 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving Hyperbolic Deep Reinforcement Learning
Dec 16, 2025The performance of reinforcement learning (RL) agents depends critically on the quality of the underlying feature representations. Hyperbolic feature spaces are well-suited for this purpose, as they naturally capture hierarchical and relational structure often present in complex RL environments. However, leveraging these spaces commonly faces optimization challenges due to the nonstationarity of RL. In this work, we identify key factors that determine the success and failure of training hyperbolic deep RL agents. By analyzing the gradients of core operations in the Poincaré Ball and Hyperboloid models of hyperbolic geometry, we show that large-norm embeddings destabilize gradient-based training, leading to trust-region violations in proximal policy optimization (PPO). Based on these insights, we introduce Hyper++, a new hyperbolic PPO agent that consists of three components: (i) stable critic training through a categorical value loss instead of regression; (ii) feature regularization guaranteeing bounded norms while avoiding the curse of dimensionality from clipping; and (iii) using a more optimization-friendly formulation of hyperbolic network layers. In experiments on ProcGen, we show that Hyper++ guarantees stable learning, outperforms prior hyperbolic agents, and reduces wall-clock time by approximately 30%. On Atari-5 with Double DQN, Hyper++ strongly outperforms Euclidean and hyperbolic baselines. We release our code at https://github.com/Probabilistic-and-Interactive-ML/hyper-rl .
Plasticity Loss in Deep Reinforcement Learning: A Survey
Nov 07, 2024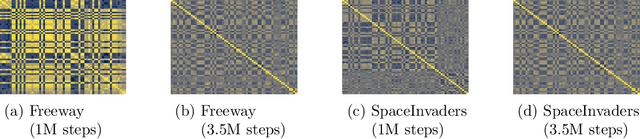
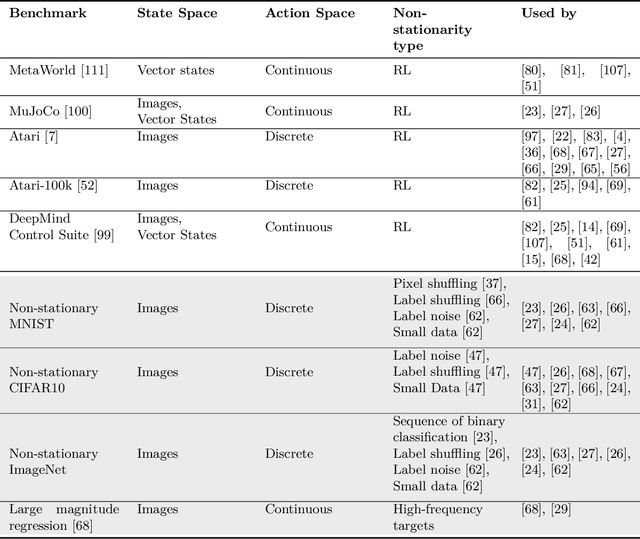
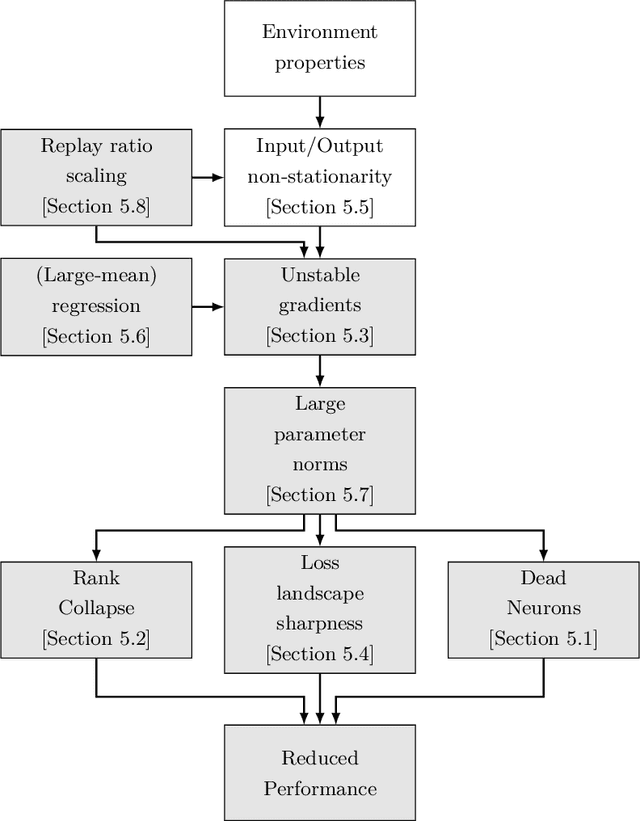

Akin to neuroplasticity in human brains, the plasticity of deep neural networks enables their quick adaption to new data. This makes plasticity particularly crucial for deep Reinforcement Learning (RL) agents: Once plasticity is lost, an agent's performance will inevitably plateau because it cannot improve its policy to account for changes in the data distribution, which are a necessary consequence of its learning process. Thus, developing well-performing and sample-efficient agents hinges on their ability to remain plastic during training. Furthermore, the loss of plasticity can be connected to many other issues plaguing deep RL, such as training instabilities, scaling failures, overestimation bias, and insufficient exploration. With this survey, we aim to provide an overview of the emerging research on plasticity loss for academics and practitioners of deep reinforcement learning. First, we propose a unified definition of plasticity loss based on recent works, relate it to definitions from the literature, and discuss metrics for measuring plasticity loss. Then, we categorize and discuss numerous possible causes of plasticity loss before reviewing currently employed mitigation strategies. Our taxonomy is the first systematic overview of the current state of the field. Lastly, we discuss prevalent issues within the literature, such as a necessity for broader evaluation, and provide recommendations for future research, like gaining a better understanding of an agent's neural activity and behavior.
Breaking the Reclustering Barrier in Centroid-based Deep Clustering
Nov 04, 2024



This work investigates an important phenomenon in centroid-based deep clustering (DC) algorithms: Performance quickly saturates after a period of rapid early gains. Practitioners commonly address early saturation with periodic reclustering, which we demonstrate to be insufficient to address performance plateaus. We call this phenomenon the "reclustering barrier" and empirically show when the reclustering barrier occurs, what its underlying mechanisms are, and how it is possible to Break the Reclustering Barrier with our algorithm BRB. BRB avoids early over-commitment to initial clusterings and enables continuous adaptation to reinitialized clustering targets while remaining conceptually simple. Applying our algorithm to widely-used centroid-based DC algorithms, we show that (1) BRB consistently improves performance across a wide range of clustering benchmarks, (2) BRB enables training from scratch, and (3) BRB performs competitively against state-of-the-art DC algorithms when combined with a contrastive loss. We release our code and pre-trained models at https://github.com/Probabilistic-and-Interactive-ML/breaking-the-reclustering-barrier .
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
Active Third-Person Imitation Learning
Dec 27, 2023We consider the problem of third-person imitation learning with the additional challenge that the learner must select the perspective from which they observe the expert. In our setting, each perspective provides only limited information about the expert's behavior, and the learning agent must carefully select and combine information from different perspectives to achieve competitive performance. This setting is inspired by real-world imitation learning applications, e.g., in robotics, a robot might observe a human demonstrator via camera and receive information from different perspectives depending on the camera's position. We formalize the aforementioned active third-person imitation learning problem, theoretically analyze its characteristics, and propose a generative adversarial network-based active learning approach. Empirically, we demstrate that our proposed approach can effectively learn from expert demonstrations and explore the importance of different architectural choices for the learner's performance.