 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Visual-semantic Alignment for Zero-shot Learning with Ambiguous Labels
Apr 20, 2026Zero-shot learning (ZSL) aims to recognize unseen classes without visual instances. However, existing methods usually assume clean labels, overlooking real-world label noise and ambiguity, which degrades performance. To bridge this gap, we propose the Dynamic Visual-semantic Alignment (DVSA), a robust ZSL framework for learning from ambiguous labels. DVSA uses a bidirectional visual-semantic alignment module with attention to mutually calibrate visual features and attribute prototypes, and a contrastive optimization grounded in Mutual Information (MI) at the attribute level to strengthen discriminative, semantically consistent attributes. In addition, a dynamic label disambiguation mechanism iteratively corrects noisy supervision while preserving semantic consistency, narrowing the instance-label gap, and improving generalization. Extensive experiments on standard benchmarks verify that DVSA achieves stronger performance under ambiguous supervision.
Wavelet-Guided Dual-Frequency Encoding for Remote Sensing Change Detection
Aug 07, 2025Change detection in remote sensing imagery plays a vital role in various engineering applications, such as natural disaster monitoring, urban expansion tracking, and infrastructure management. Despite the remarkable progress of deep learning in recent years, most existing methods still rely on spatial-domain modeling, where the limited diversity of feature representations hinders the detection of subtle change regions. We observe that frequency-domain feature modeling particularly in the wavelet domain an amplify fine-grained differences in frequency components, enhancing the perception of edge changes that are challenging to capture in the spatial domain. Thus, we propose a method called Wavelet-Guided Dual-Frequency Encoding (WGDF). Specifically, we first apply Discrete Wavelet Transform (DWT) to decompose the input images into high-frequency and low-frequency components, which are used to model local details and global structures, respectively. In the high-frequency branch, we design a Dual-Frequency Feature Enhancement (DFFE) module to strengthen edge detail representation and introduce a Frequency-Domain Interactive Difference (FDID) module to enhance the modeling of fine-grained changes. In the low-frequency branch, we exploit Transformers to capture global semantic relationships and employ a Progressive Contextual Difference Module (PCDM) to progressively refine change regions, enabling precise structural semantic characterization. Finally, the high- and low-frequency features are synergistically fused to unify local sensitivity with global discriminability. Extensive experiments on multiple remote sensing datasets demonstrate that WGDF significantly alleviates edge ambiguity and achieves superior detection accuracy and robustness compared to state-of-the-art methods. The code will be available at https://github.com/boshizhang123/WGDF.
FDCE-Net: Underwater Image Enhancement with Embedding Frequency and Dual Color Encoder
Apr 27, 2024



Underwater images often suffer from various issues such as low brightness, color shift, blurred details, and noise due to light absorption and scattering caused by water and suspended particles. Previous underwater image enhancement (UIE) methods have primarily focused on spatial domain enhancement, neglecting the frequency domain information inherent in the images. However, the degradation factors of underwater images are closely intertwined in the spatial domain. Although certain methods focus on enhancing images in the frequency domain, they overlook the inherent relationship between the image degradation factors and the information present in the frequency domain. As a result, these methods frequently enhance certain attributes of the improved image while inadequately addressing or even exacerbating other attributes. Moreover, many existing methods heavily rely on prior knowledge to address color shift problems in underwater images, limiting their flexibility and robustness. In order to overcome these limitations, we propose the Embedding Frequency and Dual Color Encoder Network (FDCE-Net) in our paper. The FDCE-Net consists of two main structures: (1) Frequency Spatial Network (FS-Net) aims to achieve initial enhancement by utilizing our designed Frequency Spatial Residual Block (FSRB) to decouple image degradation factors in the frequency domain and enhance different attributes separately. (2) To tackle the color shift issue, we introduce the Dual-Color Encoder (DCE). The DCE establishes correlations between color and semantic representations through cross-attention and leverages multi-scale image features to guide the optimization of adaptive color query. The final enhanced images are generated by combining the outputs of FS-Net and DCE through a fusion network. These images exhibit rich details, clear textures, low noise and natural colors.
Spatial-frequency Dual-Domain Feature Fusion Network for Low-Light Remote Sensing Image Enhancement
Apr 26, 2024


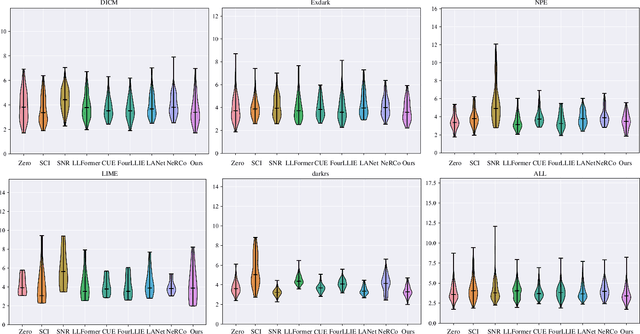
Low-light remote sensing images generally feature high resolution and high spatial complexity, with continuously distributed surface features in space. This continuity in scenes leads to extensive long-range correlations in spatial domains within remote sensing images. Convolutional Neural Networks, which rely on local correlations for long-distance modeling, struggle to establish long-range correlations in such images. On the other hand, transformer-based methods that focus on global information face high computational complexities when processing high-resolution remote sensing images. From another perspective, Fourier transform can compute global information without introducing a large number of parameters, enabling the network to more efficiently capture the overall image structure and establish long-range correlations. Therefore, we propose a Dual-Domain Feature Fusion Network (DFFN) for low-light remote sensing image enhancement. Specifically, this challenging task of low-light enhancement is divided into two more manageable sub-tasks: the first phase learns amplitude information to restore image brightness, and the second phase learns phase information to refine details. To facilitate information exchange between the two phases, we designed an information fusion affine block that combines data from different phases and scales. Additionally, we have constructed two dark light remote sensing datasets to address the current lack of datasets in dark light remote sensing image enhancement. Extensive evaluations show that our method outperforms existing state-of-the-art methods. The code is available at https://github.com/iijjlk/DFFN.
High-Similarity-Pass Attention for Single Image Super-Resolution
May 25, 2023



Recent developments in the field of non-local attention (NLA) have led to a renewed interest in self-similarity-based single image super-resolution (SISR). Researchers usually used the NLA to explore non-local self-similarity (NSS) in SISR and achieve satisfactory reconstruction results. However, a surprising phenomenon that the reconstruction performance of the standard NLA is similar to the NLA with randomly selected regions stimulated our interest to revisit NLA. In this paper, we first analyzed the attention map of the standard NLA from different perspectives and discovered that the resulting probability distribution always has full support for every local feature, which implies a statistical waste of assigning values to irrelevant non-local features, especially for SISR which needs to model long-range dependence with a large number of redundant non-local features. Based on these findings, we introduced a concise yet effective soft thresholding operation to obtain high-similarity-pass attention (HSPA), which is beneficial for generating a more compact and interpretable distribution. Furthermore, we derived some key properties of the soft thresholding operation that enable training our HSPA in an end-to-end manner. The HSPA can be integrated into existing deep SISR models as an efficient general building block. In addition, to demonstrate the effectiveness of the HSPA, we constructed a deep high-similarity-pass attention network (HSPAN) by integrating a few HSPAs in a simple backbone. Extensive experimental results demonstrate that HSPAN outperforms state-of-the-art approaches on both quantitative and qualitative evaluations.
Online Learning Under A Separable Stochastic Approximation Framework
May 20, 2023



We propose an online learning algorithm for a class of machine learning models under a separable stochastic approximation framework. The essence of our idea lies in the observation that certain parameters in the models are easier to optimize than others. In this paper, we focus on models where some parameters have a linear nature, which is common in machine learning. In one routine of the proposed algorithm, the linear parameters are updated by the recursive least squares (RLS) algorithm, which is equivalent to a stochastic Newton method; then, based on the updated linear parameters, the nonlinear parameters are updated by the stochastic gradient method (SGD). The proposed algorithm can be understood as a stochastic approximation version of block coordinate gradient descent approach in which one part of the parameters is updated by a second-order SGD method while the other part is updated by a first-order SGD. Global convergence of the proposed online algorithm for non-convex cases is established in terms of the expected violation of a first-order optimality condition. Numerical experiments show that the proposed method accelerates convergence significantly and produces more robust training and test performance when compared to other popular learning algorithms. Moreover, our algorithm is less sensitive to the learning rate and outperforms the recently proposed slimTrain algorithm (Newman et al., 2022). The code has been uploaded to GitHub for validation.
Properties and Potential Applications of Random Functional-Linked Types of Neural Networks
Apr 03, 2023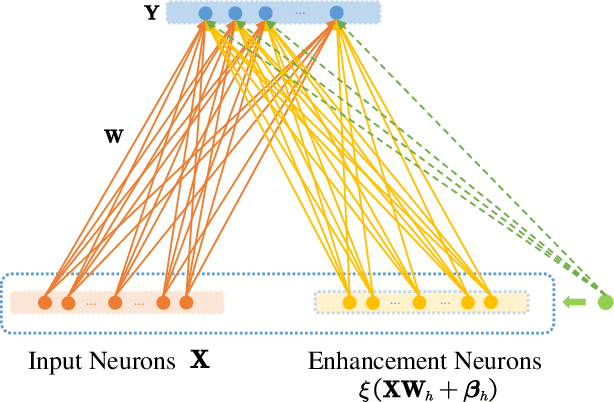
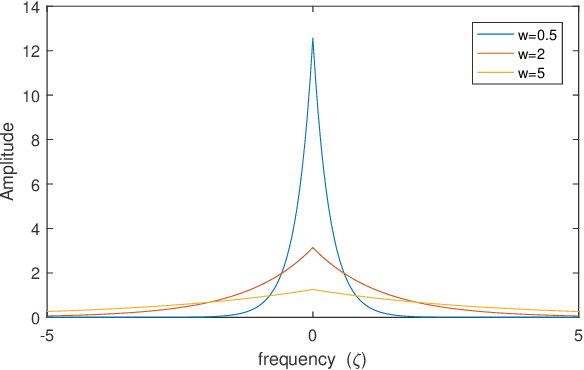
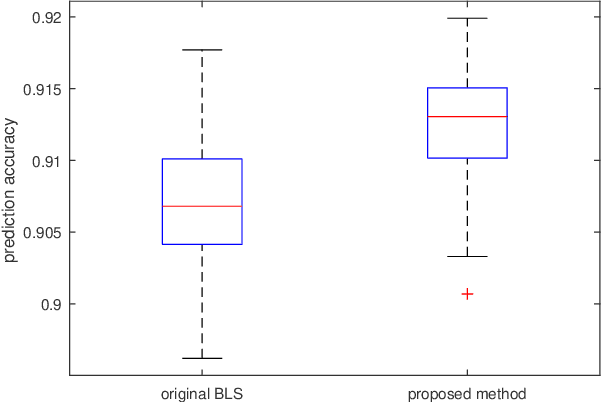
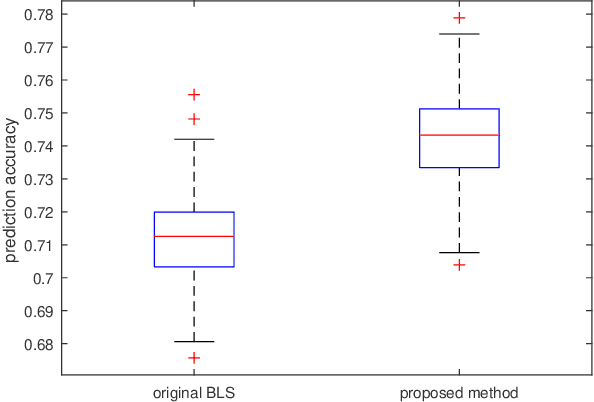
Random functional-linked types of neural networks (RFLNNs), e.g., the extreme learning machine (ELM) and broad learning system (BLS), which avoid suffering from a time-consuming training process, offer an alternative way of learning in deep structure. The RFLNNs have achieved excellent performance in various classification and regression tasks, however, the properties and explanations of these networks are ignored in previous research. This paper gives some insights into the properties of RFLNNs from the viewpoints of frequency domain, and discovers the presence of frequency principle in these networks, that is, they preferentially capture low-frequencies quickly and then fit the high frequency components during the training process. These findings are valuable for understanding the RFLNNs and expanding their applications. Guided by the frequency principle, we propose a method to generate a BLS network with better performance, and design an efficient algorithm for solving Poison's equation in view of the different frequency principle presenting in the Jacobi iterative method and BLS network.
Robust Remote Sensing Scene Classification with Multi-View Voting and Entropy Ranking
Jan 14, 2023Deep convolutional neural networks have been widely used in scene classification of remotely sensed images. In this work, we propose a robust learning method for the task that is secure against partially incorrect categorization of images. Specifically, we remove and correct errors in the labels progressively by iterative multi-view voting and entropy ranking. At each time step, we first divide the training data into disjoint parts for separate training and voting. The unanimity in the voting reveals the correctness of the labels, so that we can train a strong model with only the images with unanimous votes. In addition, we adopt entropy as an effective measure for prediction uncertainty, in order to partially recover labeling errors by ranking and selection. We empirically demonstrate the superiority of the proposed method on the WHU-RS19 dataset and the AID dataset.
Global Learnable Attention for Single Image Super-Resolution
Dec 02, 2022Self-similarity is valuable to the exploration of non-local textures in single image super-resolution (SISR). Researchers usually assume that the importance of non-local textures is positively related to their similarity scores. In this paper, we surprisingly found that when repairing severely damaged query textures, some non-local textures with low-similarity which are closer to the target can provide more accurate and richer details than the high-similarity ones. In these cases, low-similarity does not mean inferior but is usually caused by different scales or orientations. Utilizing this finding, we proposed a Global Learnable Attention (GLA) to adaptively modify similarity scores of non-local textures during training instead of only using a fixed similarity scoring function such as the dot product. The proposed GLA can explore non-local textures with low-similarity but more accurate details to repair severely damaged textures. Furthermore, we propose to adopt Super-Bit Locality-Sensitive Hashing (SB-LSH) as a preprocessing method for our GLA. With the SB-LSH, the computational complexity of our GLA is reduced from quadratic to asymptotic linear with respect to the image size. In addition, the proposed GLA can be integrated into existing deep SISR models as an efficient general building block. Based on the GLA, we constructed a Deep Learnable Similarity Network (DLSN), which achieves state-of-the-art performance for SISR tasks of different degradation types (e.g. blur and noise). Our code and a pre-trained DLSN have been uploaded to GitHub{\dag} for validation.
3D Brain Reconstruction by Hierarchical Shape-Perception Network from a Single Incomplete Image
Jul 23, 2021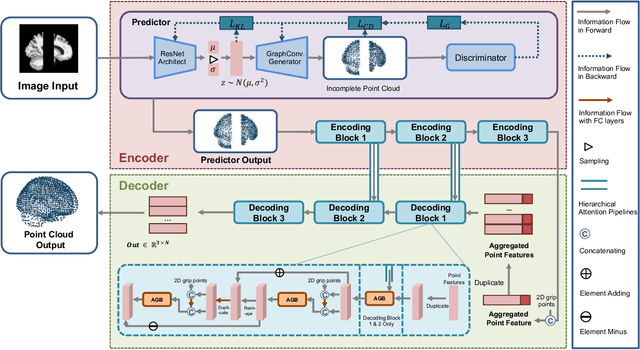
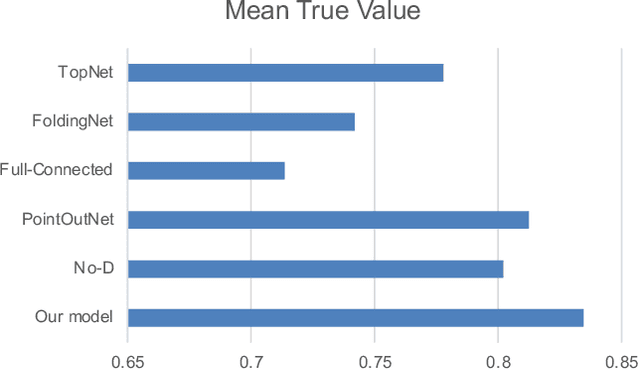
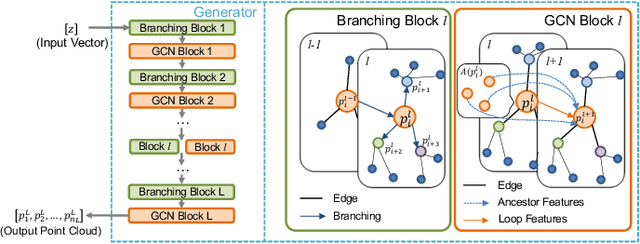
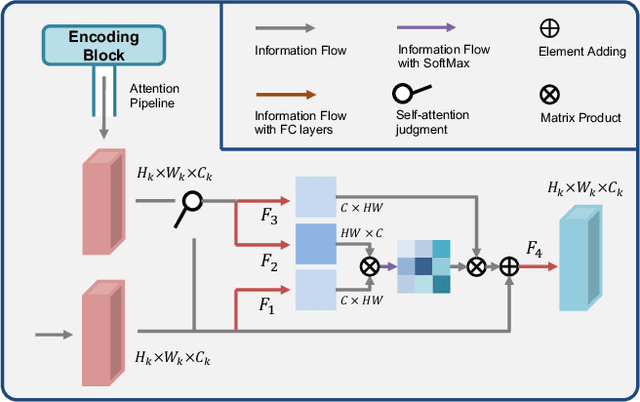
3D shape reconstruction is essential in the navigation of minimally-invasive and auto robot-guided surgeries whose operating environments are indirect and narrow, and there have been some works that focused on reconstructing the 3D shape of the surgical organ through limited 2D information available. However, the lack and incompleteness of such information caused by intraoperative emergencies (such as bleeding) and risk control conditions have not been considered. In this paper, a novel hierarchical shape-perception network (HSPN) is proposed to reconstruct the 3D point clouds (PCs) of specific brains from one single incomplete image with low latency. A tree-structured predictor and several hierarchical attention pipelines are constructed to generate point clouds that accurately describe the incomplete images and then complete these point clouds with high quality. Meanwhile, attention gate blocks (AGBs) are designed to efficiently aggregate geometric local features of incomplete PCs transmitted by hierarchical attention pipelines and internal features of reconstructing point clouds. With the proposed HSPN, 3D shape perception and completion can be achieved spontaneously. Comprehensive results measured by Chamfer distance and PC-to-PC error demonstrate that the performance of the proposed HSPN outperforms other competitive methods in terms of qualitative displays, quantitative experiment, and classification evaluation.