 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving Hyperbolic Deep Reinforcement Learning
Dec 16, 2025The performance of reinforcement learning (RL) agents depends critically on the quality of the underlying feature representations. Hyperbolic feature spaces are well-suited for this purpose, as they naturally capture hierarchical and relational structure often present in complex RL environments. However, leveraging these spaces commonly faces optimization challenges due to the nonstationarity of RL. In this work, we identify key factors that determine the success and failure of training hyperbolic deep RL agents. By analyzing the gradients of core operations in the Poincaré Ball and Hyperboloid models of hyperbolic geometry, we show that large-norm embeddings destabilize gradient-based training, leading to trust-region violations in proximal policy optimization (PPO). Based on these insights, we introduce Hyper++, a new hyperbolic PPO agent that consists of three components: (i) stable critic training through a categorical value loss instead of regression; (ii) feature regularization guaranteeing bounded norms while avoiding the curse of dimensionality from clipping; and (iii) using a more optimization-friendly formulation of hyperbolic network layers. In experiments on ProcGen, we show that Hyper++ guarantees stable learning, outperforms prior hyperbolic agents, and reduces wall-clock time by approximately 30%. On Atari-5 with Double DQN, Hyper++ strongly outperforms Euclidean and hyperbolic baselines. We release our code at https://github.com/Probabilistic-and-Interactive-ML/hyper-rl .
Prompt Optimization Across Multiple Agents for Representing Diverse Human Populations
Oct 08, 2025The difficulty and expense of obtaining large-scale human responses make Large Language Models (LLMs) an attractive alternative and a promising proxy for human behavior. However, prior work shows that LLMs often produce homogeneous outputs that fail to capture the rich diversity of human perspectives and behaviors. Thus, rather than trying to capture this diversity with a single LLM agent, we propose a novel framework to construct a set of agents that collectively capture the diversity of a given human population. Each agent is an LLM whose behavior is steered by conditioning on a small set of human demonstrations (task-response pairs) through in-context learning. The central challenge is therefore to select a representative set of LLM agents from the exponentially large space of possible agents. We tackle this selection problem from the lens of submodular optimization. In particular, we develop methods that offer different trade-offs regarding time complexity and performance guarantees. Extensive experiments in crowdsourcing and educational domains demonstrate that our approach constructs agents that more effectively represent human populations compared to baselines. Moreover, behavioral analyses on new tasks show that these agents reproduce the behavior patterns and perspectives of the students and annotators they are designed to represent.
Synthesizing High-Quality Programming Tasks with LLM-based Expert and Student Agents
Apr 10, 2025Generative AI is transforming computing education by enabling the automatic generation of personalized content and feedback. We investigate its capabilities in providing high-quality programming tasks to students. Despite promising advancements in task generation, a quality gap remains between AI-generated and expert-created tasks. The AI-generated tasks may not align with target programming concepts, could be incomprehensible for students to solve, or may contain critical issues such as incorrect tests. Existing works often require interventions from human teachers for validation. We address these challenges by introducing PyTaskSyn, a novel synthesis technique that first generates a programming task and then decides whether it meets certain quality criteria to be given to students. The key idea is to break this process into multiple stages performed by expert and student agents simulated using both strong and weaker generative models. Through extensive evaluation, we show that PyTaskSyn significantly improves task quality compared to baseline techniques and showcases the importance of each specialized agent type in our validation pipeline. Additionally, we conducted user studies using our publicly available web application and show that PyTaskSyn can deliver high-quality programming tasks comparable to expert-designed ones while reducing workload and costs, and being more engaging than programming tasks that are available in online resources.
Rule-Guided Reinforcement Learning Policy Evaluation and Improvement
Mar 12, 2025We consider the challenging problem of using domain knowledge to improve deep reinforcement learning policies. To this end, we propose LEGIBLE, a novel approach, following a multi-step process, which starts by mining rules from a deep RL policy, constituting a partially symbolic representation. These rules describe which decisions the RL policy makes and which it avoids making. In the second step, we generalize the mined rules using domain knowledge expressed as metamorphic relations. We adapt these relations from software testing to RL to specify expected changes of actions in response to changes in observations. The third step is evaluating generalized rules to determine which generalizations improve performance when enforced. These improvements show weaknesses in the policy, where it has not learned the general rules and thus can be improved by rule guidance. LEGIBLE supported by metamorphic relations provides a principled way of expressing and enforcing domain knowledge about RL environments. We show the efficacy of our approach by demonstrating that it effectively finds weaknesses, accompanied by explanations of these weaknesses, in eleven RL environments and by showcasing that guiding policy execution with rules improves performance w.r.t. gained reward.
Plasticity Loss in Deep Reinforcement Learning: A Survey
Nov 07, 2024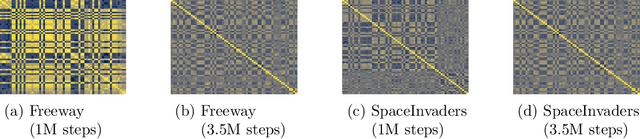
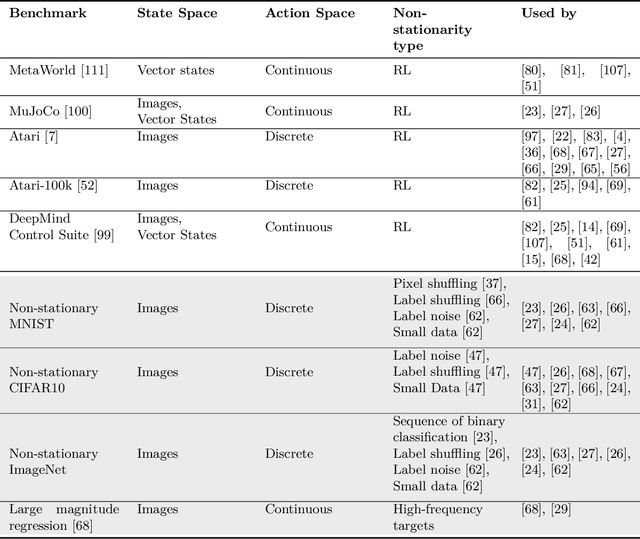
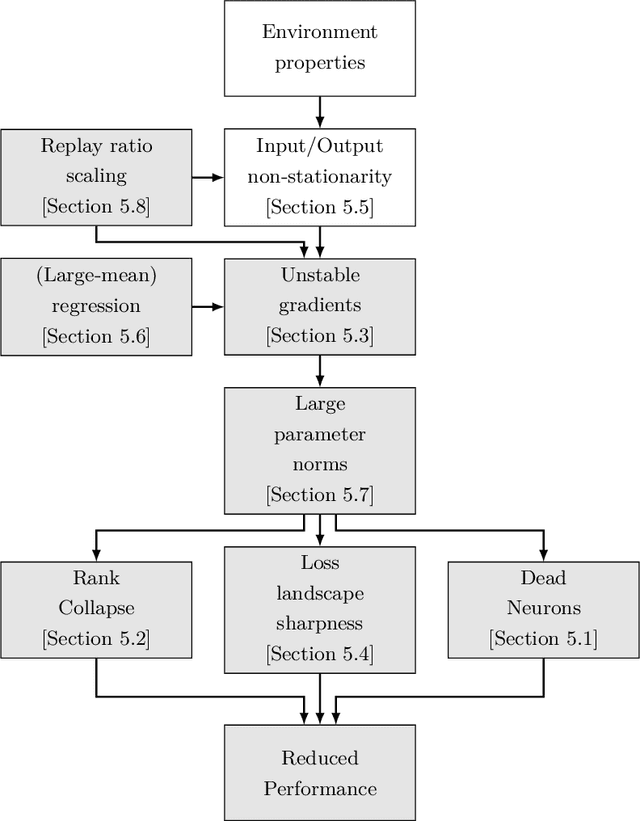

Akin to neuroplasticity in human brains, the plasticity of deep neural networks enables their quick adaption to new data. This makes plasticity particularly crucial for deep Reinforcement Learning (RL) agents: Once plasticity is lost, an agent's performance will inevitably plateau because it cannot improve its policy to account for changes in the data distribution, which are a necessary consequence of its learning process. Thus, developing well-performing and sample-efficient agents hinges on their ability to remain plastic during training. Furthermore, the loss of plasticity can be connected to many other issues plaguing deep RL, such as training instabilities, scaling failures, overestimation bias, and insufficient exploration. With this survey, we aim to provide an overview of the emerging research on plasticity loss for academics and practitioners of deep reinforcement learning. First, we propose a unified definition of plasticity loss based on recent works, relate it to definitions from the literature, and discuss metrics for measuring plasticity loss. Then, we categorize and discuss numerous possible causes of plasticity loss before reviewing currently employed mitigation strategies. Our taxonomy is the first systematic overview of the current state of the field. Lastly, we discuss prevalent issues within the literature, such as a necessity for broader evaluation, and provide recommendations for future research, like gaining a better understanding of an agent's neural activity and behavior.
Breaking the Reclustering Barrier in Centroid-based Deep Clustering
Nov 04, 2024



This work investigates an important phenomenon in centroid-based deep clustering (DC) algorithms: Performance quickly saturates after a period of rapid early gains. Practitioners commonly address early saturation with periodic reclustering, which we demonstrate to be insufficient to address performance plateaus. We call this phenomenon the "reclustering barrier" and empirically show when the reclustering barrier occurs, what its underlying mechanisms are, and how it is possible to Break the Reclustering Barrier with our algorithm BRB. BRB avoids early over-commitment to initial clusterings and enables continuous adaptation to reinitialized clustering targets while remaining conceptually simple. Applying our algorithm to widely-used centroid-based DC algorithms, we show that (1) BRB consistently improves performance across a wide range of clustering benchmarks, (2) BRB enables training from scratch, and (3) BRB performs competitively against state-of-the-art DC algorithms when combined with a contrastive loss. We release our code and pre-trained models at https://github.com/Probabilistic-and-Interactive-ML/breaking-the-reclustering-barrier .
Challenging the Human-in-the-loop in Algorithmic Decision-making
May 17, 2024



We discuss the role of humans in algorithmic decision-making (ADM) for socially relevant problems from a technical and philosophical perspective. In particular, we illustrate tensions arising from diverse expectations, values, and constraints by and on the humans involved. To this end, we assume that a strategic decision-maker (SDM) introduces ADM to optimize strategic and societal goals while the algorithms' recommended actions are overseen by a practical decision-maker (PDM) - a specific human-in-the-loop - who makes the final decisions. While the PDM is typically assumed to be a corrective, it can counteract the realization of the SDM's desired goals and societal values not least because of a misalignment of these values and unmet information needs of the PDM. This has significant implications for the distribution of power between the stakeholders in ADM, their constraints, and information needs. In particular, we emphasize the overseeing PDM's role as a potential political and ethical decision maker, who acts expected to balance strategic, value-driven objectives and on-the-ground individual decisions and constraints. We demonstrate empirically, on a machine learning benchmark dataset, the significant impact an overseeing PDM's decisions can have even if the PDM is constrained to performing only a limited amount of actions differing from the algorithms' recommendations. To ensure that the SDM's intended values are realized, the PDM needs to be provided with appropriate information conveyed through tailored explanations and its role must be characterized clearly. Our findings emphasize the need for an in-depth discussion of the role and power of the PDM and challenge the often-taken view that just including a human-in-the-loop in ADM ensures the 'correct' and 'ethical' functioning of the system.
Information That Matters: Exploring Information Needs of People Affected by Algorithmic Decisions
Jan 29, 2024Explanations of AI systems rarely address the information needs of people affected by algorithmic decision-making (ADM). This gap between conveyed information and information that matters to affected stakeholders can impede understanding and adherence to regulatory frameworks such as the AI Act. To address this gap, we present the "XAI Novice Question Bank": A catalog of affected stakeholders' information needs in two ADM use cases (employment prediction and health monitoring), covering the categories data, system context, system usage, and system specifications. Information needs were gathered in an interview study where participants received explanations in response to their inquiries. Participants further reported their understanding and decision confidence, showing that while confidence tended to increase after receiving explanations, participants also met understanding challenges, such as being unable to tell why their understanding felt incomplete. Explanations further influenced participants' perceptions of the systems' risks and benefits, which they confirmed or changed depending on the use case. When risks were perceived as high, participants expressed particular interest in explanations about intention, such as why and to what end a system was put in place. With this work, we aim to support the inclusion of affected stakeholders into explainability by contributing an overview of information and challenges relevant to them when deciding on the adoption of ADM systems. We close by summarizing our findings in a list of six key implications that inform the design of future explanations for affected stakeholder audiences.
Active Third-Person Imitation Learning
Dec 27, 2023We consider the problem of third-person imitation learning with the additional challenge that the learner must select the perspective from which they observe the expert. In our setting, each perspective provides only limited information about the expert's behavior, and the learning agent must carefully select and combine information from different perspectives to achieve competitive performance. This setting is inspired by real-world imitation learning applications, e.g., in robotics, a robot might observe a human demonstrator via camera and receive information from different perspectives depending on the camera's position. We formalize the aforementioned active third-person imitation learning problem, theoretically analyze its characteristics, and propose a generative adversarial network-based active learning approach. Empirically, we demstrate that our proposed approach can effectively learn from expert demonstrations and explore the importance of different architectural choices for the learner's performance.
Posterior Consistency for Missing Data in Variational Autoencoders
Oct 25, 2023We consider the problem of learning Variational Autoencoders (VAEs), i.e., a type of deep generative model, from data with missing values. Such data is omnipresent in real-world applications of machine learning because complete data is often impossible or too costly to obtain. We particularly focus on improving a VAE's amortized posterior inference, i.e., the encoder, which in the case of missing data can be susceptible to learning inconsistent posterior distributions regarding the missingness. To this end, we provide a formal definition of posterior consistency and propose an approach for regularizing an encoder's posterior distribution which promotes this consistency. We observe that the proposed regularization suggests a different training objective than that typically considered in the literature when facing missing values. Furthermore, we empirically demonstrate that our regularization leads to improved performance in missing value settings in terms of reconstruction quality and downstream tasks utilizing uncertainty in the latent space. This improved performance can be observed for many classes of VAEs including VAEs equipped with normalizing flows.