 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Anomaly Detection: Non-Semantic Financial Data Encoding with LLMs
Paper and Code
Jun 05, 2024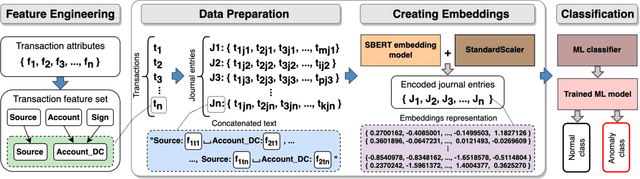

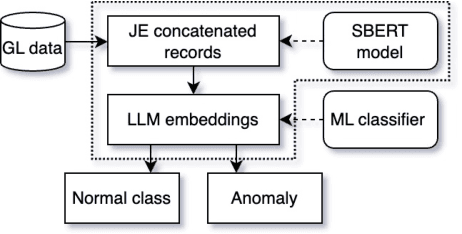

Detecting anomalies in general ledger data is of utmost importance to ensure trustworthiness of financial records. Financial audits increasingly rely on machine learning (ML) algorithms to identify irregular or potentially fraudulent journal entries, each characterized by a varying number of transactions. In machine learning, heterogeneity in feature dimensions adds significant complexity to data analysis. In this paper, we introduce a novel approach to anomaly detection in financial data using Large Language Models (LLMs) embeddings. To encode non-semantic categorical data from real-world financial records, we tested 3 pre-trained general purpose sentence-transformer models. For the downstream classification task, we implemented and evaluated 5 optimized ML models including Logistic Regression, Random Forest, Gradient Boosting Machines, Support Vector Machines, and Neural Networks. Our experiments demonstrate that LLMs contribute valuable information to anomaly detection as our models outperform the baselines, in selected settings even by a large margin. The findings further underscore the effectiveness of LLMs in enhancing anomaly detection in financial journal entries, particularly by tackling feature sparsity. We discuss a promising perspective on using LLM embeddings for non-semantic data in the financial context and beyond.