 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering High-dimensional Data: Balancing Abstraction and Representation Tutorial at AAAI 2026
Jan 16, 2026How to find a natural grouping of a large real data set? Clustering requires a balance between abstraction and representation. To identify clusters, we need to abstract from superfluous details of individual objects. But we also need a rich representation that emphasizes the key features shared by groups of objects that distinguish them from other groups of objects. Each clustering algorithm implements a different trade-off between abstraction and representation. Classical K-means implements a high level of abstraction - details are simply averaged out - combined with a very simple representation - all clusters are Gaussians in the original data space. We will see how approaches to subspace and deep clustering support high-dimensional and complex data by allowing richer representations. However, with increasing representational expressiveness comes the need to explicitly enforce abstraction in the objective function to ensure that the resulting method performs clustering and not just representation learning. We will see how current deep clustering methods define and enforce abstraction through centroid-based and density-based clustering losses. Balancing the conflicting goals of abstraction and representation is challenging. Ideas from subspace clustering help by learning one latent space for the information that is relevant to clustering and another latent space to capture all other information in the data. The tutorial ends with an outlook on future research in clustering. Future methods will more adaptively balance abstraction and representation to improve performance, energy efficiency and interpretability. By automatically finding the sweet spot between abstraction and representation, the human brain is very good at clustering and other related tasks such as single-shot learning. So, there is still much room for improvement.
Understanding and Improving Hyperbolic Deep Reinforcement Learning
Dec 16, 2025The performance of reinforcement learning (RL) agents depends critically on the quality of the underlying feature representations. Hyperbolic feature spaces are well-suited for this purpose, as they naturally capture hierarchical and relational structure often present in complex RL environments. However, leveraging these spaces commonly faces optimization challenges due to the nonstationarity of RL. In this work, we identify key factors that determine the success and failure of training hyperbolic deep RL agents. By analyzing the gradients of core operations in the Poincaré Ball and Hyperboloid models of hyperbolic geometry, we show that large-norm embeddings destabilize gradient-based training, leading to trust-region violations in proximal policy optimization (PPO). Based on these insights, we introduce Hyper++, a new hyperbolic PPO agent that consists of three components: (i) stable critic training through a categorical value loss instead of regression; (ii) feature regularization guaranteeing bounded norms while avoiding the curse of dimensionality from clipping; and (iii) using a more optimization-friendly formulation of hyperbolic network layers. In experiments on ProcGen, we show that Hyper++ guarantees stable learning, outperforms prior hyperbolic agents, and reduces wall-clock time by approximately 30%. On Atari-5 with Double DQN, Hyper++ strongly outperforms Euclidean and hyperbolic baselines. We release our code at https://github.com/Probabilistic-and-Interactive-ML/hyper-rl .
H-SPLID: HSIC-based Saliency Preserving Latent Information Decomposition
Oct 23, 2025We introduce H-SPLID, a novel algorithm for learning salient feature representations through the explicit decomposition of salient and non-salient features into separate spaces. We show that H-SPLID promotes learning low-dimensional, task-relevant features. We prove that the expected prediction deviation under input perturbations is upper-bounded by the dimension of the salient subspace and the Hilbert-Schmidt Independence Criterion (HSIC) between inputs and representations. This establishes a link between robustness and latent representation compression in terms of the dimensionality and information preserved. Empirical evaluations on image classification tasks show that models trained with H-SPLID primarily rely on salient input components, as indicated by reduced sensitivity to perturbations affecting non-salient features, such as image backgrounds. Our code is available at https://github.com/neu-spiral/H-SPLID.
Bootstrap Deep Spectral Clustering with Optimal Transport
Aug 06, 2025Spectral clustering is a leading clustering method. Two of its major shortcomings are the disjoint optimization process and the limited representation capacity. To address these issues, we propose a deep spectral clustering model (named BootSC), which jointly learns all stages of spectral clustering -- affinity matrix construction, spectral embedding, and $k$-means clustering -- using a single network in an end-to-end manner. BootSC leverages effective and efficient optimal-transport-derived supervision to bootstrap the affinity matrix and the cluster assignment matrix. Moreover, a semantically-consistent orthogonal re-parameterization technique is introduced to orthogonalize spectral embeddings, significantly enhancing the discrimination capability. Experimental results indicate that BootSC achieves state-of-the-art clustering performance. For example, it accomplishes a notable 16\% NMI improvement over the runner-up method on the challenging ImageNet-Dogs dataset. Our code is available at https://github.com/spdj2271/BootSC.
MultiADS: Defect-aware Supervision for Multi-type Anomaly Detection and Segmentation in Zero-Shot Learning
Apr 09, 2025Precise optical inspection in industrial applications is crucial for minimizing scrap rates and reducing the associated costs. Besides merely detecting if a product is anomalous or not, it is crucial to know the distinct type of defect, such as a bent, cut, or scratch. The ability to recognize the "exact" defect type enables automated treatments of the anomalies in modern production lines. Current methods are limited to solely detecting whether a product is defective or not without providing any insights on the defect type, nevertheless detecting and identifying multiple defects. We propose MultiADS, a zero-shot learning approach, able to perform Multi-type Anomaly Detection and Segmentation. The architecture of MultiADS comprises CLIP and extra linear layers to align the visual- and textual representation in a joint feature space. To the best of our knowledge, our proposal, is the first approach to perform a multi-type anomaly segmentation task in zero-shot learning. Contrary to the other baselines, our approach i) generates specific anomaly masks for each distinct defect type, ii) learns to distinguish defect types, and iii) simultaneously identifies multiple defect types present in an anomalous product. Additionally, our approach outperforms zero/few-shot learning SoTA methods on image-level and pixel-level anomaly detection and segmentation tasks on five commonly used datasets: MVTec-AD, Visa, MPDD, MAD and Real-IAD.
An Introductory Survey to Autoencoder-based Deep Clustering -- Sandboxes for Combining Clustering with Deep Learning
Apr 02, 2025Autoencoders offer a general way of learning low-dimensional, non-linear representations from data without labels. This is achieved without making any particular assumptions about the data type or other domain knowledge. The generality and domain agnosticism in combination with their simplicity make autoencoders a perfect sandbox for researching and developing novel (deep) clustering algorithms. Clustering methods group data based on similarity, a task that benefits from the lower-dimensional representation learned by an autoencoder, mitigating the curse of dimensionality. Specifically, the combination of deep learning with clustering, called Deep Clustering, enables to learn a representation tailored to specific clustering tasks, leading to high-quality results. This survey provides an introduction to fundamental autoencoder-based deep clustering algorithms that serve as building blocks for many modern approaches.
I Want 'Em All (At Once) -- Ultrametric Cluster Hierarchies
Feb 19, 2025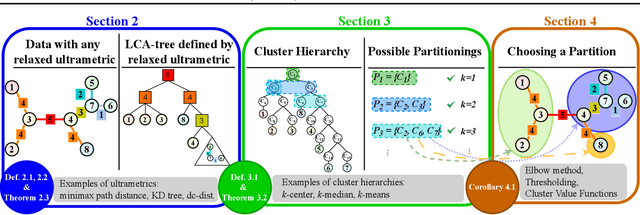

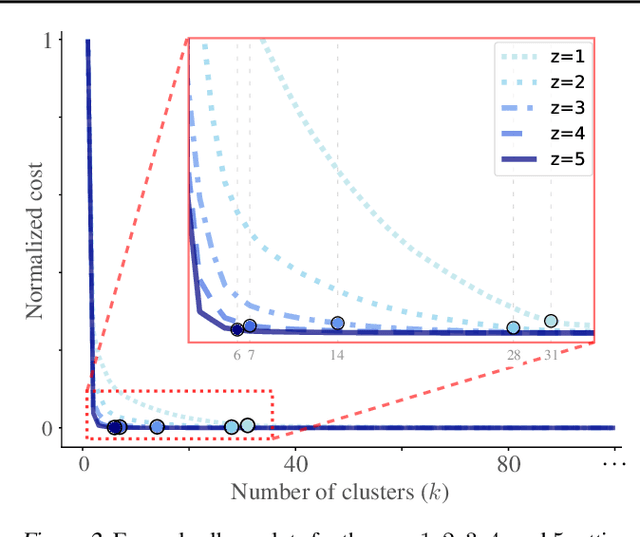
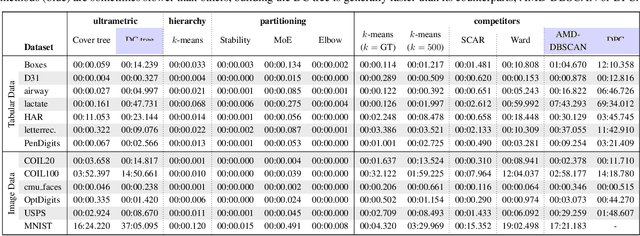
Hierarchical clustering is a powerful tool for exploratory data analysis, organizing data into a tree of clusterings from which a partition can be chosen. This paper generalizes these ideas by proving that, for any reasonable hierarchy, one can optimally solve any center-based clustering objective over it (such as $k$-means). Moreover, these solutions can be found exceedingly quickly and are themselves necessarily hierarchical. Thus, given a cluster tree, we show that one can quickly access a plethora of new, equally meaningful hierarchies. Just as in standard hierarchical clustering, one can then choose any desired partition from these new hierarchies. We conclude by verifying the utility of our proposed techniques across datasets, hierarchies, and partitioning schemes.
Motif Discovery Framework for Psychiatric EEG Data Classification
Jan 08, 2025In current medical practice, patients undergoing depression treatment must wait four to six weeks before a clinician can assess medication response due to the delayed noticeable effects of antidepressants. Identification of a treatment response at any earlier stage is of great importance, since it can reduce the emotional and economic burden connected with the treatment. We approach the prediction of a patient response to a treatment as a classification problem, by utilizing the dynamic properties of EEG recordings on the 7th day of the treatment. We present a novel framework that applies motif discovery to extract meaningful features from EEG data distinguishing between depression treatment responders and non-responders. We applied our framework also to classification tasks in other psychiatric EEG datasets, namely to patients with symptoms of schizophrenia, pediatric patients with intractable seizures, and Alzheimer disease and dementia. We achieved high classification precision in all data sets. The results demonstrate that the dynamic properties of the EEGs may support clinicians in decision making both in diagnosis and in the prediction depression treatment response as early as on the 7th day of the treatment. To our best knowledge, our work is the first one using motifs in the depression diagnostics in general.
Plasticity Loss in Deep Reinforcement Learning: A Survey
Nov 07, 2024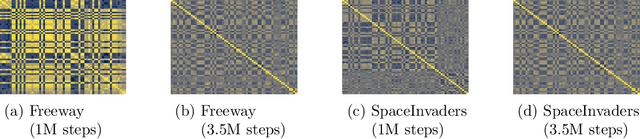
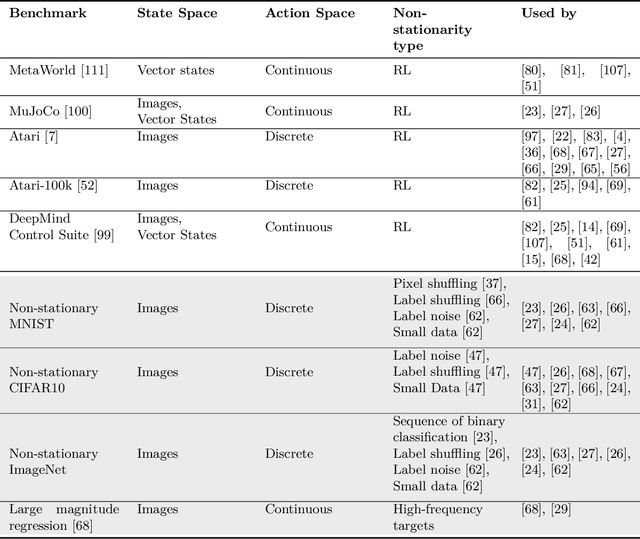
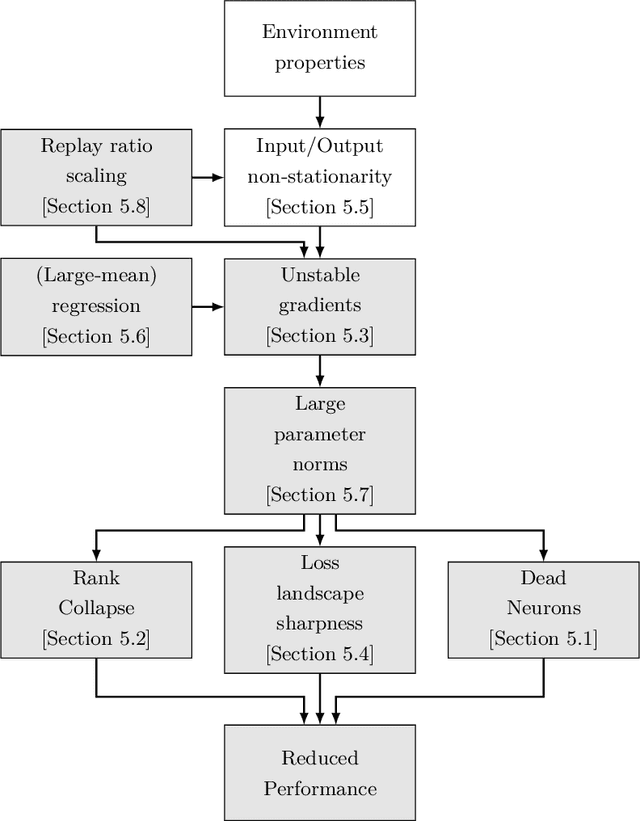

Akin to neuroplasticity in human brains, the plasticity of deep neural networks enables their quick adaption to new data. This makes plasticity particularly crucial for deep Reinforcement Learning (RL) agents: Once plasticity is lost, an agent's performance will inevitably plateau because it cannot improve its policy to account for changes in the data distribution, which are a necessary consequence of its learning process. Thus, developing well-performing and sample-efficient agents hinges on their ability to remain plastic during training. Furthermore, the loss of plasticity can be connected to many other issues plaguing deep RL, such as training instabilities, scaling failures, overestimation bias, and insufficient exploration. With this survey, we aim to provide an overview of the emerging research on plasticity loss for academics and practitioners of deep reinforcement learning. First, we propose a unified definition of plasticity loss based on recent works, relate it to definitions from the literature, and discuss metrics for measuring plasticity loss. Then, we categorize and discuss numerous possible causes of plasticity loss before reviewing currently employed mitigation strategies. Our taxonomy is the first systematic overview of the current state of the field. Lastly, we discuss prevalent issues within the literature, such as a necessity for broader evaluation, and provide recommendations for future research, like gaining a better understanding of an agent's neural activity and behavior.
Breaking the Reclustering Barrier in Centroid-based Deep Clustering
Nov 04, 2024



This work investigates an important phenomenon in centroid-based deep clustering (DC) algorithms: Performance quickly saturates after a period of rapid early gains. Practitioners commonly address early saturation with periodic reclustering, which we demonstrate to be insufficient to address performance plateaus. We call this phenomenon the "reclustering barrier" and empirically show when the reclustering barrier occurs, what its underlying mechanisms are, and how it is possible to Break the Reclustering Barrier with our algorithm BRB. BRB avoids early over-commitment to initial clusterings and enables continuous adaptation to reinitialized clustering targets while remaining conceptually simple. Applying our algorithm to widely-used centroid-based DC algorithms, we show that (1) BRB consistently improves performance across a wide range of clustering benchmarks, (2) BRB enables training from scratch, and (3) BRB performs competitively against state-of-the-art DC algorithms when combined with a contrastive loss. We release our code and pre-trained models at https://github.com/Probabilistic-and-Interactive-ML/breaking-the-reclustering-barrier .