 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Geolocation Prediction of Tweets with Human Machine Collaboration
Jun 25, 2021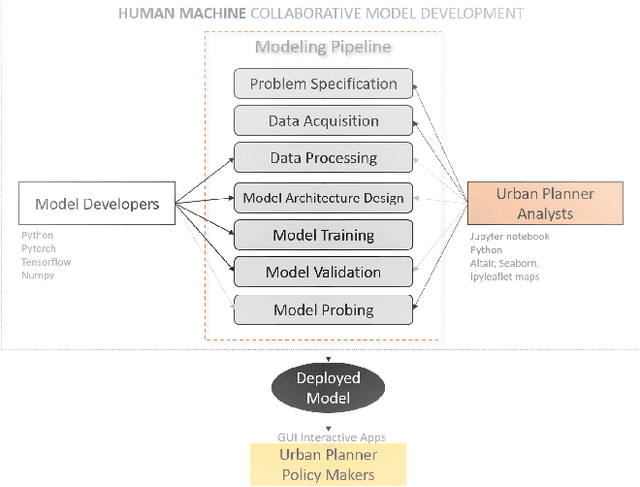
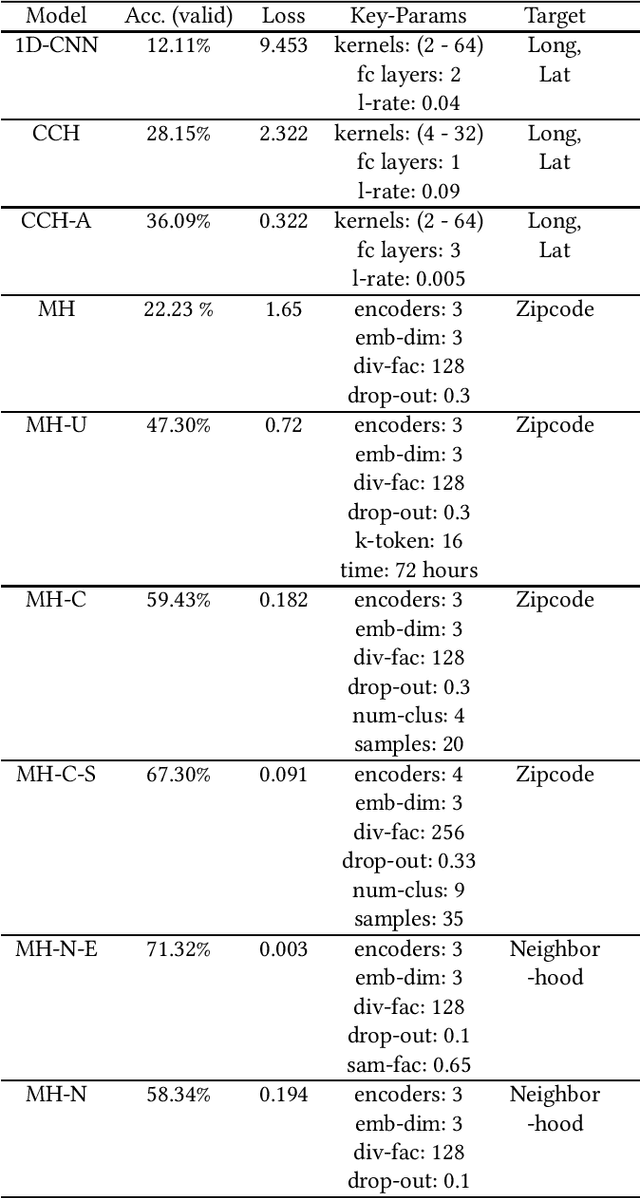
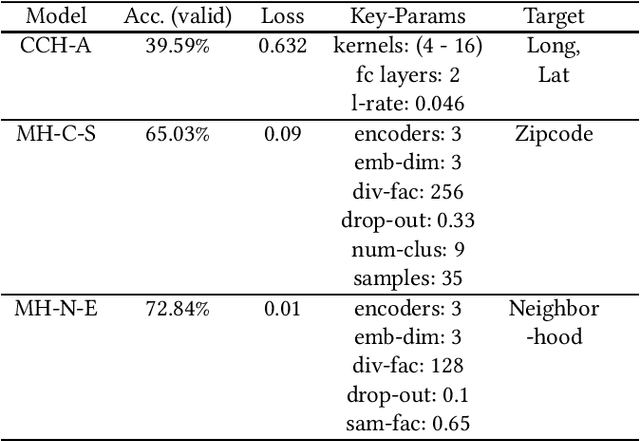
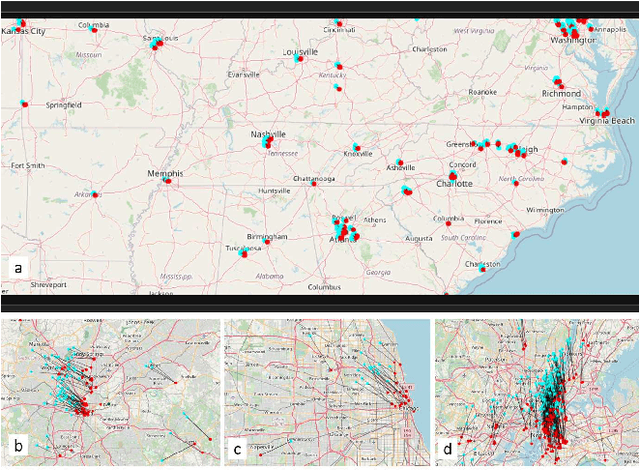
Twitter is a useful resource to analyze peoples' opinions on various topics. Often these topics are correlated or associated with locations from where these Tweet posts are made. For example, restaurant owners may need to know where their target customers eat with respect to the sentiment of the posts made related to food, policy planners may need to analyze citizens' opinion on relevant issues such as crime, safety, congestion, etc. with respect to specific parts of the city, or county or state. As promising as this is, less than $1\%$ of the crawled Tweet posts come with geolocation tags. That makes accurate prediction of Tweet posts for the non geo-tagged tweets very critical to analyze data in various domains. In this research, we utilized millions of Twitter posts and end-users domain expertise to build a set of deep neural network models using natural language processing (NLP) techniques, that predicts the geolocation of non geo-tagged Tweet posts at various level of granularities such as neighborhood, zipcode, and longitude with latitudes. With multiple neural architecture experiments, and a collaborative human-machine workflow design, our ongoing work on geolocation detection shows promising results that empower end-users to correlate relationship between variables of choice with the location information.
CACTUS: Detecting and Resolving Conflicts in Objective Functions
Mar 13, 2021
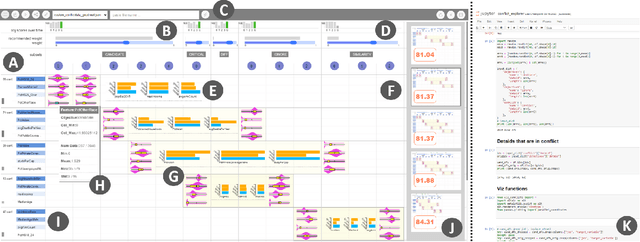

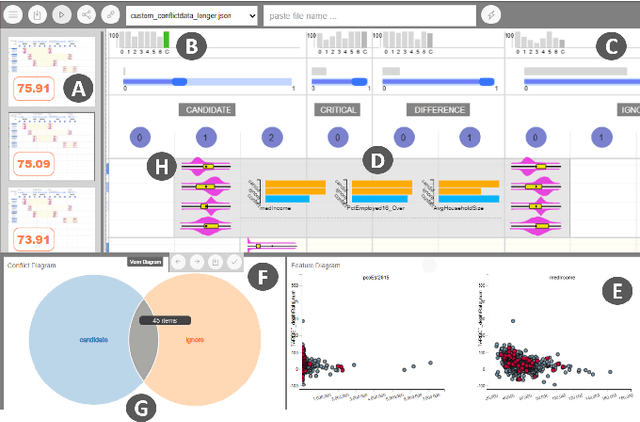
Machine learning (ML) models are constructed by expert ML practitioners using various coding languages, in which they tune and select models hyperparameters and learning algorithms for a given problem domain. They also carefully design an objective function or loss function (often with multiple objectives) that captures the desired output for a given ML task such as classification, regression, etc. In multi-objective optimization, conflicting objectives and constraints is a major area of concern. In such problems, several competing objectives are seen for which no single optimal solution is found that satisfies all desired objectives simultaneously. In the past VA systems have allowed users to interactively construct objective functions for a classifier. In this paper, we extend this line of work by prototyping a technique to visualize multi-objective objective functions either defined in a Jupyter notebook or defined using an interactive visual interface to help users to: (1) perceive and interpret complex mathematical terms in it and (2) detect and resolve conflicting objectives. Visualization of the objective function enlightens potentially conflicting objectives that obstructs selecting correct solution(s) for the desired ML task or goal. We also present an enumeration of potential conflicts in objective specification in multi-objective objective functions for classifier selection. Furthermore, we demonstrate our approach in a VA system that helps users in specifying meaningful objective functions to a classifier by detecting and resolving conflicting objectives and constraints. Through a within-subject quantitative and qualitative user study, we present results showing that our technique helps users interactively specify meaningful objective functions by resolving potential conflicts for a classification task.
Visual Analytics for Automated Model Discovery
Oct 02, 2018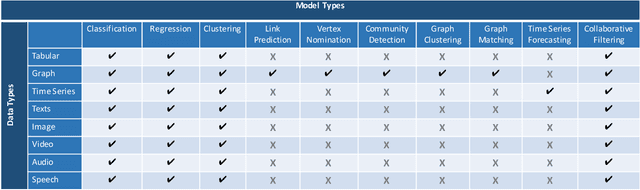
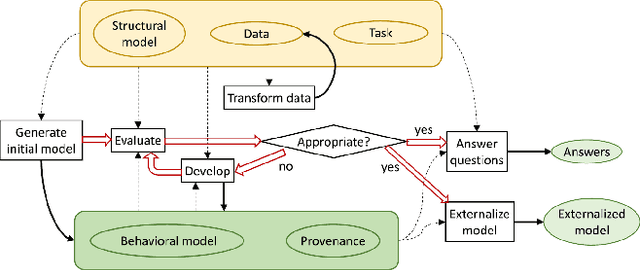
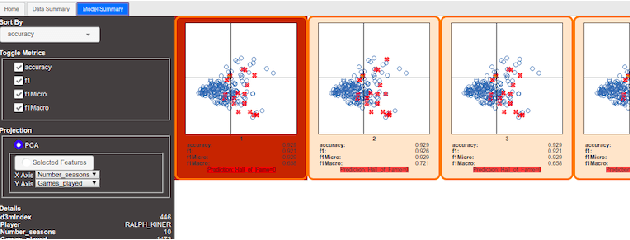
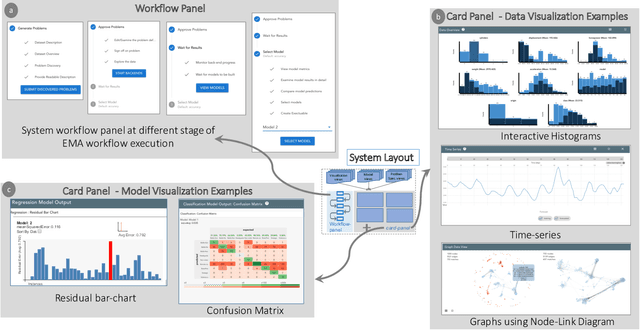
A recent advancement in the machine learning community is the development of automated machine learning (autoML) systems, such as autoWeka or Google's Cloud AutoML, which automate the model selection and tuning process. However, while autoML tools give users access to arbitrarily complex models, they typically return those models with little context or explanation. Visual analytics can be helpful in giving a user of autoML insight into their data, and a more complete understanding of the models discovered by autoML, including differences between multiple models. In this work, we describe how visual analytics for automated model discovery differs from traditional visual analytics for machine learning. First, we propose an architecture based on an extension of existing visual analytics frameworks. Then we describe a prototype system Snowcat, developed according to the presented framework and architecture, that aids users in generating models for a diverse set of data and modeling tasks.