 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Invisible Hand of Physics: When Video Diffusion Models Know More Than They Show
Jun 03, 2026Modern video diffusion models generate increasingly realistic and temporally coherent videos, motivating their use as candidate world simulators. Yet it remains unclear whether these models internally encode physical structure, or merely reproduce motion patterns seen during training. We study this question by probing video diffusion models along latent trajectories corresponding to real videos with known physical plausibility. To obtain such trajectories, we approximately invert the deterministic sampling process by integrating the learned velocity field backward from a clean video latent to noise, giving access to the model's intermediate states and attention maps. Using these recovered trajectories, we show that physical plausibility is linearly decodable from diffusion transformer states across IntPhys and InfLevel, reaching around 81.27% average accuracy and outperforming dedicated representation-learning baselines such as V-JEPA and VideoMAE. Surprisingly, this signal is absent from the VAE latent input and emerges inside the denoising transformer itself, despite the model not being trained with a self-supervised predictive objective. These findings suggest that physically meaningful representations can arise as a byproduct of generative denoising.
When does predictive inverse dynamics outperform behavior cloning?
Jan 29, 2026Behavior cloning (BC) is a practical offline imitation learning method, but it often fails when expert demonstrations are limited. Recent works have introduced a class of architectures named predictive inverse dynamics models (PIDM) that combine a future state predictor with an inverse dynamics model (IDM). While PIDM often outperforms BC, the reasons behind its benefits remain unclear. In this paper, we provide a theoretical explanation: PIDM introduces a bias-variance tradeoff. While predicting the future state introduces bias, conditioning the IDM on the prediction can significantly reduce variance. We establish conditions on the state predictor bias for PIDM to achieve lower prediction error and higher sample efficiency than BC, with the gap widening when additional data sources are available. We validate the theoretical insights empirically in 2D navigation tasks, where BC requires up to five times (three times on average) more demonstrations than PIDM to reach comparable performance; and in a complex 3D environment in a modern video game with high-dimensional visual inputs and stochastic transitions, where BC requires over 66\% more samples than PIDM.
Fast Autoregressive Video Generation with Diagonal Decoding
Mar 18, 2025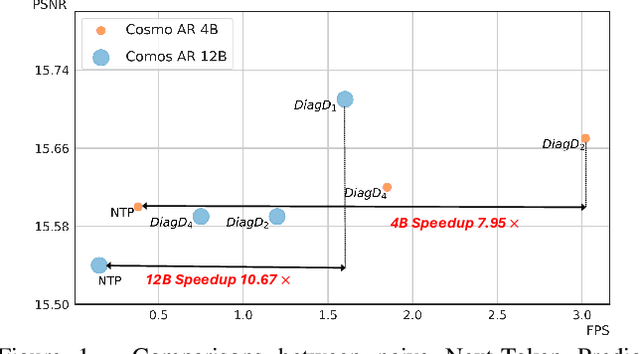
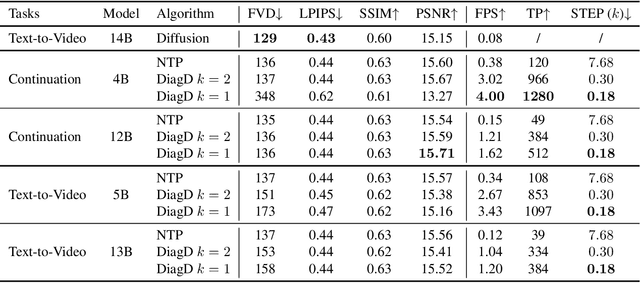
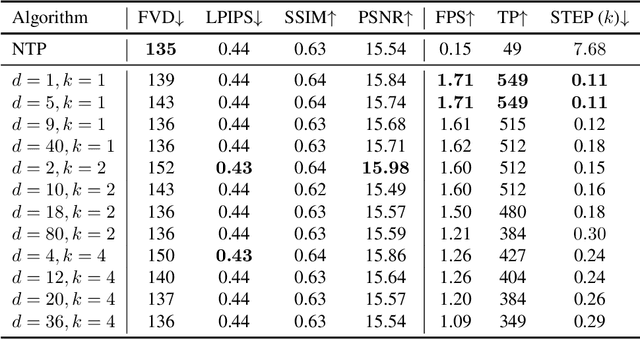
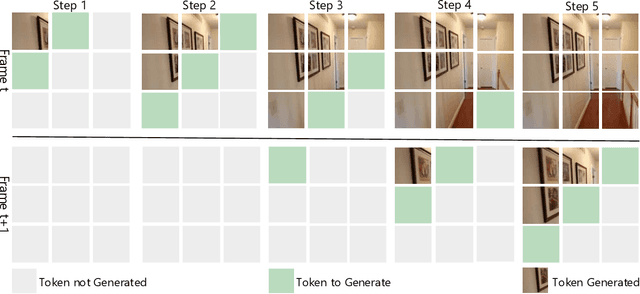
Autoregressive Transformer models have demonstrated impressive performance in video generation, but their sequential token-by-token decoding process poses a major bottleneck, particularly for long videos represented by tens of thousands of tokens. In this paper, we propose Diagonal Decoding (DiagD), a training-free inference acceleration algorithm for autoregressively pre-trained models that exploits spatial and temporal correlations in videos. Our method generates tokens along diagonal paths in the spatial-temporal token grid, enabling parallel decoding within each frame as well as partially overlapping across consecutive frames. The proposed algorithm is versatile and adaptive to various generative models and tasks, while providing flexible control over the trade-off between inference speed and visual quality. Furthermore, we propose a cost-effective finetuning strategy that aligns the attention patterns of the model with our decoding order, further mitigating the training-inference gap on small-scale models. Experiments on multiple autoregressive video generation models and datasets demonstrate that DiagD achieves up to $10\times$ speedup compared to naive sequential decoding, while maintaining comparable visual fidelity.
Scaling Laws for Pre-training Agents and World Models
Nov 07, 2024



The performance of embodied agents has been shown to improve by increasing model parameters, dataset size, and compute. This has been demonstrated in domains from robotics to video games, when generative learning objectives on offline datasets (pre-training) are used to model an agent's behavior (imitation learning) or their environment (world modeling). This paper characterizes the role of scale in these tasks more precisely. Going beyond the simple intuition that `bigger is better', we show that the same types of power laws found in language modeling (e.g. between loss and optimal model size), also arise in world modeling and imitation learning. However, the coefficients of these laws are heavily influenced by the tokenizer, task \& architecture -- this has important implications on the optimal sizing of models and data.
Toward Human-AI Alignment in Large-Scale Multi-Player Games
Feb 05, 2024



Achieving human-AI alignment in complex multi-agent games is crucial for creating trustworthy AI agents that enhance gameplay. We propose a method to evaluate this alignment using an interpretable task-sets framework, focusing on high-level behavioral tasks instead of low-level policies. Our approach has three components. First, we analyze extensive human gameplay data from Xbox's Bleeding Edge (100K+ games), uncovering behavioral patterns in a complex task space. This task space serves as a basis set for a behavior manifold capturing interpretable axes: fight-flight, explore-exploit, and solo-multi-agent. Second, we train an AI agent to play Bleeding Edge using a Generative Pretrained Causal Transformer and measure its behavior. Third, we project human and AI gameplay to the proposed behavior manifold to compare and contrast. This allows us to interpret differences in policy as higher-level behavioral concepts, e.g., we find that while human players exhibit variability in fight-flight and explore-exploit behavior, AI players tend towards uniformity. Furthermore, AI agents predominantly engage in solo play, while humans often engage in cooperative and competitive multi-agent patterns. These stark differences underscore the need for interpretable evaluation, design, and integration of AI in human-aligned applications. Our study advances the alignment discussion in AI and especially generative AI research, offering a measurable framework for interpretable human-agent alignment in multiplayer gaming.
Transformer Neural Autoregressive Flows
Jan 03, 2024



Density estimation, a central problem in machine learning, can be performed using Normalizing Flows (NFs). NFs comprise a sequence of invertible transformations, that turn a complex target distribution into a simple one, by exploiting the change of variables theorem. Neural Autoregressive Flows (NAFs) and Block Neural Autoregressive Flows (B-NAFs) are arguably the most perfomant members of the NF family. However, they suffer scalability issues and training instability due to the constraints imposed on the network structure. In this paper, we propose a novel solution to these challenges by exploiting transformers to define a new class of neural flows called Transformer Neural Autoregressive Flows (T-NAFs). T-NAFs treat each dimension of a random variable as a separate input token, using attention masking to enforce an autoregressive constraint. We take an amortization-inspired approach where the transformer outputs the parameters of an invertible transformation. The experimental results demonstrate that T-NAFs consistently match or outperform NAFs and B-NAFs across multiple datasets from the UCI benchmark. Remarkably, T-NAFs achieve these results using an order of magnitude fewer parameters than previous approaches, without composing multiple flows.
Comparing the Efficacy of Fine-Tuning and Meta-Learning for Few-Shot Policy Imitation
Jun 23, 2023In this paper we explore few-shot imitation learning for control problems, which involves learning to imitate a target policy by accessing a limited set of offline rollouts. This setting has been relatively under-explored despite its relevance to robotics and control applications. State-of-the-art methods developed to tackle few-shot imitation rely on meta-learning, which is expensive to train as it requires access to a distribution over tasks (rollouts from many target policies and variations of the base environment). Given this limitation we investigate an alternative approach, fine-tuning, a family of methods that pretrain on a single dataset and then fine-tune on unseen domain-specific data. Recent work has shown that fine-tuners outperform meta-learners in few-shot image classification tasks, especially when the data is out-of-domain. Here we evaluate to what extent this is true for control problems, proposing a simple yet effective baseline which relies on two stages: (i) training a base policy online via reinforcement learning (e.g. Soft Actor-Critic) on a single base environment, (ii) fine-tuning the base policy via behavioral cloning on a few offline rollouts of the target policy. Despite its simplicity this baseline is competitive with meta-learning methods on a variety of conditions and is able to imitate target policies trained on unseen variations of the original environment. Importantly, the proposed approach is practical and easy to implement, as it does not need any complex meta-training protocol. As a further contribution, we release an open source dataset called iMuJoCo (iMitation MuJoCo) consisting of 154 variants of popular OpenAI-Gym MuJoCo environments with associated pretrained target policies and rollouts, which can be used by the community to study few-shot imitation learning and offline reinforcement learning.
Learning Safety Constraints from Demonstrations with Unknown Rewards
May 25, 2023We propose Convex Constraint Learning for Reinforcement Learning (CoCoRL), a novel approach for inferring shared constraints in a Constrained Markov Decision Process (CMDP) from a set of safe demonstrations with possibly different reward functions. While previous work is limited to demonstrations with known rewards or fully known environment dynamics, CoCoRL can learn constraints from demonstrations with different unknown rewards without knowledge of the environment dynamics. CoCoRL constructs a convex safe set based on demonstrations, which provably guarantees safety even for potentially sub-optimal (but safe) demonstrations. For near-optimal demonstrations, CoCoRL converges to the true safe set with no policy regret. We evaluate CoCoRL in tabular environments and a continuous driving simulation with multiple constraints. CoCoRL learns constraints that lead to safe driving behavior and that can be transferred to different tasks and environments. In contrast, alternative methods based on Inverse Reinforcement Learning (IRL) often exhibit poor performance and learn unsafe policies.
Navigates Like Me: Understanding How People Evaluate Human-Like AI in Video Games
Mar 02, 2023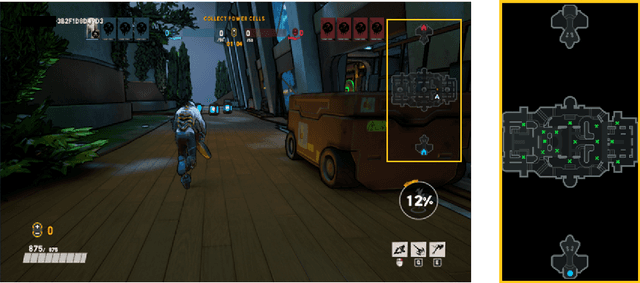
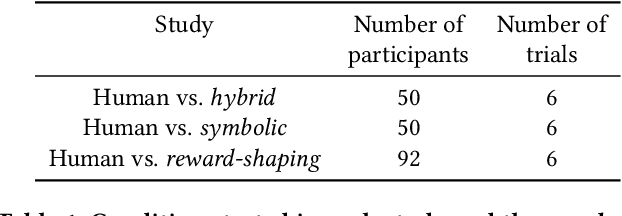
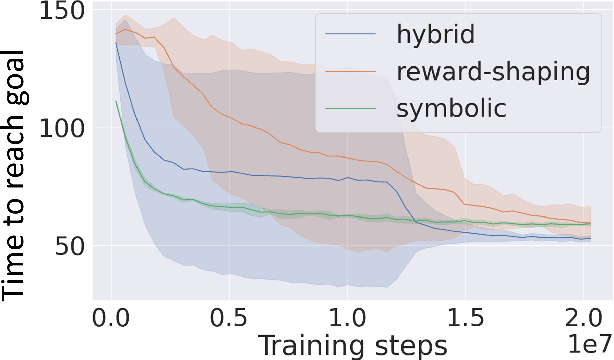

We aim to understand how people assess human likeness in navigation produced by people and artificially intelligent (AI) agents in a video game. To this end, we propose a novel AI agent with the goal of generating more human-like behavior. We collect hundreds of crowd-sourced assessments comparing the human-likeness of navigation behavior generated by our agent and baseline AI agents with human-generated behavior. Our proposed agent passes a Turing Test, while the baseline agents do not. By passing a Turing Test, we mean that human judges could not quantitatively distinguish between videos of a person and an AI agent navigating. To understand what people believe constitutes human-like navigation, we extensively analyze the justifications of these assessments. This work provides insights into the characteristics that people consider human-like in the context of goal-directed video game navigation, which is a key step for further improving human interactions with AI agents.
Trust-Region-Free Policy Optimization for Stochastic Policies
Feb 15, 2023Trust Region Policy Optimization (TRPO) is an iterative method that simultaneously maximizes a surrogate objective and enforces a trust region constraint over consecutive policies in each iteration. The combination of the surrogate objective maximization and the trust region enforcement has been shown to be crucial to guarantee a monotonic policy improvement. However, solving a trust-region-constrained optimization problem can be computationally intensive as it requires many steps of conjugate gradient and a large number of on-policy samples. In this paper, we show that the trust region constraint over policies can be safely substituted by a trust-region-free constraint without compromising the underlying monotonic improvement guarantee. The key idea is to generalize the surrogate objective used in TRPO in a way that a monotonic improvement guarantee still emerges as a result of constraining the maximum advantage-weighted ratio between policies. This new constraint outlines a conservative mechanism for iterative policy optimization and sheds light on practical ways to optimize the generalized surrogate objective. We show that the new constraint can be effectively enforced by being conservative when optimizing the generalized objective function in practice. We call the resulting algorithm Trust-REgion-Free Policy Optimization (TREFree) as it is free of any explicit trust region constraints. Empirical results show that TREFree outperforms TRPO and Proximal Policy Optimization (PPO) in terms of policy performance and sample efficiency.