 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopLLM: Transferable Energy-Latency Attacks in LLMs via Repetitive Generation
Nov 11, 2025



As large language models (LLMs) scale, their inference incurs substantial computational resources, exposing them to energy-latency attacks, where crafted prompts induce high energy and latency cost. Existing attack methods aim to prolong output by delaying the generation of termination symbols. However, as the output grows longer, controlling the termination symbols through input becomes difficult, making these methods less effective. Therefore, we propose LoopLLM, an energy-latency attack framework based on the observation that repetitive generation can trigger low-entropy decoding loops, reliably compelling LLMs to generate until their output limits. LoopLLM introduces (1) a repetition-inducing prompt optimization that exploits autoregressive vulnerabilities to induce repetitive generation, and (2) a token-aligned ensemble optimization that aggregates gradients to improve cross-model transferability. Extensive experiments on 12 open-source and 2 commercial LLMs show that LoopLLM significantly outperforms existing methods, achieving over 90% of the maximum output length, compared to 20% for baselines, and improving transferability by around 40% to DeepSeek-V3 and Gemini 2.5 Flash.
MEAT: Median-Ensemble Adversarial Training for Improving Robustness and Generalization
Jun 20, 2024Self-ensemble adversarial training methods improve model robustness by ensembling models at different training epochs, such as model weight averaging (WA). However, previous research has shown that self-ensemble defense methods in adversarial training (AT) still suffer from robust overfitting, which severely affects the generalization performance. Empirically, in the late phases of training, the AT becomes more overfitting to the extent that the individuals for weight averaging also suffer from overfitting and produce anomalous weight values, which causes the self-ensemble model to continue to undergo robust overfitting due to the failure in removing the weight anomalies. To solve this problem, we aim to tackle the influence of outliers in the weight space in this work and propose an easy-to-operate and effective Median-Ensemble Adversarial Training (MEAT) method to solve the robust overfitting phenomenon existing in self-ensemble defense from the source by searching for the median of the historical model weights. Experimental results show that MEAT achieves the best robustness against the powerful AutoAttack and can effectively allievate the robust overfitting. We further demonstrate that most defense methods can improve robust generalization and robustness by combining with MEAT.
Towards Trustworthy Unsupervised Domain Adaptation: A Representation Learning Perspective for Enhancing Robustness, Discrimination, and Generalization
Jun 19, 2024Robust Unsupervised Domain Adaptation (RoUDA) aims to achieve not only clean but also robust cross-domain knowledge transfer from a labeled source domain to an unlabeled target domain. A number of works have been conducted by directly injecting adversarial training (AT) in UDA based on the self-training pipeline and then aiming to generate better adversarial examples (AEs) for AT. Despite the remarkable progress, these methods only focus on finding stronger AEs but neglect how to better learn from these AEs, thus leading to unsatisfied results. In this paper, we investigate robust UDA from a representation learning perspective and design a novel algorithm by utilizing the mutual information theory, dubbed MIRoUDA. Specifically, through mutual information optimization, MIRoUDA is designed to achieve three characteristics that are highly expected in robust UDA, i.e., robustness, discrimination, and generalization. We then propose a dual-model framework accordingly for robust UDA learning. Extensive experiments on various benchmarks verify the effectiveness of the proposed MIRoUDA, in which our method surpasses the state-of-the-arts by a large margin.
MetaFBP: Learning to Learn High-Order Predictor for Personalized Facial Beauty Prediction
Nov 23, 2023



Predicting individual aesthetic preferences holds significant practical applications and academic implications for human society. However, existing studies mainly focus on learning and predicting the commonality of facial attractiveness, with little attention given to Personalized Facial Beauty Prediction (PFBP). PFBP aims to develop a machine that can adapt to individual aesthetic preferences with only a few images rated by each user. In this paper, we formulate this task from a meta-learning perspective that each user corresponds to a meta-task. To address such PFBP task, we draw inspiration from the human aesthetic mechanism that visual aesthetics in society follows a Gaussian distribution, which motivates us to disentangle user preferences into a commonality and an individuality part. To this end, we propose a novel MetaFBP framework, in which we devise a universal feature extractor to capture the aesthetic commonality and then optimize to adapt the aesthetic individuality by shifting the decision boundary of the predictor via a meta-learning mechanism. Unlike conventional meta-learning methods that may struggle with slow adaptation or overfitting to tiny support sets, we propose a novel approach that optimizes a high-order predictor for fast adaptation. In order to validate the performance of the proposed method, we build several PFBP benchmarks by using existing facial beauty prediction datasets rated by numerous users. Extensive experiments on these benchmarks demonstrate the effectiveness of the proposed MetaFBP method.
An Adaptive Model Ensemble Adversarial Attack for Boosting Adversarial Transferability
Aug 05, 2023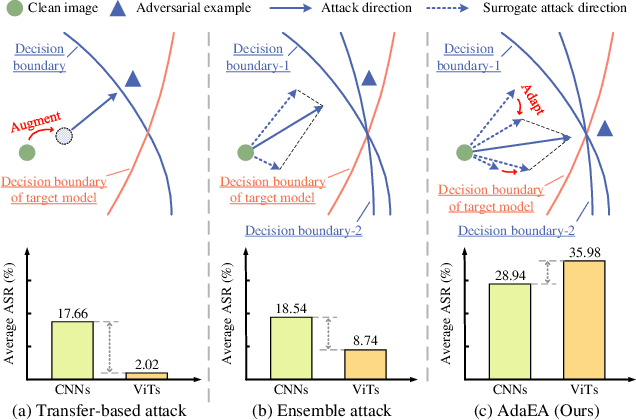
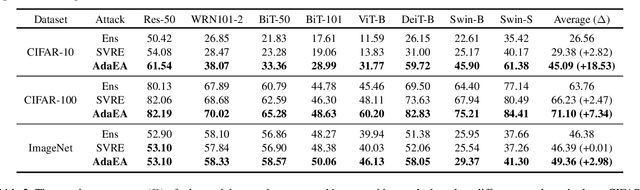
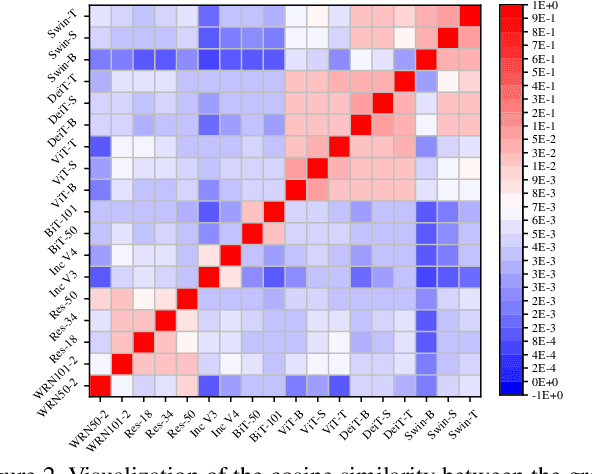
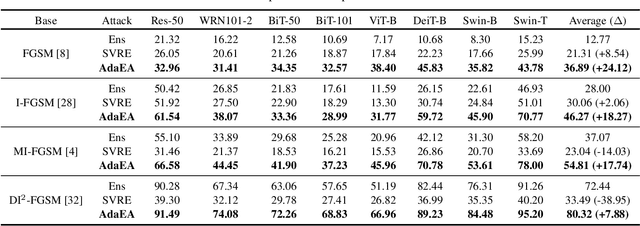
While the transferability property of adversarial examples allows the adversary to perform black-box attacks (i.e., the attacker has no knowledge about the target model), the transfer-based adversarial attacks have gained great attention. Previous works mostly study gradient variation or image transformations to amplify the distortion on critical parts of inputs. These methods can work on transferring across models with limited differences, i.e., from CNNs to CNNs, but always fail in transferring across models with wide differences, such as from CNNs to ViTs. Alternatively, model ensemble adversarial attacks are proposed to fuse outputs from surrogate models with diverse architectures to get an ensemble loss, making the generated adversarial example more likely to transfer to other models as it can fool multiple models concurrently. However, existing ensemble attacks simply fuse the outputs of the surrogate models evenly, thus are not efficacious to capture and amplify the intrinsic transfer information of adversarial examples. In this paper, we propose an adaptive ensemble attack, dubbed AdaEA, to adaptively control the fusion of the outputs from each model, via monitoring the discrepancy ratio of their contributions towards the adversarial objective. Furthermore, an extra disparity-reduced filter is introduced to further synchronize the update direction. As a result, we achieve considerable improvement over the existing ensemble attacks on various datasets, and the proposed AdaEA can also boost existing transfer-based attacks, which further demonstrates its efficacy and versatility.
SRoUDA: Meta Self-training for Robust Unsupervised Domain Adaptation
Dec 12, 2022As acquiring manual labels on data could be costly, unsupervised domain adaptation (UDA), which transfers knowledge learned from a rich-label dataset to the unlabeled target dataset, is gaining increasing popularity. While extensive studies have been devoted to improving the model accuracy on target domain, an important issue of model robustness is neglected. To make things worse, conventional adversarial training (AT) methods for improving model robustness are inapplicable under UDA scenario since they train models on adversarial examples that are generated by supervised loss function. In this paper, we present a new meta self-training pipeline, named SRoUDA, for improving adversarial robustness of UDA models. Based on self-training paradigm, SRoUDA starts with pre-training a source model by applying UDA baseline on source labeled data and taraget unlabeled data with a developed random masked augmentation (RMA), and then alternates between adversarial target model training on pseudo-labeled target data and finetuning source model by a meta step. While self-training allows the direct incorporation of AT in UDA, the meta step in SRoUDA further helps in mitigating error propagation from noisy pseudo labels. Extensive experiments on various benchmark datasets demonstrate the state-of-the-art performance of SRoUDA where it achieves significant model robustness improvement without harming clean accuracy. Code is available at https://github.com/Vision.
Global Learnable Attention for Single Image Super-Resolution
Dec 02, 2022Self-similarity is valuable to the exploration of non-local textures in single image super-resolution (SISR). Researchers usually assume that the importance of non-local textures is positively related to their similarity scores. In this paper, we surprisingly found that when repairing severely damaged query textures, some non-local textures with low-similarity which are closer to the target can provide more accurate and richer details than the high-similarity ones. In these cases, low-similarity does not mean inferior but is usually caused by different scales or orientations. Utilizing this finding, we proposed a Global Learnable Attention (GLA) to adaptively modify similarity scores of non-local textures during training instead of only using a fixed similarity scoring function such as the dot product. The proposed GLA can explore non-local textures with low-similarity but more accurate details to repair severely damaged textures. Furthermore, we propose to adopt Super-Bit Locality-Sensitive Hashing (SB-LSH) as a preprocessing method for our GLA. With the SB-LSH, the computational complexity of our GLA is reduced from quadratic to asymptotic linear with respect to the image size. In addition, the proposed GLA can be integrated into existing deep SISR models as an efficient general building block. Based on the GLA, we constructed a Deep Learnable Similarity Network (DLSN), which achieves state-of-the-art performance for SISR tasks of different degradation types (e.g. blur and noise). Our code and a pre-trained DLSN have been uploaded to GitHub{\dag} for validation.
Push Stricter to Decide Better: A Class-Conditional Feature Adaptive Framework for Improving Adversarial Robustness
Dec 01, 2021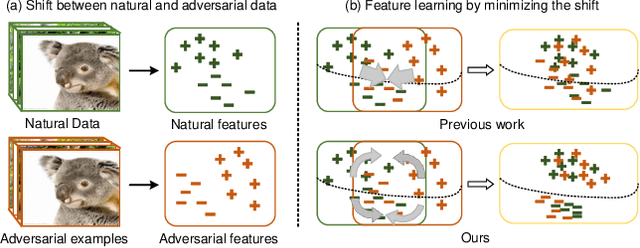
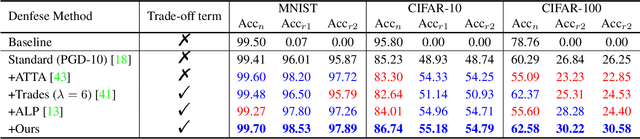
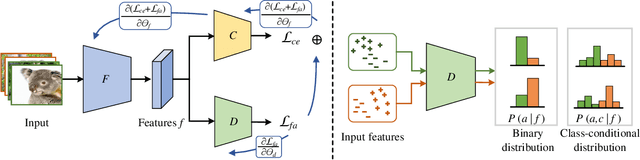
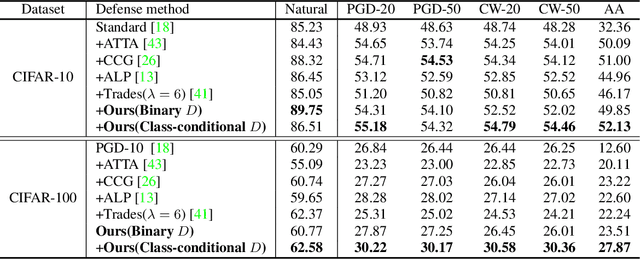
In response to the threat of adversarial examples, adversarial training provides an attractive option for enhancing the model robustness by training models on online-augmented adversarial examples. However, most of the existing adversarial training methods focus on improving the robust accuracy by strengthening the adversarial examples but neglecting the increasing shift between natural data and adversarial examples, leading to a dramatic decrease in natural accuracy. To maintain the trade-off between natural and robust accuracy, we alleviate the shift from the perspective of feature adaption and propose a Feature Adaptive Adversarial Training (FAAT) optimizing the class-conditional feature adaption across natural data and adversarial examples. Specifically, we propose to incorporate a class-conditional discriminator to encourage the features become (1) class-discriminative and (2) invariant to the change of adversarial attacks. The novel FAAT framework enables the trade-off between natural and robust accuracy by generating features with similar distribution across natural and adversarial data, and achieve higher overall robustness benefited from the class-discriminative feature characteristics. Experiments on various datasets demonstrate that FAAT produces more discriminative features and performs favorably against state-of-the-art methods. Codes are available at https://github.com/VisionFlow/FAAT.
Robust Single-step Adversarial Training with Regularizer
Feb 05, 2021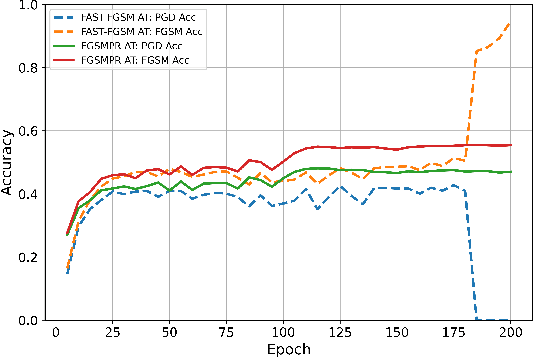

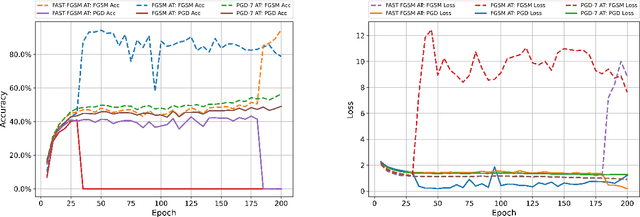

High cost of training time caused by multi-step adversarial example generation is a major challenge in adversarial training. Previous methods try to reduce the computational burden of adversarial training using single-step adversarial example generation schemes, which can effectively improve the efficiency but also introduce the problem of catastrophic overfitting, where the robust accuracy against Fast Gradient Sign Method (FGSM) can achieve nearby 100\% whereas the robust accuracy against Projected Gradient Descent (PGD) suddenly drops to 0\% over a single epoch. To address this problem, we propose a novel Fast Gradient Sign Method with PGD Regularization (FGSMPR) to boost the efficiency of adversarial training without catastrophic overfitting. Our core idea is that single-step adversarial training can not learn robust internal representations of FGSM and PGD adversarial examples. Therefore, we design a PGD regularization term to encourage similar embeddings of FGSM and PGD adversarial examples. The experiments demonstrate that our proposed method can train a robust deep network for L$_\infty$-perturbations with FGSM adversarial training and reduce the gap to multi-step adversarial training.