 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenViewer: Openness-Aware Multi-View Learning
Dec 17, 2024



Multi-view learning methods leverage multiple data sources to enhance perception by mining correlations across views, typically relying on predefined categories. However, deploying these models in real-world scenarios presents two primary openness challenges. 1) Lack of Interpretability: The integration mechanisms of multi-view data in existing black-box models remain poorly explained; 2) Insufficient Generalization: Most models are not adapted to multi-view scenarios involving unknown categories. To address these challenges, we propose OpenViewer, an openness-aware multi-view learning framework with theoretical support. This framework begins with a Pseudo-Unknown Sample Generation Mechanism to efficiently simulate open multi-view environments and previously adapt to potential unknown samples. Subsequently, we introduce an Expression-Enhanced Deep Unfolding Network to intuitively promote interpretability by systematically constructing functional prior-mapping modules and effectively providing a more transparent integration mechanism for multi-view data. Additionally, we establish a Perception-Augmented Open-Set Training Regime to significantly enhance generalization by precisely boosting confidences for known categories and carefully suppressing inappropriate confidences for unknown ones. Experimental results demonstrate that OpenViewer effectively addresses openness challenges while ensuring recognition performance for both known and unknown samples. The code is released at https://github.com/dushide/OpenViewer.
ADEdgeDrop: Adversarial Edge Dropping for Robust Graph Neural Networks
Mar 14, 2024
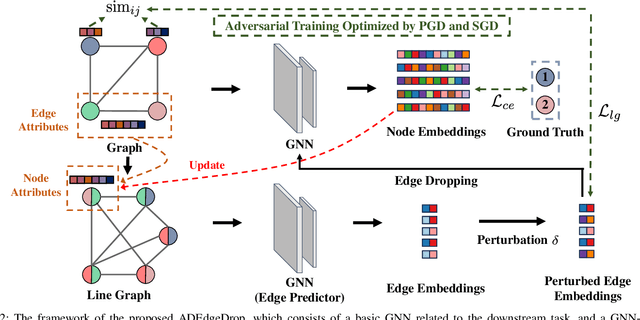

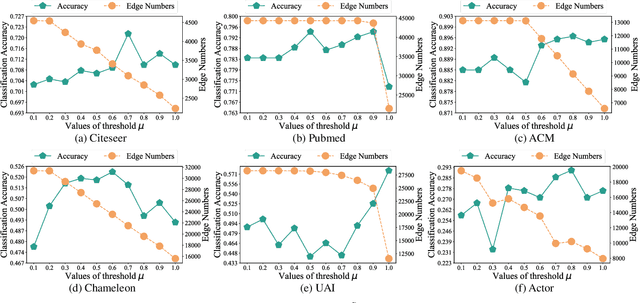
Although Graph Neural Networks (GNNs) have exhibited the powerful ability to gather graph-structured information from neighborhood nodes via various message-passing mechanisms, the performance of GNNs is limited by poor generalization and fragile robustness caused by noisy and redundant graph data. As a prominent solution, Graph Augmentation Learning (GAL) has recently received increasing attention. Among prior GAL approaches, edge-dropping methods that randomly remove edges from a graph during training are effective techniques to improve the robustness of GNNs. However, randomly dropping edges often results in bypassing critical edges, consequently weakening the effectiveness of message passing. In this paper, we propose a novel adversarial edge-dropping method (ADEdgeDrop) that leverages an adversarial edge predictor guiding the removal of edges, which can be flexibly incorporated into diverse GNN backbones. Employing an adversarial training framework, the edge predictor utilizes the line graph transformed from the original graph to estimate the edges to be dropped, which improves the interpretability of the edge-dropping method. The proposed ADEdgeDrop is optimized alternately by stochastic gradient descent and projected gradient descent. Comprehensive experiments on six graph benchmark datasets demonstrate that the proposed ADEdgeDrop outperforms state-of-the-art baselines across various GNN backbones, demonstrating improved generalization and robustness.
FGAD: Self-boosted Knowledge Distillation for An Effective Federated Graph Anomaly Detection Framework
Feb 20, 2024Graph anomaly detection (GAD) aims to identify anomalous graphs that significantly deviate from other ones, which has raised growing attention due to the broad existence and complexity of graph-structured data in many real-world scenarios. However, existing GAD methods usually execute with centralized training, which may lead to privacy leakage risk in some sensitive cases, thereby impeding collaboration among organizations seeking to collectively develop robust GAD models. Although federated learning offers a promising solution, the prevalent non-IID problems and high communication costs present significant challenges, particularly pronounced in collaborations with graph data distributed among different participants. To tackle these challenges, we propose an effective federated graph anomaly detection framework (FGAD). We first introduce an anomaly generator to perturb the normal graphs to be anomalous, and train a powerful anomaly detector by distinguishing generated anomalous graphs from normal ones. Then, we leverage a student model to distill knowledge from the trained anomaly detector (teacher model), which aims to maintain the personality of local models and alleviate the adverse impact of non-IID problems. Moreover, we design an effective collaborative learning mechanism that facilitates the personalization preservation of local models and significantly reduces communication costs among clients. Empirical results of the GAD tasks on non-IID graphs compared with state-of-the-art baselines demonstrate the superiority and efficiency of the proposed FGAD method.
Bridging Trustworthiness and Open-World Learning: An Exploratory Neural Approach for Enhancing Interpretability, Generalization, and Robustness
Aug 07, 2023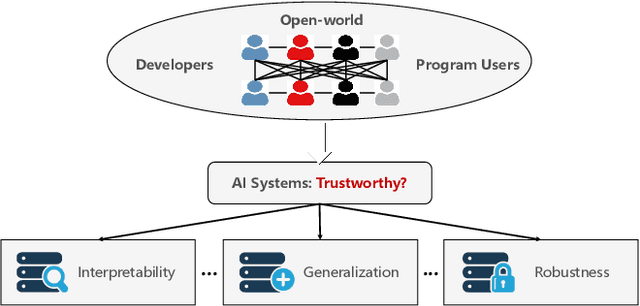

As researchers strive to narrow the gap between machine intelligence and human through the development of artificial intelligence technologies, it is imperative that we recognize the critical importance of trustworthiness in open-world, which has become ubiquitous in all aspects of daily life for everyone. However, several challenges may create a crisis of trust in current artificial intelligence systems that need to be bridged: 1) Insufficient explanation of predictive results; 2) Inadequate generalization for learning models; 3) Poor adaptability to uncertain environments. Consequently, we explore a neural program to bridge trustworthiness and open-world learning, extending from single-modal to multi-modal scenarios for readers. 1) To enhance design-level interpretability, we first customize trustworthy networks with specific physical meanings; 2) We then design environmental well-being task-interfaces via flexible learning regularizers for improving the generalization of trustworthy learning; 3) We propose to increase the robustness of trustworthy learning by integrating open-world recognition losses with agent mechanisms. Eventually, we enhance various trustworthy properties through the establishment of design-level explainability, environmental well-being task-interfaces and open-world recognition programs. These designed open-world protocols are applicable across a wide range of surroundings, under open-world multimedia recognition scenarios with significant performance improvements observed.
High-Similarity-Pass Attention for Single Image Super-Resolution
May 25, 2023Recent developments in the field of non-local attention (NLA) have led to a renewed interest in self-similarity-based single image super-resolution (SISR). Researchers usually used the NLA to explore non-local self-similarity (NSS) in SISR and achieve satisfactory reconstruction results. However, a surprising phenomenon that the reconstruction performance of the standard NLA is similar to the NLA with randomly selected regions stimulated our interest to revisit NLA. In this paper, we first analyzed the attention map of the standard NLA from different perspectives and discovered that the resulting probability distribution always has full support for every local feature, which implies a statistical waste of assigning values to irrelevant non-local features, especially for SISR which needs to model long-range dependence with a large number of redundant non-local features. Based on these findings, we introduced a concise yet effective soft thresholding operation to obtain high-similarity-pass attention (HSPA), which is beneficial for generating a more compact and interpretable distribution. Furthermore, we derived some key properties of the soft thresholding operation that enable training our HSPA in an end-to-end manner. The HSPA can be integrated into existing deep SISR models as an efficient general building block. In addition, to demonstrate the effectiveness of the HSPA, we constructed a deep high-similarity-pass attention network (HSPAN) by integrating a few HSPAs in a simple backbone. Extensive experimental results demonstrate that HSPAN outperforms state-of-the-art approaches on both quantitative and qualitative evaluations.
Attributed Multi-order Graph Convolutional Network for Heterogeneous Graphs
Apr 18, 2023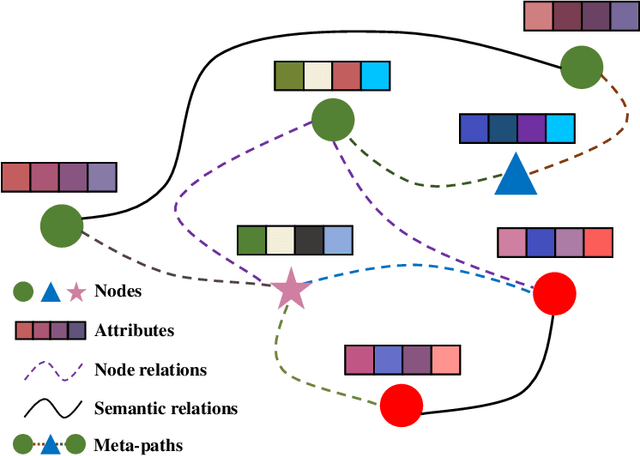
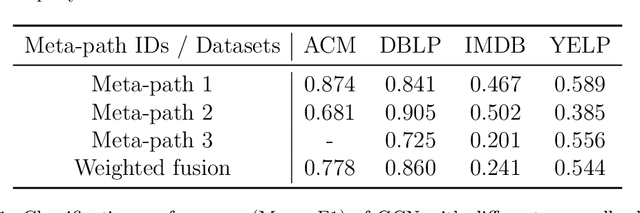
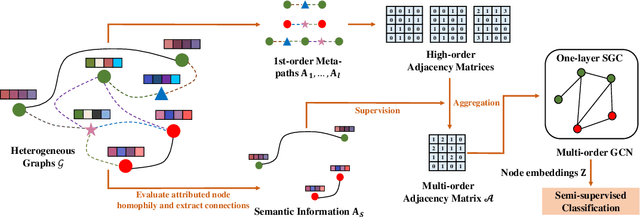
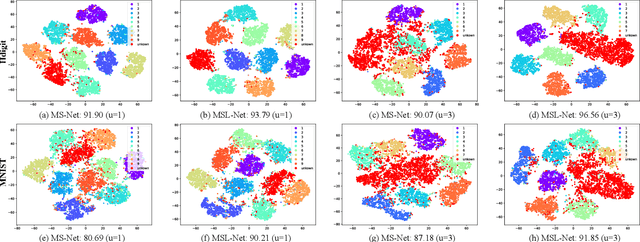
Heterogeneous graph neural networks aim to discover discriminative node embeddings and relations from multi-relational networks.One challenge of heterogeneous graph learning is the design of learnable meta-paths, which significantly influences the quality of learned embeddings.Thus, in this paper, we propose an Attributed Multi-Order Graph Convolutional Network (AMOGCN), which automatically studies meta-paths containing multi-hop neighbors from an adaptive aggregation of multi-order adjacency matrices. The proposed model first builds different orders of adjacency matrices from manually designed node connections. After that, an intact multi-order adjacency matrix is attached from the automatic fusion of various orders of adjacency matrices. This process is supervised by the node semantic information, which is extracted from the node homophily evaluated by attributes. Eventually, we utilize a one-layer simplifying graph convolutional network with the learned multi-order adjacency matrix, which is equivalent to the cross-hop node information propagation with multi-layer graph neural networks. Substantial experiments reveal that AMOGCN gains superior semi-supervised classification performance compared with state-of-the-art competitors.
AGNN: Alternating Graph-Regularized Neural Networks to Alleviate Over-Smoothing
Apr 14, 2023



Graph Convolutional Network (GCN) with the powerful capacity to explore graph-structural data has gained noticeable success in recent years. Nonetheless, most of the existing GCN-based models suffer from the notorious over-smoothing issue, owing to which shallow networks are extensively adopted. This may be problematic for complex graph datasets because a deeper GCN should be beneficial to propagating information across remote neighbors. Recent works have devoted effort to addressing over-smoothing problems, including establishing residual connection structure or fusing predictions from multi-layer models. Because of the indistinguishable embeddings from deep layers, it is reasonable to generate more reliable predictions before conducting the combination of outputs from various layers. In light of this, we propose an Alternating Graph-regularized Neural Network (AGNN) composed of Graph Convolutional Layer (GCL) and Graph Embedding Layer (GEL). GEL is derived from the graph-regularized optimization containing Laplacian embedding term, which can alleviate the over-smoothing problem by periodic projection from the low-order feature space onto the high-order space. With more distinguishable features of distinct layers, an improved Adaboost strategy is utilized to aggregate outputs from each layer, which explores integrated embeddings of multi-hop neighbors. The proposed model is evaluated via a large number of experiments including performance comparison with some multi-layer or multi-order graph neural networks, which reveals the superior performance improvement of AGNN compared with state-of-the-art models.
Properties and Potential Applications of Random Functional-Linked Types of Neural Networks
Apr 03, 2023Random functional-linked types of neural networks (RFLNNs), e.g., the extreme learning machine (ELM) and broad learning system (BLS), which avoid suffering from a time-consuming training process, offer an alternative way of learning in deep structure. The RFLNNs have achieved excellent performance in various classification and regression tasks, however, the properties and explanations of these networks are ignored in previous research. This paper gives some insights into the properties of RFLNNs from the viewpoints of frequency domain, and discovers the presence of frequency principle in these networks, that is, they preferentially capture low-frequencies quickly and then fit the high frequency components during the training process. These findings are valuable for understanding the RFLNNs and expanding their applications. Guided by the frequency principle, we propose a method to generate a BLS network with better performance, and design an efficient algorithm for solving Poison's equation in view of the different frequency principle presenting in the Jacobi iterative method and BLS network.
Deep Graph-Level Clustering Using Pseudo-Label-Guided Mutual Information Maximization Network
Feb 05, 2023In this work, we study the problem of partitioning a set of graphs into different groups such that the graphs in the same group are similar while the graphs in different groups are dissimilar. This problem was rarely studied previously, although there have been a lot of work on node clustering and graph classification. The problem is challenging because it is difficult to measure the similarity or distance between graphs. One feasible approach is using graph kernels to compute a similarity matrix for the graphs and then performing spectral clustering, but the effectiveness of existing graph kernels in measuring the similarity between graphs is very limited. To solve the problem, we propose a novel method called Deep Graph-Level Clustering (DGLC). DGLC utilizes a graph isomorphism network to learn graph-level representations by maximizing the mutual information between the representations of entire graphs and substructures, under the regularization of a clustering module that ensures discriminative representations via pseudo labels. DGLC achieves graph-level representation learning and graph-level clustering in an end-to-end manner. The experimental results on six benchmark datasets of graphs show that our DGLC has state-of-the-art performance in comparison to many baselines.
Multi-view Graph Convolutional Networks with Differentiable Node Selection
Dec 09, 2022



Multi-view data containing complementary and consensus information can facilitate representation learning by exploiting the intact integration of multi-view features. Because most objects in real world often have underlying connections, organizing multi-view data as heterogeneous graphs is beneficial to extracting latent information among different objects. Due to the powerful capability to gather information of neighborhood nodes, in this paper, we apply Graph Convolutional Network (GCN) to cope with heterogeneous-graph data originating from multi-view data, which is still under-explored in the field of GCN. In order to improve the quality of network topology and alleviate the interference of noises yielded by graph fusion, some methods undertake sorting operations before the graph convolution procedure. These GCN-based methods generally sort and select the most confident neighborhood nodes for each vertex, such as picking the top-k nodes according to pre-defined confidence values. Nonetheless, this is problematic due to the non-differentiable sorting operators and inflexible graph embedding learning, which may result in blocked gradient computations and undesired performance. To cope with these issues, we propose a joint framework dubbed Multi-view Graph Convolutional Network with Differentiable Node Selection (MGCN-DNS), which is constituted of an adaptive graph fusion layer, a graph learning module and a differentiable node selection schema. MGCN-DNS accepts multi-channel graph-structural data as inputs and aims to learn more robust graph fusion through a differentiable neural network. The effectiveness of the proposed method is verified by rigorous comparisons with considerable state-of-the-art approaches in terms of multi-view semi-supervised classification tasks.