 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRoUDA: Meta Self-training for Robust Unsupervised Domain Adaptation
Dec 12, 2022As acquiring manual labels on data could be costly, unsupervised domain adaptation (UDA), which transfers knowledge learned from a rich-label dataset to the unlabeled target dataset, is gaining increasing popularity. While extensive studies have been devoted to improving the model accuracy on target domain, an important issue of model robustness is neglected. To make things worse, conventional adversarial training (AT) methods for improving model robustness are inapplicable under UDA scenario since they train models on adversarial examples that are generated by supervised loss function. In this paper, we present a new meta self-training pipeline, named SRoUDA, for improving adversarial robustness of UDA models. Based on self-training paradigm, SRoUDA starts with pre-training a source model by applying UDA baseline on source labeled data and taraget unlabeled data with a developed random masked augmentation (RMA), and then alternates between adversarial target model training on pseudo-labeled target data and finetuning source model by a meta step. While self-training allows the direct incorporation of AT in UDA, the meta step in SRoUDA further helps in mitigating error propagation from noisy pseudo labels. Extensive experiments on various benchmark datasets demonstrate the state-of-the-art performance of SRoUDA where it achieves significant model robustness improvement without harming clean accuracy. Code is available at https://github.com/Vision.
Universal Generative Modeling for Calibration-free Parallel Mr Imaging
Jan 25, 2022
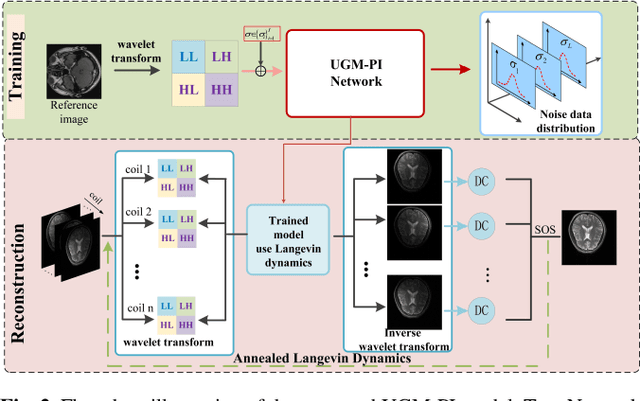


The integration of compressed sensing and parallel imaging (CS-PI) provides a robust mechanism for accelerating MRI acquisitions. However, most such strategies require the explicit formation of either coil sensitivity profiles or a cross-coil correlation operator, and as a result reconstruction corresponds to solving a challenging bilinear optimization problem. In this work, we present an unsupervised deep learning framework for calibration-free parallel MRI, coined universal generative modeling for parallel imaging (UGM-PI). More precisely, we make use of the merits of both wavelet transform and the adaptive iteration strategy in a unified framework. We train a powerful noise conditional score network by forming wavelet tensor as the network input at the training phase. Experimental results on both physical phantom and in vivo datasets implied that the proposed method is comparable and even superior to state-of-the-art CS-PI reconstruction approaches.
Push Stricter to Decide Better: A Class-Conditional Feature Adaptive Framework for Improving Adversarial Robustness
Dec 01, 2021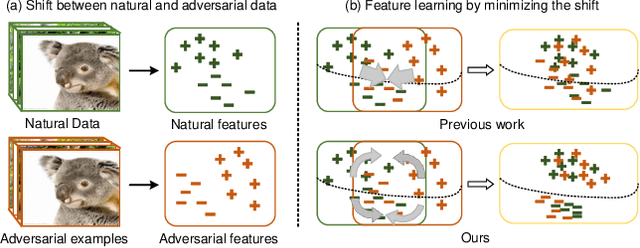
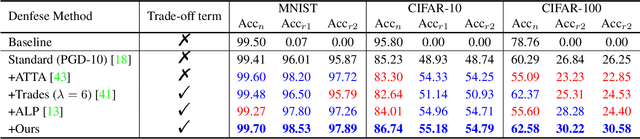
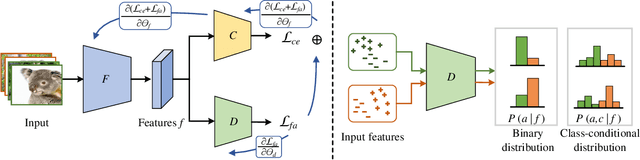
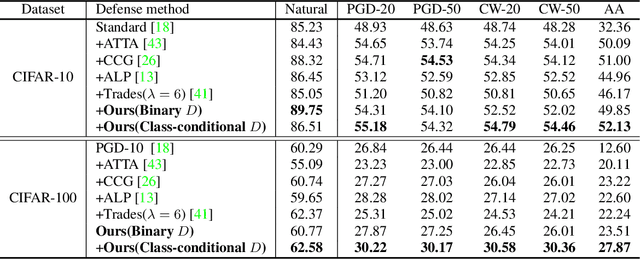
In response to the threat of adversarial examples, adversarial training provides an attractive option for enhancing the model robustness by training models on online-augmented adversarial examples. However, most of the existing adversarial training methods focus on improving the robust accuracy by strengthening the adversarial examples but neglecting the increasing shift between natural data and adversarial examples, leading to a dramatic decrease in natural accuracy. To maintain the trade-off between natural and robust accuracy, we alleviate the shift from the perspective of feature adaption and propose a Feature Adaptive Adversarial Training (FAAT) optimizing the class-conditional feature adaption across natural data and adversarial examples. Specifically, we propose to incorporate a class-conditional discriminator to encourage the features become (1) class-discriminative and (2) invariant to the change of adversarial attacks. The novel FAAT framework enables the trade-off between natural and robust accuracy by generating features with similar distribution across natural and adversarial data, and achieve higher overall robustness benefited from the class-discriminative feature characteristics. Experiments on various datasets demonstrate that FAAT produces more discriminative features and performs favorably against state-of-the-art methods. Codes are available at https://github.com/VisionFlow/FAAT.