 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the adaptive and continuous learning capabilities of artificial neural networks: Lessons from multi-neuromodulatory dynamics
Jan 12, 2025



Continuous, adaptive learning-the ability to adapt to the environment and improve performance-is a hallmark of both natural and artificial intelligence. Biological organisms excel in acquiring, transferring, and retaining knowledge while adapting to dynamic environments, making them a rich source of inspiration for artificial neural networks (ANNs). This study explores how neuromodulation, a fundamental feature of biological learning systems, can help address challenges such as catastrophic forgetting and enhance the robustness of ANNs in continuous learning scenarios. Driven by neuromodulators including dopamine (DA), acetylcholine (ACh), serotonin (5-HT) and noradrenaline (NA), neuromodulatory processes in the brain operate at multiple scales, facilitating dynamic responses to environmental changes through mechanisms ranging from local synaptic plasticity to global network-wide adaptability. Importantly, the relationship between neuromodulators, and their interplay in the modulation of sensory and cognitive processes are more complex than expected, demonstrating a "many-to-one" neuromodulator-to-task mapping. To inspire the design of novel neuromodulation-aware learning rules, we highlight (i) how multi-neuromodulatory interactions enrich single-neuromodulator-driven learning, (ii) the impact of neuromodulators at multiple spatial and temporal scales, and correspondingly, (iii) strategies to integrate neuromodulated learning into or approximate it in ANNs. To illustrate these principles, we present a case study to demonstrate how neuromodulation-inspired mechanisms, such as DA-driven reward processing and NA-based cognitive flexibility, can enhance ANN performance in a Go/No-Go task. By integrating multi-scale neuromodulation, we aim to bridge the gap between biological learning and artificial systems, paving the way for ANNs with greater flexibility, robustness, and adaptability.
The emergence of Large Language Models (LLM) as a tool in literature reviews: an LLM automated systematic review
Sep 06, 2024


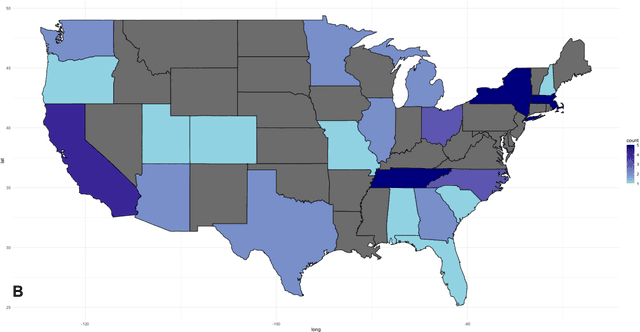
Objective: This study aims to summarize the usage of Large Language Models (LLMs) in the process of creating a scientific review. We look at the range of stages in a review that can be automated and assess the current state-of-the-art research projects in the field. Materials and Methods: The search was conducted in June 2024 in PubMed, Scopus, Dimensions, and Google Scholar databases by human reviewers. Screening and extraction process took place in Covidence with the help of LLM add-on which uses OpenAI gpt-4o model. ChatGPT was used to clean extracted data and generate code for figures in this manuscript, ChatGPT and Scite.ai were used in drafting all components of the manuscript, except the methods and discussion sections. Results: 3,788 articles were retrieved, and 172 studies were deemed eligible for the final review. ChatGPT and GPT-based LLM emerged as the most dominant architecture for review automation (n=126, 73.2%). A significant number of review automation projects were found, but only a limited number of papers (n=26, 15.1%) were actual reviews that used LLM during their creation. Most citations focused on automation of a particular stage of review, such as Searching for publications (n=60, 34.9%), and Data extraction (n=54, 31.4%). When comparing pooled performance of GPT-based and BERT-based models, the former were better in data extraction with mean precision 83.0% (SD=10.4), and recall 86.0% (SD=9.8), while being slightly less accurate in title and abstract screening stage (Maccuracy=77.3%, SD=13.0). Discussion/Conclusion: Our LLM-assisted systematic review revealed a significant number of research projects related to review automation using LLMs. The results looked promising, and we anticipate that LLMs will change in the near future the way the scientific reviews are conducted.