 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCause or Trigger? From Philosophy to Causal Modeling
Apr 02, 2025Not much has been written about the role of triggers in the literature on causal reasoning, causal modeling, or philosophy. In this paper, we focus on describing triggers and causes in the metaphysical sense and on characterizations that differentiate them from each other. We carry out a philosophical analysis of these differences. From this, we formulate a definition that clearly differentiates triggers from causes and can be used for causal reasoning in natural sciences. We propose a mathematical model and the Cause-Trigger algorithm, which, based on given data to observable processes, is able to determine whether a process is a cause or a trigger of an effect. The possibility to distinguish triggers from causes directly from data makes the algorithm a useful tool in natural sciences using observational data, but also for real-world scenarios. For example, knowing the processes that trigger causes of a tropical storm could give politicians time to develop actions such as evacuation the population. Similarly, knowing the triggers of processes that cause global warming could help politicians focus on effective actions. We demonstrate our algorithm on the climatological data of two recent cyclones, Freddy and Zazu. The Cause-Trigger algorithm detects processes that trigger high wind speed in both storms during their cyclogenesis. The findings obtained agree with expert knowledge.
Advancing Anomaly Detection: Non-Semantic Financial Data Encoding with LLMs
Jun 05, 2024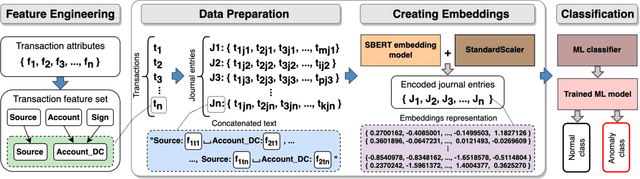

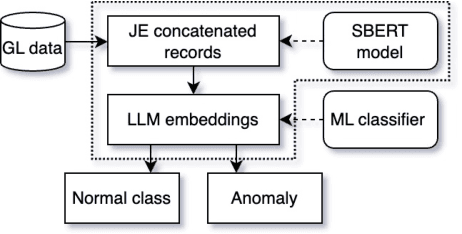

Detecting anomalies in general ledger data is of utmost importance to ensure trustworthiness of financial records. Financial audits increasingly rely on machine learning (ML) algorithms to identify irregular or potentially fraudulent journal entries, each characterized by a varying number of transactions. In machine learning, heterogeneity in feature dimensions adds significant complexity to data analysis. In this paper, we introduce a novel approach to anomaly detection in financial data using Large Language Models (LLMs) embeddings. To encode non-semantic categorical data from real-world financial records, we tested 3 pre-trained general purpose sentence-transformer models. For the downstream classification task, we implemented and evaluated 5 optimized ML models including Logistic Regression, Random Forest, Gradient Boosting Machines, Support Vector Machines, and Neural Networks. Our experiments demonstrate that LLMs contribute valuable information to anomaly detection as our models outperform the baselines, in selected settings even by a large margin. The findings further underscore the effectiveness of LLMs in enhancing anomaly detection in financial journal entries, particularly by tackling feature sparsity. We discuss a promising perspective on using LLM embeddings for non-semantic data in the financial context and beyond.