solutions.
Interpreting Spatially Infinite Generative Models
Jul 24, 2020
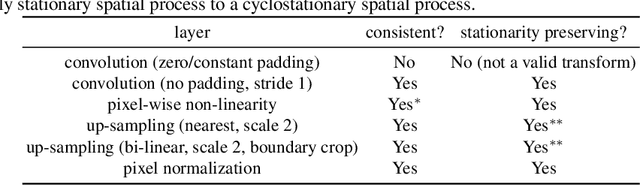
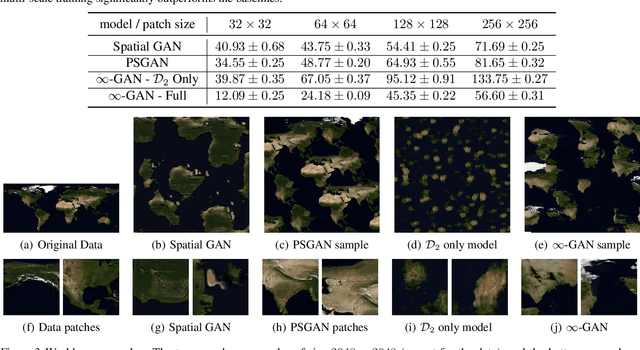
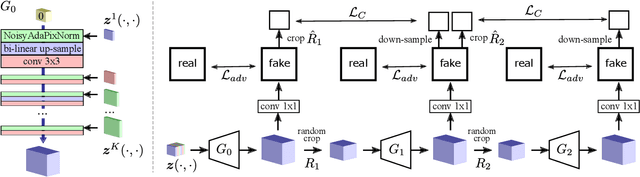
Traditional deep generative models of images and other spatial modalities can only generate fixed sized outputs. The generated images have exactly the same resolution as the training images, which is dictated by the number of layers in the underlying neural network. Recent work has shown, however, that feeding spatial noise vectors into a fully convolutional neural network enables both generation of arbitrary resolution output images as well as training on arbitrary resolution training images. While this work has provided impressive empirical results, little theoretical interpretation was provided to explain the underlying generative process. In this paper we provide a firm theoretical interpretation for infinite spatial generation, by drawing connections to spatial stochastic processes. We use the resulting intuition to improve upon existing spatially infinite generative models to enable more efficient training through a model that we call an infinite generative adversarial network, or $\infty$-GAN. Experiments on world map generation, panoramic images and texture synthesis verify the ability of $\infty$-GAN to efficiently generate images of arbitrary size.
Inverse Graphics GAN: Learning to Generate 3D Shapes from Unstructured 2D Data
Feb 28, 2020

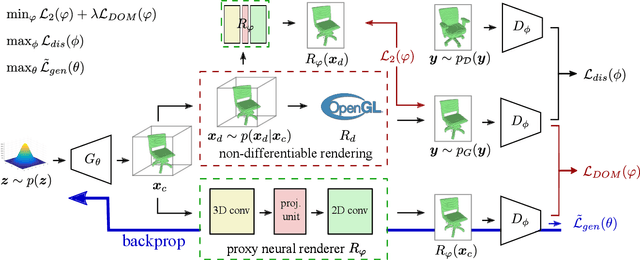

Recent work has shown the ability to learn generative models for 3D shapes from only unstructured 2D images. However, training such models requires differentiating through the rasterization step of the rendering process, therefore past work has focused on developing bespoke rendering models which smooth over this non-differentiable process in various ways. Such models are thus unable to take advantage of the photo-realistic, fully featured, industrial renderers built by the gaming and graphics industry. In this paper we introduce the first scalable training technique for 3D generative models from 2D data which utilizes an off-the-shelf non-differentiable renderer. To account for the non-differentiability, we introduce a proxy neural renderer to match the output of the non-differentiable renderer. We further propose discriminator output matching to ensure that the neural renderer learns to smooth over the rasterization appropriately. We evaluate our model on images rendered from our generated 3D shapes, and show that our model can consistently learn to generate better shapes than existing models when trained with exclusively unstructured 2D images.
Learning Robust Representations via Multi-View Information Bottleneck
Feb 18, 2020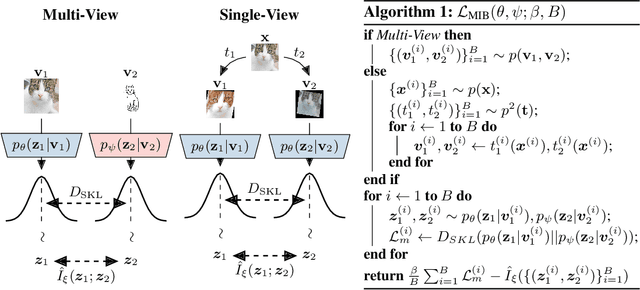
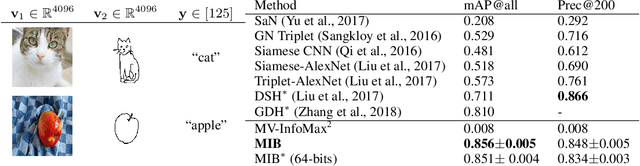
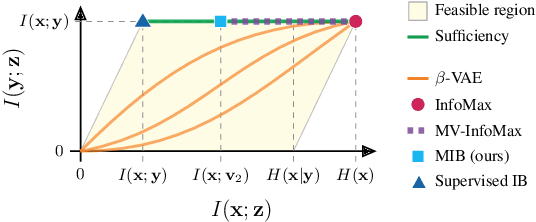

The information bottleneck principle provides an information-theoretic method for representation learning, by training an encoder to retain all information which is relevant for predicting the label while minimizing the amount of other, excess information in the representation. The original formulation, however, requires labeled data to identify the superfluous information. In this work, we extend this ability to the multi-view unsupervised setting, where two views of the same underlying entity are provided but the label is unknown. This enables us to identify superfluous information as that not shared by both views. A theoretical analysis leads to the definition of a new multi-view model that produces state-of-the-art results on the Sketchy dataset and label-limited versions of the MIR-Flickr dataset. We also extend our theory to the single-view setting by taking advantage of standard data augmentation techniques, empirically showing better generalization capabilities when compared to common unsupervised approaches for representation learning.
Constructing Unrestricted Adversarial Examples with Generative Models
Sep 20, 2018


Adversarial examples are typically constructed by perturbing an existing data point within a small matrix norm, and current defense methods are focused on guarding against this type of attack. In this paper, we propose a new class of adversarial examples that are synthesized entirely from scratch using a conditional generative model, without being restricted to norm-bounded perturbations. We first train an Auxiliary Classifier Generative Adversarial Network (AC-GAN) to model the class-conditional distribution over inputs. Then, conditioned on a desired class, we search over the AC-GAN latent space to find images that are likely under the generative model and are misclassified by a target classifier. We demonstrate through human evaluation that this new kind of adversarial images, which we call Generative Adversarial Examples, are legitimate and belong to the desired class. Our empirical results on the MNIST, SVHN, and CelebA datasets show that generative adversarial examples can easily bypass strong adversarial training and certified defense methods which can foil existing adversarial attacks.
Inverting Supervised Representations with Autoregressive Neural Density Models
Jun 01, 2018



Understanding the nature of representations learned by supervised machine learning models is a significant goal in the machine learning community. We present a method for feature interpretation that makes use of recent advances in autoregressive density estimation models to invert model representations. We train generative inversion models to express a distribution over input features conditioned on intermediate model representations. Insights into the invariances learned by supervised models can be gained by viewing samples from these inversion models. In addition, we can use these inversion models to estimate the mutual information between a model's inputs and its intermediate representations, thus quantifying the amount of information preserved by the network at different stages. Using this method we examine the types of information preserved at different layers of convolutional neural networks, and explore the invariances induced by different architectural choices. Finally we show that the mutual information between inputs and network layers decreases over the course of training, supporting recent work by Shwartz-Ziv and Tishby (2017) on the information bottleneck theory of deep learning.
PixelDefend: Leveraging Generative Models to Understand and Defend against Adversarial Examples
May 21, 2018
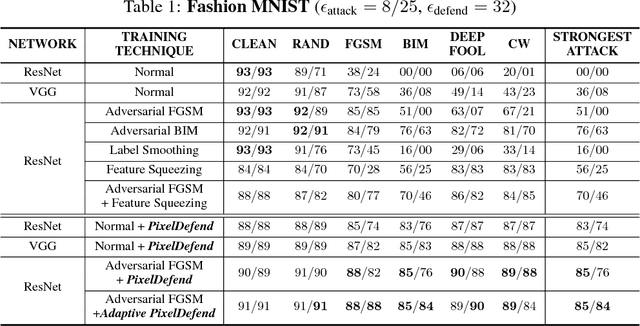
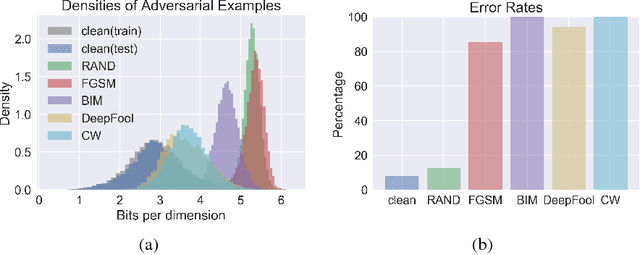
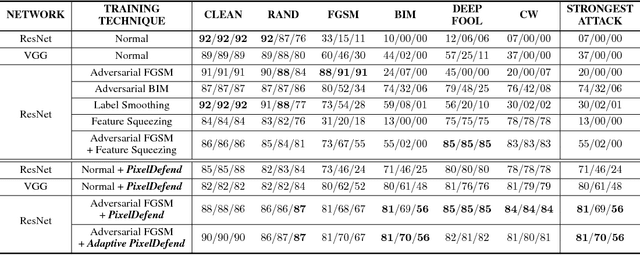
Adversarial perturbations of normal images are usually imperceptible to humans, but they can seriously confuse state-of-the-art machine learning models. What makes them so special in the eyes of image classifiers? In this paper, we show empirically that adversarial examples mainly lie in the low probability regions of the training distribution, regardless of attack types and targeted models. Using statistical hypothesis testing, we find that modern neural density models are surprisingly good at detecting imperceptible image perturbations. Based on this discovery, we devised PixelDefend, a new approach that purifies a maliciously perturbed image by moving it back towards the distribution seen in the training data. The purified image is then run through an unmodified classifier, making our method agnostic to both the classifier and the attacking method. As a result, PixelDefend can be used to protect already deployed models and be combined with other model-specific defenses. Experiments show that our method greatly improves resilience across a wide variety of state-of-the-art attacking methods, increasing accuracy on the strongest attack from 63% to 84% for Fashion MNIST and from 32% to 70% for CIFAR-10.
A Deep Learning Approach for Joint Video Frame and Reward Prediction in Atari Games
Aug 17, 2017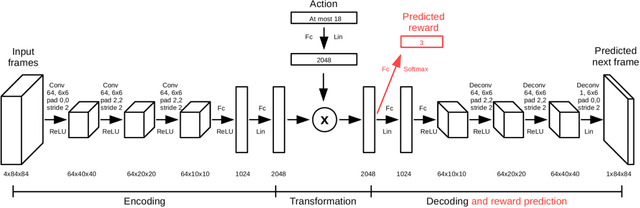
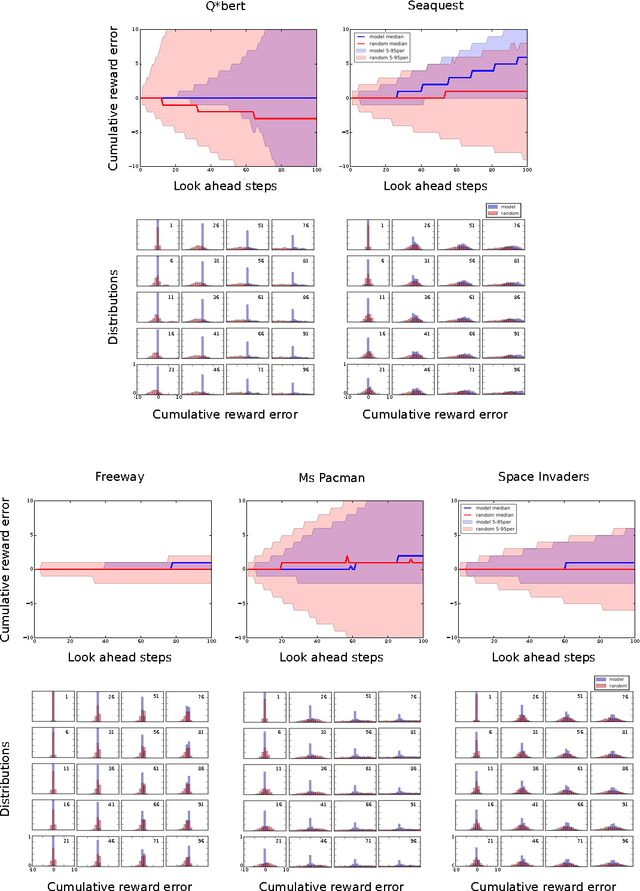

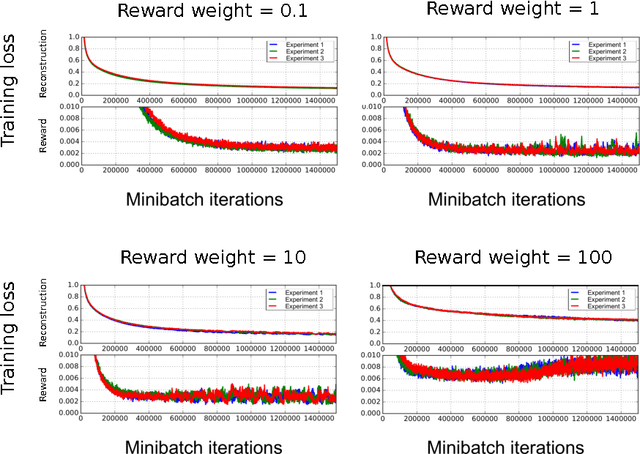
Reinforcement learning is concerned with identifying reward-maximizing behaviour policies in environments that are initially unknown. State-of-the-art reinforcement learning approaches, such as deep Q-networks, are model-free and learn to act effectively across a wide range of environments such as Atari games, but require huge amounts of data. Model-based techniques are more data-efficient, but need to acquire explicit knowledge about the environment. In this paper, we take a step towards using model-based techniques in environments with a high-dimensional visual state space by demonstrating that it is possible to learn system dynamics and the reward structure jointly. Our contribution is to extend a recently developed deep neural network for video frame prediction in Atari games to enable reward prediction as well. To this end, we phrase a joint optimization problem for minimizing both video frame and reward reconstruction loss, and adapt network parameters accordingly. Empirical evaluations on five Atari games demonstrate accurate cumulative reward prediction of up to 200 frames. We consider these results as opening up important directions for model-based reinforcement learning in complex, initially unknown environments.
Differentiable Programs with Neural Libraries
Mar 02, 2017
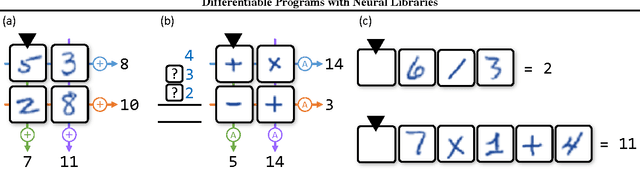

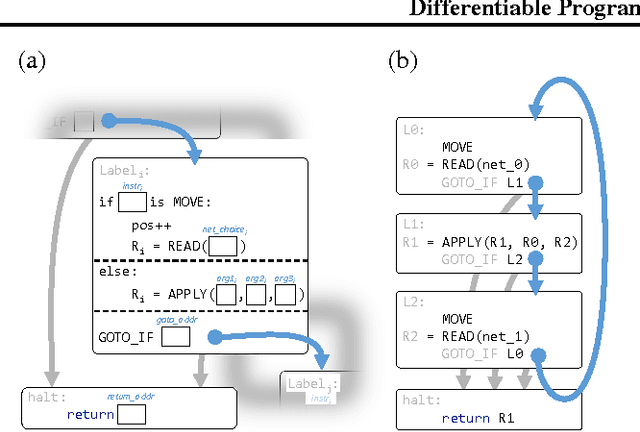
We develop a framework for combining differentiable programming languages with neural networks. Using this framework we create end-to-end trainable systems that learn to write interpretable algorithms with perceptual components. We explore the benefits of inductive biases for strong generalization and modularity that come from the program-like structure of our models. In particular, modularity allows us to learn a library of (neural) functions which grows and improves as more tasks are solved. Empirically, we show that this leads to lifelong learning systems that transfer knowledge to new tasks more effectively than baselines.