 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLMC: Interactive multi-label multi-classifier evaluation without confusion matrices
Jan 24, 2025Machine learning-based classifiers are commonly evaluated by metrics like accuracy, but deeper analysis is required to understand their strengths and weaknesses. MLMC is a visual exploration tool that tackles the challenge of multi-label classifier comparison and evaluation. It offers a scalable alternative to confusion matrices which are commonly used for such tasks, but don't scale well with a large number of classes or labels. Additionally, MLMC allows users to view classifier performance from an instance perspective, a label perspective, and a classifier perspective. Our user study shows that the techniques implemented by MLMC allow for a powerful multi-label classifier evaluation while preserving user friendliness.
Information That Matters: Exploring Information Needs of People Affected by Algorithmic Decisions
Jan 29, 2024Explanations of AI systems rarely address the information needs of people affected by algorithmic decision-making (ADM). This gap between conveyed information and information that matters to affected stakeholders can impede understanding and adherence to regulatory frameworks such as the AI Act. To address this gap, we present the "XAI Novice Question Bank": A catalog of affected stakeholders' information needs in two ADM use cases (employment prediction and health monitoring), covering the categories data, system context, system usage, and system specifications. Information needs were gathered in an interview study where participants received explanations in response to their inquiries. Participants further reported their understanding and decision confidence, showing that while confidence tended to increase after receiving explanations, participants also met understanding challenges, such as being unable to tell why their understanding felt incomplete. Explanations further influenced participants' perceptions of the systems' risks and benefits, which they confirmed or changed depending on the use case. When risks were perceived as high, participants expressed particular interest in explanations about intention, such as why and to what end a system was put in place. With this work, we aim to support the inclusion of affected stakeholders into explainability by contributing an overview of information and challenges relevant to them when deciding on the adoption of ADM systems. We close by summarizing our findings in a list of six key implications that inform the design of future explanations for affected stakeholder audiences.
Applying Interdisciplinary Frameworks to Understand Algorithmic Decision-Making
May 26, 2023We argue that explanations for "algorithmic decision-making" (ADM) systems can profit by adopting practices that are already used in the learning sciences. We shortly introduce the importance of explaining ADM systems, give a brief overview of approaches drawing from other disciplines to improve explanations, and present the results of our qualitative task-based study incorporating the "six facets of understanding" framework. We close with questions guiding the discussion of how future studies can leverage an interdisciplinary approach.
FuNNscope: Visual microscope for interactively exploring the loss landscape of fully connected neural networks
Apr 09, 2022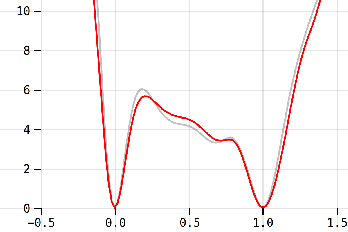
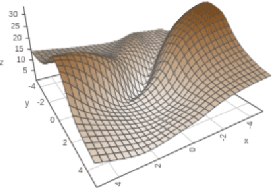
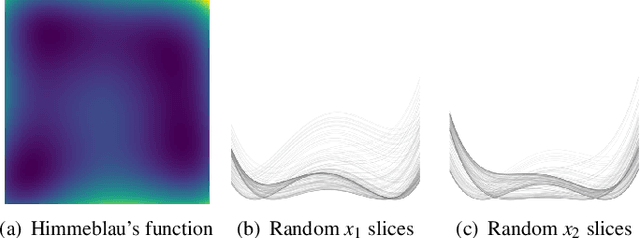
Despite their effective use in various fields, many aspects of neural networks are poorly understood. One important way to investigate the characteristics of neural networks is to explore the loss landscape. However, most models produce a high-dimensional non-convex landscape which is difficult to visualize. We discuss and extend existing visualization methods based on 1D- and 2D slicing with a novel method that approximates the actual loss landscape geometry by using charts with interpretable axes. Based on the assumption that observations on small neural networks can generalize to more complex systems and provide us with helpful insights, we focus on small models in the range of a few dozen weights, which enables computationally cheap experiments and the use of an interactive dashboard. We observe symmetries around the zero vector, the influence of different layers on the global landscape, the different weight sensitivities around a minimizer, and how gradient descent navigates high-loss obstacles. The user study resulted in an average SUS (System Usability Scale) score with suggestions for improvement and opened up a number of possible application scenarios, such as autoencoders and ensemble networks.
Document Domain Randomization for Deep Learning Document Layout Extraction
May 20, 2021
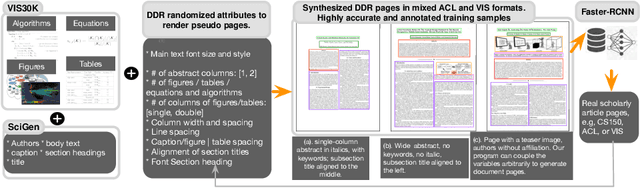
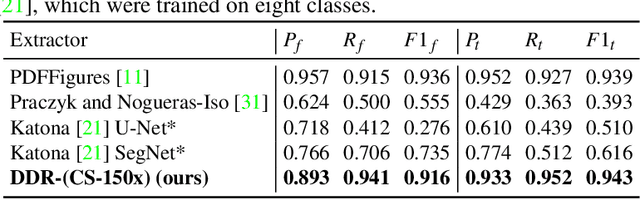

We present document domain randomization (DDR), the first successful transfer of convolutional neural networks (CNNs) trained only on graphically rendered pseudo-paper pages to real-world document segmentation. DDR renders pseudo-document pages by modeling randomized textual and non-textual contents of interest, with user-defined layout and font styles to support joint learning of fine-grained classes. We demonstrate competitive results using our DDR approach to extract nine document classes from the benchmark CS-150 and papers published in two domains, namely annual meetings of Association for Computational Linguistics (ACL) and IEEE Visualization (VIS). We compare DDR to conditions of style mismatch, fewer or more noisy samples that are more easily obtained in the real world. We show that high-fidelity semantic information is not necessary to label semantic classes but style mismatch between train and test can lower model accuracy. Using smaller training samples had a slightly detrimental effect. Finally, network models still achieved high test accuracy when correct labels are diluted towards confusing labels; this behavior hold across several classes.
VIS30K: A Collection of Figures and Tables from IEEE Visualization Conference Publications
Jan 11, 2021We present the VIS30K dataset, a collection of 29,689 images that represents 30 years of figures and tables from each track of the IEEE Visualization conference series (Vis, SciVis, InfoVis, VAST). VIS30K's comprehensive coverage of the scientific literature in visualization not only reflects the progress of the field but also enables researchers to study the evolution of the state-of-the-art and to find relevant work based on graphical content. We describe the dataset and our semi-automatic collection process, which couples convolutional neural networks (CNN) with curation. Extracting figures and tables semi-automatically allows us to verify that no images are overlooked or extracted erroneously. To improve quality further, we engaged in a peer-search process for high-quality figures from early IEEE Visualization papers. With the resulting data, we also contribute VISImageNavigator (VIN, visimagenavigator.github.io), a web-based tool that facilitates searching and exploring VIS30K by author names, paper keywords, title and abstract, and years.
embComp: Visual Interactive Comparison of Vector Embeddings
Nov 05, 2019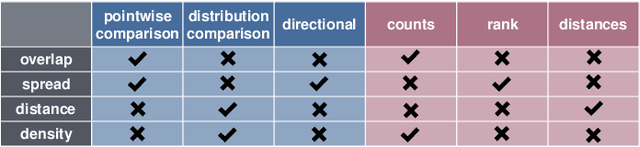

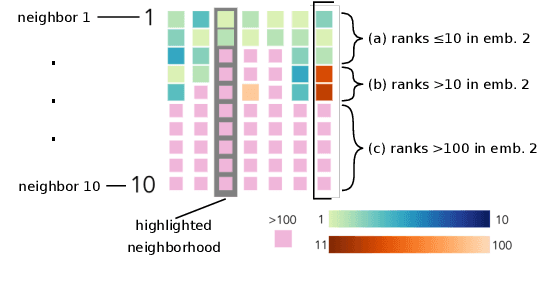
This work introduces embComp, a novel approach for comparing two embeddings that capture the similarity between objects, such as word and document embeddings. We survey scenarios where comparing these embedding spaces is useful. From those scenarios, we derive common tasks, introduce visual analysis methods that support these tasks, and combine them into a comprehensive system. One of embComp's central features are overview visualizations that are based on metrics for measuring differences in local structure around objects. Summarizing these local metrics over the embeddings provides global overviews of similarities and differences. These global views enable a user to identify sets of interesting objects whose relationships in the embeddings can be compared. Detail views allow comparison of the local structure around selected objects and relating this local information to the global views. Integrating and connecting all of these components, \sysname supports a range of analysis workflows that help understand similarities and differences between embedding spaces. We assess our approach by applying it in several use cases, including understanding corpora differences via word vector embeddings, and understanding algorithmic differences in generating embeddings.