 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Approach for Joint Video Frame and Reward Prediction in Atari Games
Paper and Code
Aug 17, 2017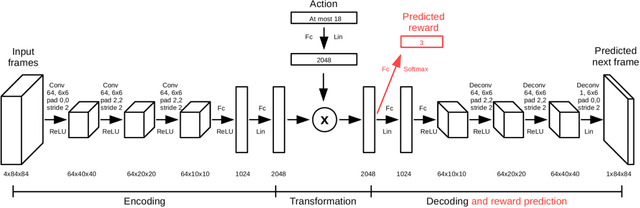
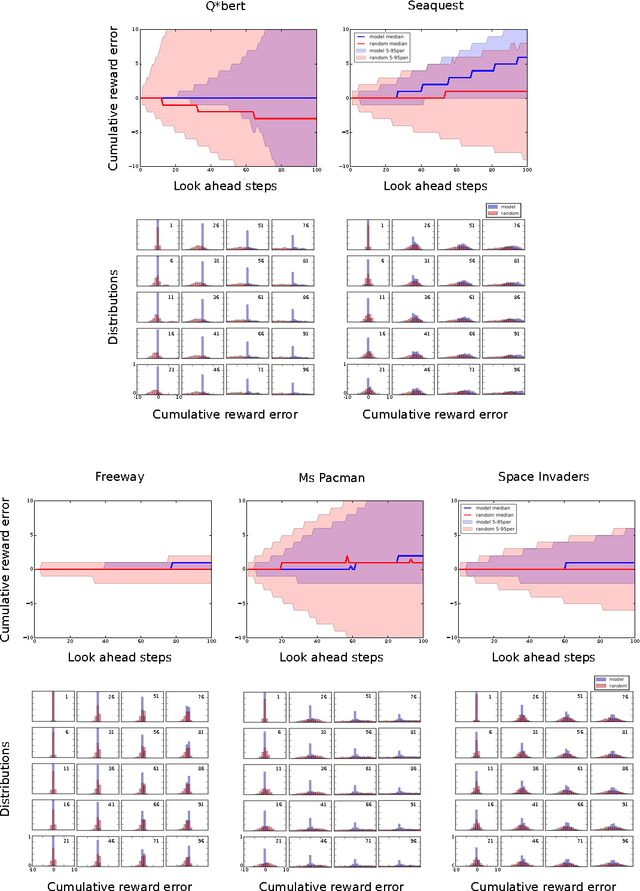

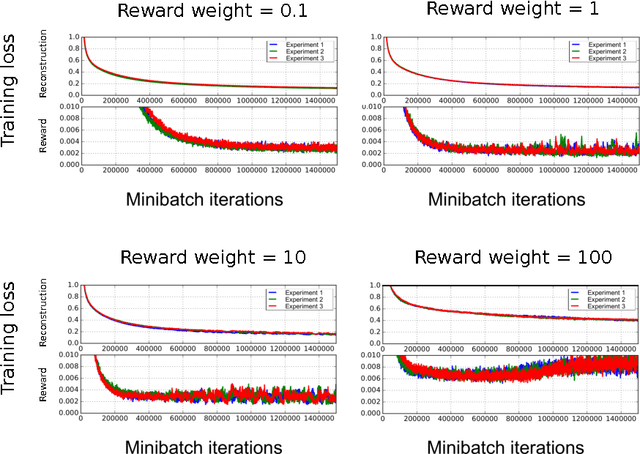
Reinforcement learning is concerned with identifying reward-maximizing behaviour policies in environments that are initially unknown. State-of-the-art reinforcement learning approaches, such as deep Q-networks, are model-free and learn to act effectively across a wide range of environments such as Atari games, but require huge amounts of data. Model-based techniques are more data-efficient, but need to acquire explicit knowledge about the environment. In this paper, we take a step towards using model-based techniques in environments with a high-dimensional visual state space by demonstrating that it is possible to learn system dynamics and the reward structure jointly. Our contribution is to extend a recently developed deep neural network for video frame prediction in Atari games to enable reward prediction as well. To this end, we phrase a joint optimization problem for minimizing both video frame and reward reconstruction loss, and adapt network parameters accordingly. Empirical evaluations on five Atari games demonstrate accurate cumulative reward prediction of up to 200 frames. We consider these results as opening up important directions for model-based reinforcement learning in complex, initially unknown environments.