 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR&B: Domain Regrouping and Data Mixture Balancing for Efficient Foundation Model Training
May 01, 2025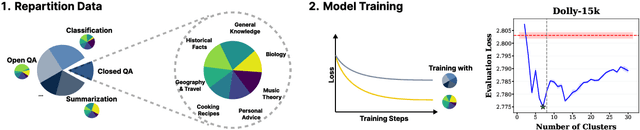
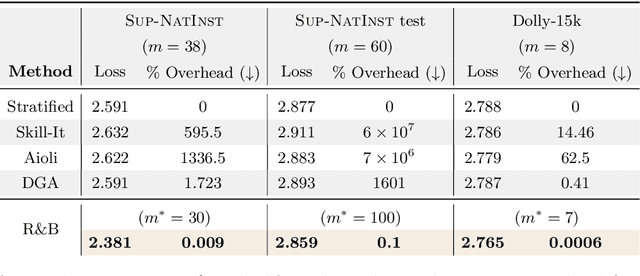
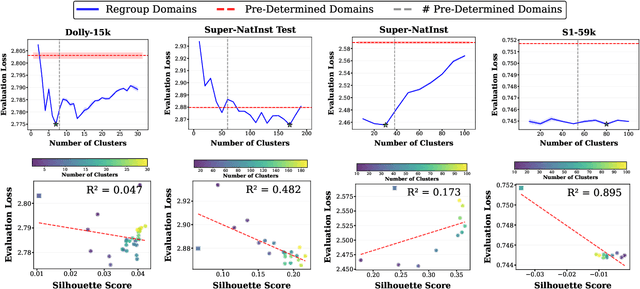
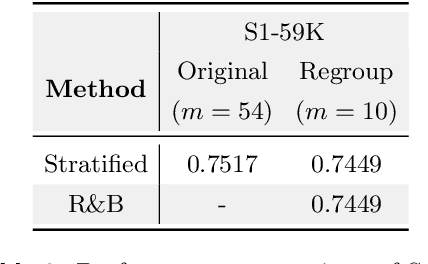
Data mixing strategies have successfully reduced the costs involved in training language models. While promising, such methods suffer from two flaws. First, they rely on predetermined data domains (e.g., data sources, task types), which may fail to capture critical semantic nuances, leaving performance on the table. Second, these methods scale with the number of domains in a computationally prohibitive way. We address these challenges via R&B, a framework that re-partitions training data based on semantic similarity (Regroup) to create finer-grained domains, and efficiently optimizes the data composition (Balance) by leveraging a Gram matrix induced by domain gradients obtained throughout training. Unlike prior works, it removes the need for additional compute to obtain evaluation information such as losses or gradients. We analyze this technique under standard regularity conditions and provide theoretical insights that justify R&B's effectiveness compared to non-adaptive mixing approaches. Empirically, we demonstrate the effectiveness of R&B on five diverse datasets ranging from natural language to reasoning and multimodal tasks. With as little as 0.01% additional compute overhead, R&B matches or exceeds the performance of state-of-the-art data mixing strategies.
Advancing Multimodal Medical Capabilities of Gemini
May 06, 2024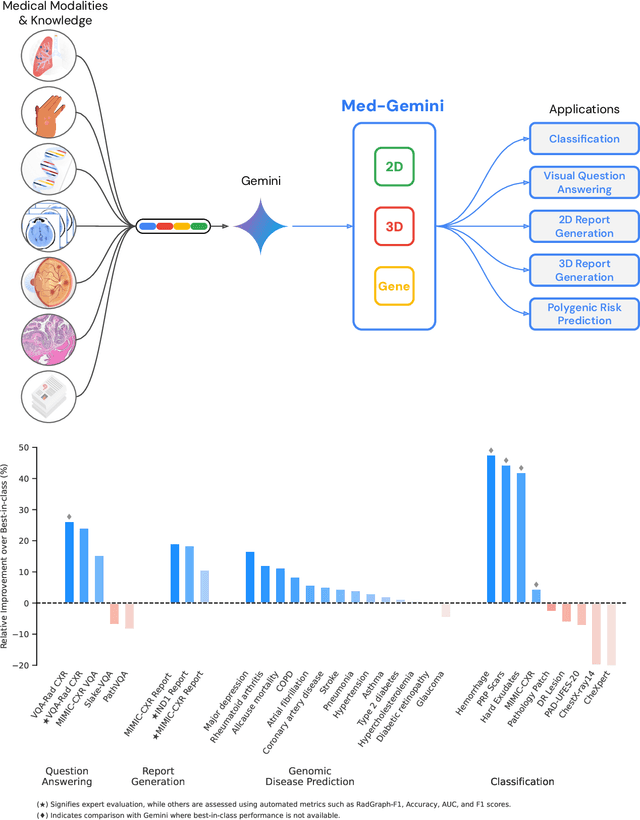
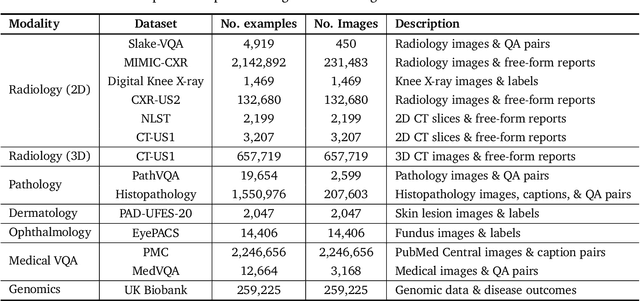

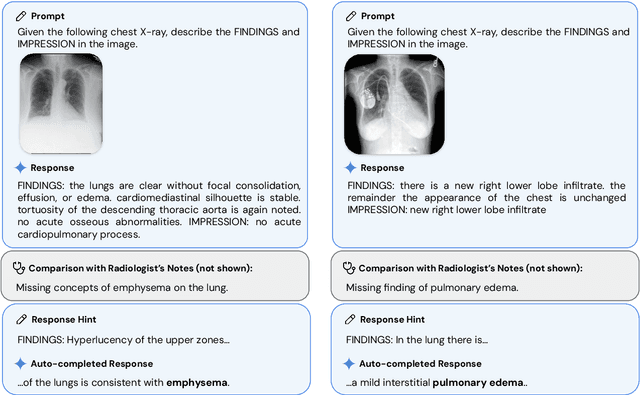
Many clinical tasks require an understanding of specialized data, such as medical images and genomics, which is not typically found in general-purpose large multimodal models. Building upon Gemini's multimodal models, we develop several models within the new Med-Gemini family that inherit core capabilities of Gemini and are optimized for medical use via fine-tuning with 2D and 3D radiology, histopathology, ophthalmology, dermatology and genomic data. Med-Gemini-2D sets a new standard for AI-based chest X-ray (CXR) report generation based on expert evaluation, exceeding previous best results across two separate datasets by an absolute margin of 1% and 12%, where 57% and 96% of AI reports on normal cases, and 43% and 65% on abnormal cases, are evaluated as "equivalent or better" than the original radiologists' reports. We demonstrate the first ever large multimodal model-based report generation for 3D computed tomography (CT) volumes using Med-Gemini-3D, with 53% of AI reports considered clinically acceptable, although additional research is needed to meet expert radiologist reporting quality. Beyond report generation, Med-Gemini-2D surpasses the previous best performance in CXR visual question answering (VQA) and performs well in CXR classification and radiology VQA, exceeding SoTA or baselines on 17 of 20 tasks. In histopathology, ophthalmology, and dermatology image classification, Med-Gemini-2D surpasses baselines across 18 out of 20 tasks and approaches task-specific model performance. Beyond imaging, Med-Gemini-Polygenic outperforms the standard linear polygenic risk score-based approach for disease risk prediction and generalizes to genetically correlated diseases for which it has never been trained. Although further development and evaluation are necessary in the safety-critical medical domain, our results highlight the potential of Med-Gemini across a wide range of medical tasks.
Visual Analytics for Automated Model Discovery
Oct 02, 2018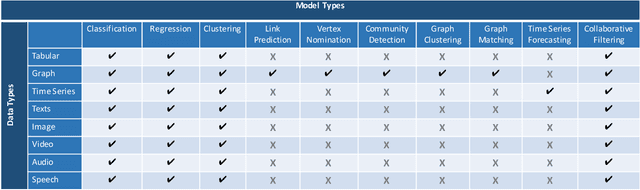
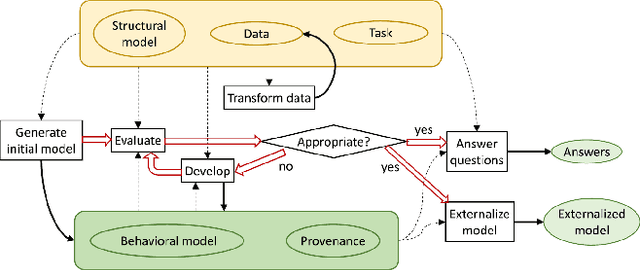
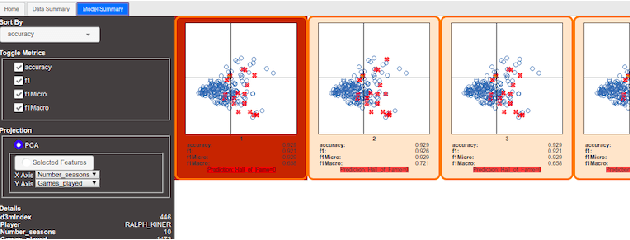
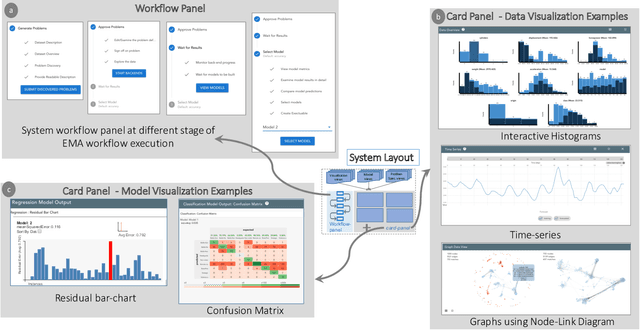
A recent advancement in the machine learning community is the development of automated machine learning (autoML) systems, such as autoWeka or Google's Cloud AutoML, which automate the model selection and tuning process. However, while autoML tools give users access to arbitrarily complex models, they typically return those models with little context or explanation. Visual analytics can be helpful in giving a user of autoML insight into their data, and a more complete understanding of the models discovered by autoML, including differences between multiple models. In this work, we describe how visual analytics for automated model discovery differs from traditional visual analytics for machine learning. First, we propose an architecture based on an extension of existing visual analytics frameworks. Then we describe a prototype system Snowcat, developed according to the presented framework and architecture, that aids users in generating models for a diverse set of data and modeling tasks.