 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Knowledge-Action Gap by Evaluating LLMs in Dynamic Dental Clinical Scenarios
Jan 19, 2026The transition of Large Language Models (LLMs) from passive knowledge retrievers to autonomous clinical agents demands a shift in evaluation-from static accuracy to dynamic behavioral reliability. To explore this boundary in dentistry, a domain where high-quality AI advice uniquely empowers patient-participatory decision-making, we present the Standardized Clinical Management & Performance Evaluation (SCMPE) benchmark, which comprehensively assesses performance from knowledge-oriented evaluations (static objective tasks) to workflow-based simulations (multi-turn simulated patient interactions). Our analysis reveals that while models demonstrate high proficiency in static objective tasks, their performance precipitates in dynamic clinical dialogues, identifying that the primary bottleneck lies not in knowledge retention, but in the critical challenges of active information gathering and dynamic state tracking. Mapping "Guideline Adherence" versus "Decision Quality" reveals a prevalent "High Efficacy, Low Safety" risk in general models. Furthermore, we quantify the impact of Retrieval-Augmented Generation (RAG). While RAG mitigates hallucinations in static tasks, its efficacy in dynamic workflows is limited and heterogeneous, sometimes causing degradation. This underscores that external knowledge alone cannot bridge the reasoning gap without domain-adaptive pre-training. This study empirically charts the capability boundaries of dental LLMs, providing a roadmap for bridging the gap between standardized knowledge and safe, autonomous clinical practice.
From product to system network challenges in system of systems lifecycle management
Oct 31, 2025Today, products are no longer isolated artifacts, but nodes in networked systems. This means that traditional, linearly conceived life cycle models are reaching their limits: Interoperability across disciplines, variant and configuration management, traceability, and governance across organizational boundaries are becoming key factors. This collective contribution classifies the state of the art and proposes a practical frame of reference for SoS lifecycle management, model-based systems engineering (MBSE) as the semantic backbone, product lifecycle management (PLM) as the governance and configuration level, CAD-CAE as model-derived domains, and digital thread and digital twin as continuous feedback. Based on current literature and industry experience, mobility, healthcare, and the public sector, we identify four principles: (1) referenced architecture and data models, (2) end-to-end configuration sovereignty instead of tool silos, (3) curated models with clear review gates, and (4) measurable value contributions along time, quality, cost, and sustainability. A three-step roadmap shows the transition from product- to network- centric development: piloting with reference architecture, scaling across variant and supply chain spaces, organizational anchoring (roles, training, compliance). The results are increased change robustness, shorter throughput times, improved reuse, and informed sustainability decisions. This article is aimed at decision-makers and practitioners who want to make complexity manageable and design SoS value streams to be scalable.
Few-shot Class-Incremental Semantic Segmentation via Pseudo-Labeling and Knowledge Distillation
Aug 05, 2023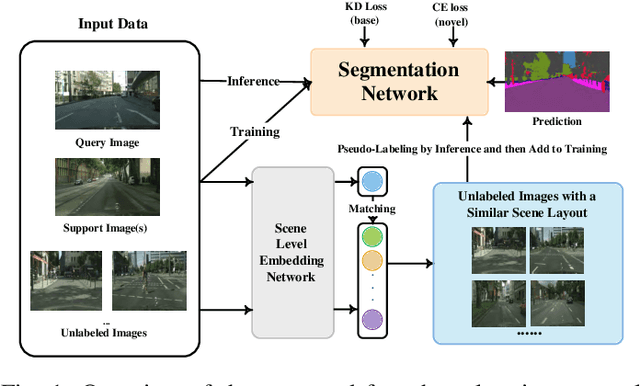


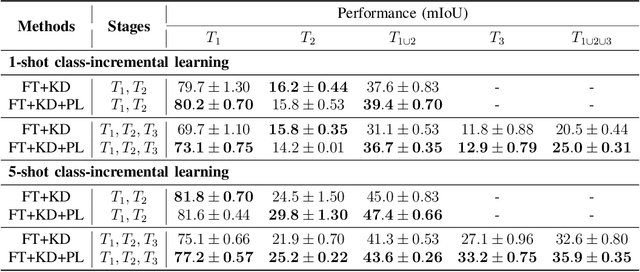
We address the problem of learning new classes for semantic segmentation models from few examples, which is challenging because of the following two reasons. Firstly, it is difficult to learn from limited novel data to capture the underlying class distribution. Secondly, it is challenging to retain knowledge for existing classes and to avoid catastrophic forgetting. For learning from limited data, we propose a pseudo-labeling strategy to augment the few-shot training annotations in order to learn novel classes more effectively. Given only one or a few images labeled with the novel classes and a much larger set of unlabeled images, we transfer the knowledge from labeled images to unlabeled images with a coarse-to-fine pseudo-labeling approach in two steps. Specifically, we first match each labeled image to its nearest neighbors in the unlabeled image set at the scene level, in order to obtain images with a similar scene layout. This is followed by obtaining pseudo-labels within this neighborhood by applying classifiers learned on the few-shot annotations. In addition, we use knowledge distillation on both labeled and unlabeled data to retain knowledge on existing classes. We integrate the above steps into a single convolutional neural network with a unified learning objective. Extensive experiments on the Cityscapes and KITTI datasets validate the efficacy of the proposed approach in the self-driving domain. Code is available from https://github.com/ChasonJiang/FSCILSS.