 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe emergence of Large Language Models (LLM) as a tool in literature reviews: an LLM automated systematic review
Sep 06, 2024Objective: This study aims to summarize the usage of Large Language Models (LLMs) in the process of creating a scientific review. We look at the range of stages in a review that can be automated and assess the current state-of-the-art research projects in the field. Materials and Methods: The search was conducted in June 2024 in PubMed, Scopus, Dimensions, and Google Scholar databases by human reviewers. Screening and extraction process took place in Covidence with the help of LLM add-on which uses OpenAI gpt-4o model. ChatGPT was used to clean extracted data and generate code for figures in this manuscript, ChatGPT and Scite.ai were used in drafting all components of the manuscript, except the methods and discussion sections. Results: 3,788 articles were retrieved, and 172 studies were deemed eligible for the final review. ChatGPT and GPT-based LLM emerged as the most dominant architecture for review automation (n=126, 73.2%). A significant number of review automation projects were found, but only a limited number of papers (n=26, 15.1%) were actual reviews that used LLM during their creation. Most citations focused on automation of a particular stage of review, such as Searching for publications (n=60, 34.9%), and Data extraction (n=54, 31.4%). When comparing pooled performance of GPT-based and BERT-based models, the former were better in data extraction with mean precision 83.0% (SD=10.4), and recall 86.0% (SD=9.8), while being slightly less accurate in title and abstract screening stage (Maccuracy=77.3%, SD=13.0). Discussion/Conclusion: Our LLM-assisted systematic review revealed a significant number of research projects related to review automation using LLMs. The results looked promising, and we anticipate that LLMs will change in the near future the way the scientific reviews are conducted.
Advancing Anomaly Detection: Non-Semantic Financial Data Encoding with LLMs
Jun 05, 2024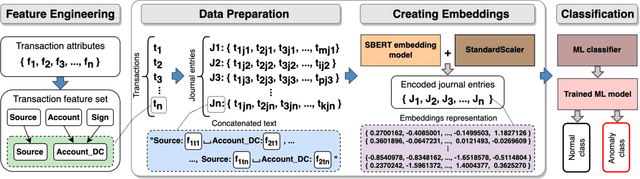

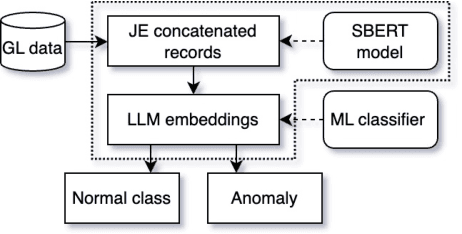

Detecting anomalies in general ledger data is of utmost importance to ensure trustworthiness of financial records. Financial audits increasingly rely on machine learning (ML) algorithms to identify irregular or potentially fraudulent journal entries, each characterized by a varying number of transactions. In machine learning, heterogeneity in feature dimensions adds significant complexity to data analysis. In this paper, we introduce a novel approach to anomaly detection in financial data using Large Language Models (LLMs) embeddings. To encode non-semantic categorical data from real-world financial records, we tested 3 pre-trained general purpose sentence-transformer models. For the downstream classification task, we implemented and evaluated 5 optimized ML models including Logistic Regression, Random Forest, Gradient Boosting Machines, Support Vector Machines, and Neural Networks. Our experiments demonstrate that LLMs contribute valuable information to anomaly detection as our models outperform the baselines, in selected settings even by a large margin. The findings further underscore the effectiveness of LLMs in enhancing anomaly detection in financial journal entries, particularly by tackling feature sparsity. We discuss a promising perspective on using LLM embeddings for non-semantic data in the financial context and beyond.