 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoxer: Interactive Comparison of Classifier Results
Apr 16, 2020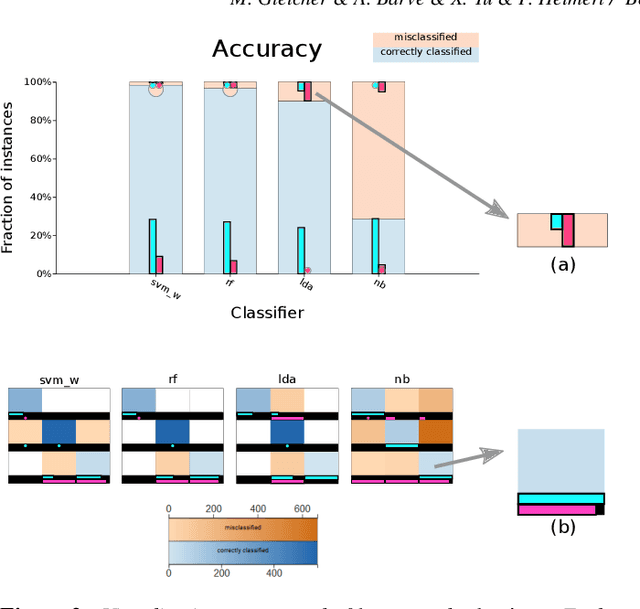
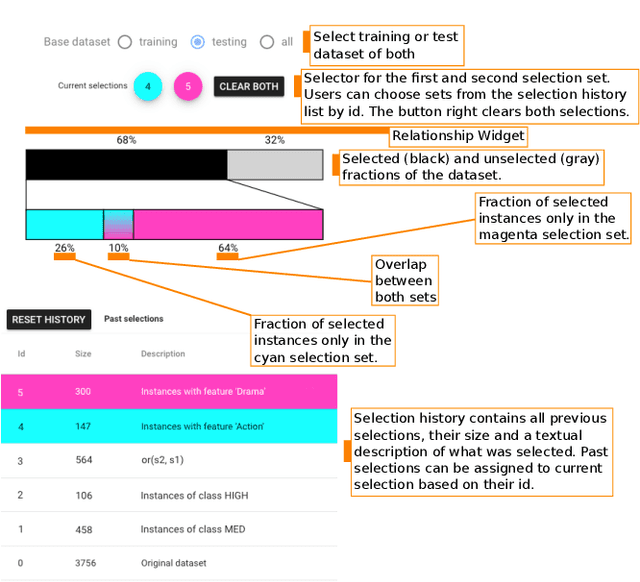
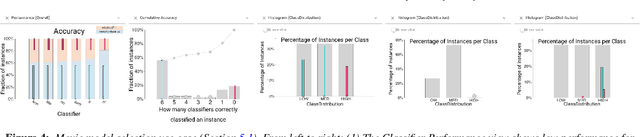
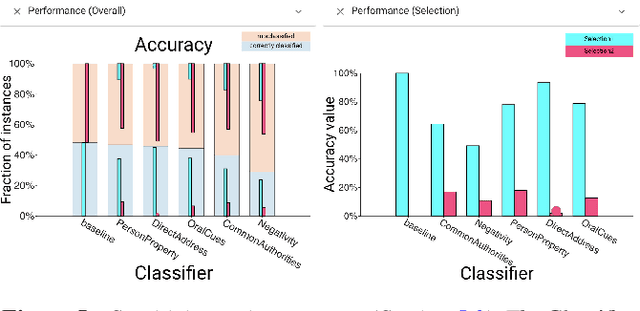
Machine learning practitioners often compare the results of different classifiers to help select, diagnose and tune models. We present Boxer, a system to enable such comparison. Our system facilitates interactive exploration of the experimental results obtained by applying multiple classifiers to a common set of model inputs. The approach focuses on allowing the user to identify interesting subsets of training and testing instances and comparing performance of the classifiers on these subsets. The system couples standard visual designs with set algebra interactions and comparative elements. This allows the user to compose and coordinate views to specify subsets and assess classifier performance on them. The flexibility of these compositions allow the user to address a wide range of scenarios in developing and assessing classifiers. We demonstrate Boxer in use cases including model selection, tuning, fairness assessment, and data quality diagnosis.
embComp: Visual Interactive Comparison of Vector Embeddings
Nov 05, 2019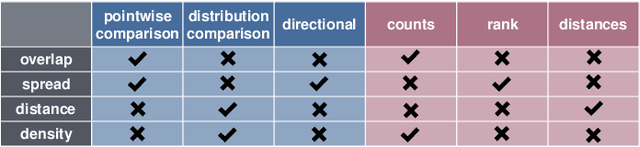

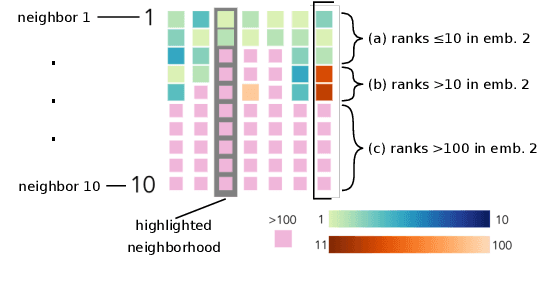
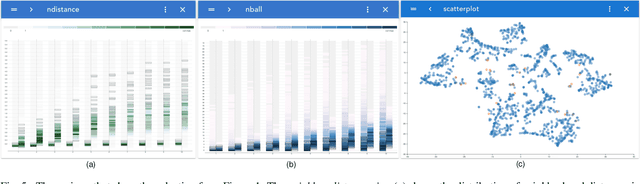
This work introduces embComp, a novel approach for comparing two embeddings that capture the similarity between objects, such as word and document embeddings. We survey scenarios where comparing these embedding spaces is useful. From those scenarios, we derive common tasks, introduce visual analysis methods that support these tasks, and combine them into a comprehensive system. One of embComp's central features are overview visualizations that are based on metrics for measuring differences in local structure around objects. Summarizing these local metrics over the embeddings provides global overviews of similarities and differences. These global views enable a user to identify sets of interesting objects whose relationships in the embeddings can be compared. Detail views allow comparison of the local structure around selected objects and relating this local information to the global views. Integrating and connecting all of these components, \sysname supports a range of analysis workflows that help understand similarities and differences between embedding spaces. We assess our approach by applying it in several use cases, including understanding corpora differences via word vector embeddings, and understanding algorithmic differences in generating embeddings.
Visual Analytics for Automated Model Discovery
Oct 02, 2018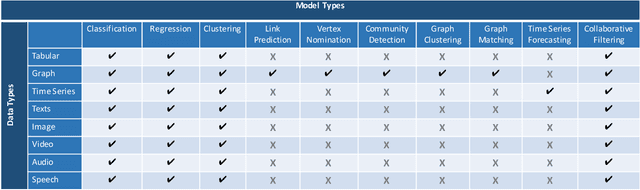
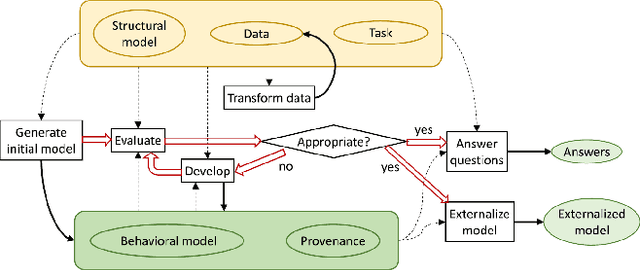
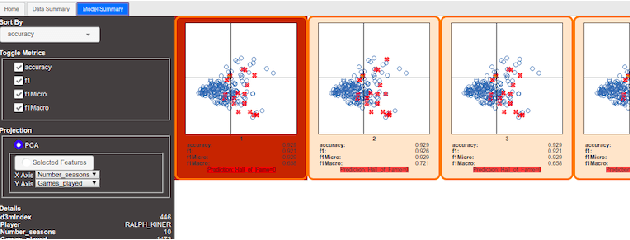
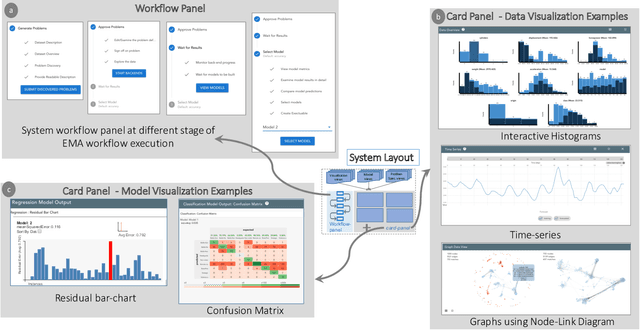
A recent advancement in the machine learning community is the development of automated machine learning (autoML) systems, such as autoWeka or Google's Cloud AutoML, which automate the model selection and tuning process. However, while autoML tools give users access to arbitrarily complex models, they typically return those models with little context or explanation. Visual analytics can be helpful in giving a user of autoML insight into their data, and a more complete understanding of the models discovered by autoML, including differences between multiple models. In this work, we describe how visual analytics for automated model discovery differs from traditional visual analytics for machine learning. First, we propose an architecture based on an extension of existing visual analytics frameworks. Then we describe a prototype system Snowcat, developed according to the presented framework and architecture, that aids users in generating models for a diverse set of data and modeling tasks.