 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Class-Incremental Semantic Segmentation via Pseudo-Labeling and Knowledge Distillation
Aug 05, 2023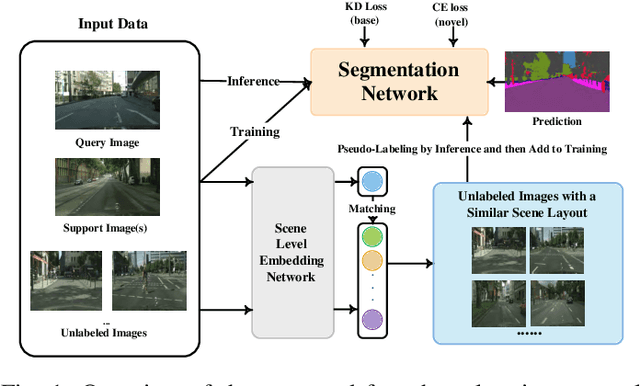


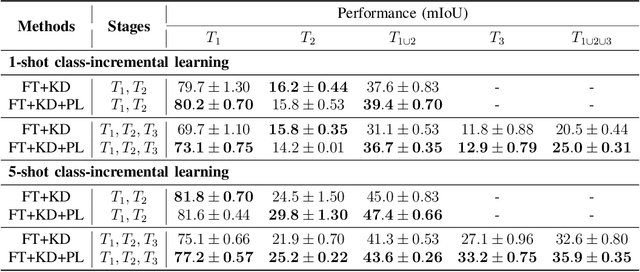
We address the problem of learning new classes for semantic segmentation models from few examples, which is challenging because of the following two reasons. Firstly, it is difficult to learn from limited novel data to capture the underlying class distribution. Secondly, it is challenging to retain knowledge for existing classes and to avoid catastrophic forgetting. For learning from limited data, we propose a pseudo-labeling strategy to augment the few-shot training annotations in order to learn novel classes more effectively. Given only one or a few images labeled with the novel classes and a much larger set of unlabeled images, we transfer the knowledge from labeled images to unlabeled images with a coarse-to-fine pseudo-labeling approach in two steps. Specifically, we first match each labeled image to its nearest neighbors in the unlabeled image set at the scene level, in order to obtain images with a similar scene layout. This is followed by obtaining pseudo-labels within this neighborhood by applying classifiers learned on the few-shot annotations. In addition, we use knowledge distillation on both labeled and unlabeled data to retain knowledge on existing classes. We integrate the above steps into a single convolutional neural network with a unified learning objective. Extensive experiments on the Cityscapes and KITTI datasets validate the efficacy of the proposed approach in the self-driving domain. Code is available from https://github.com/ChasonJiang/FSCILSS.
Robust Remote Sensing Scene Classification with Multi-View Voting and Entropy Ranking
Jan 14, 2023Deep convolutional neural networks have been widely used in scene classification of remotely sensed images. In this work, we propose a robust learning method for the task that is secure against partially incorrect categorization of images. Specifically, we remove and correct errors in the labels progressively by iterative multi-view voting and entropy ranking. At each time step, we first divide the training data into disjoint parts for separate training and voting. The unanimity in the voting reveals the correctness of the labels, so that we can train a strong model with only the images with unanimous votes. In addition, we adopt entropy as an effective measure for prediction uncertainty, in order to partially recover labeling errors by ranking and selection. We empirically demonstrate the superiority of the proposed method on the WHU-RS19 dataset and the AID dataset.