 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePush Stricter to Decide Better: A Class-Conditional Feature Adaptive Framework for Improving Adversarial Robustness
Dec 01, 2021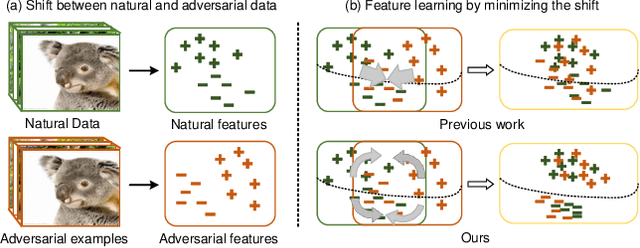
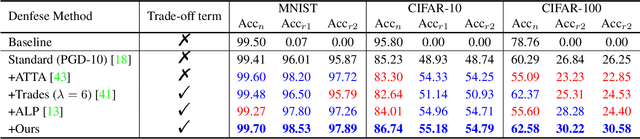
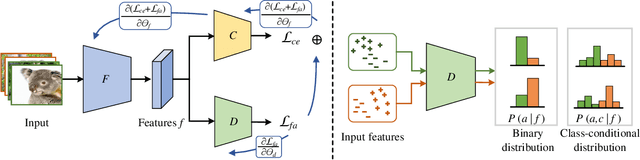
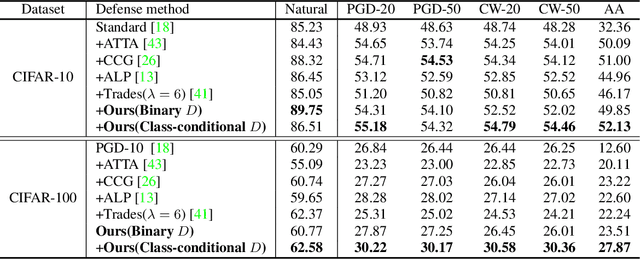
In response to the threat of adversarial examples, adversarial training provides an attractive option for enhancing the model robustness by training models on online-augmented adversarial examples. However, most of the existing adversarial training methods focus on improving the robust accuracy by strengthening the adversarial examples but neglecting the increasing shift between natural data and adversarial examples, leading to a dramatic decrease in natural accuracy. To maintain the trade-off between natural and robust accuracy, we alleviate the shift from the perspective of feature adaption and propose a Feature Adaptive Adversarial Training (FAAT) optimizing the class-conditional feature adaption across natural data and adversarial examples. Specifically, we propose to incorporate a class-conditional discriminator to encourage the features become (1) class-discriminative and (2) invariant to the change of adversarial attacks. The novel FAAT framework enables the trade-off between natural and robust accuracy by generating features with similar distribution across natural and adversarial data, and achieve higher overall robustness benefited from the class-discriminative feature characteristics. Experiments on various datasets demonstrate that FAAT produces more discriminative features and performs favorably against state-of-the-art methods. Codes are available at https://github.com/VisionFlow/FAAT.
Robust Single-step Adversarial Training with Regularizer
Feb 05, 2021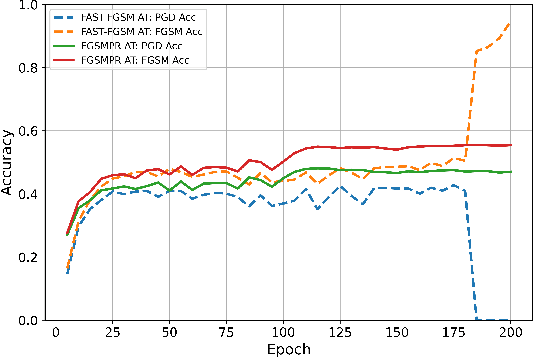

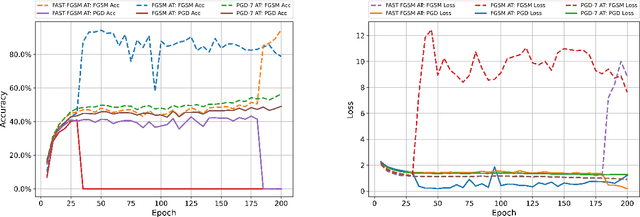

High cost of training time caused by multi-step adversarial example generation is a major challenge in adversarial training. Previous methods try to reduce the computational burden of adversarial training using single-step adversarial example generation schemes, which can effectively improve the efficiency but also introduce the problem of catastrophic overfitting, where the robust accuracy against Fast Gradient Sign Method (FGSM) can achieve nearby 100\% whereas the robust accuracy against Projected Gradient Descent (PGD) suddenly drops to 0\% over a single epoch. To address this problem, we propose a novel Fast Gradient Sign Method with PGD Regularization (FGSMPR) to boost the efficiency of adversarial training without catastrophic overfitting. Our core idea is that single-step adversarial training can not learn robust internal representations of FGSM and PGD adversarial examples. Therefore, we design a PGD regularization term to encourage similar embeddings of FGSM and PGD adversarial examples. The experiments demonstrate that our proposed method can train a robust deep network for L$_\infty$-perturbations with FGSM adversarial training and reduce the gap to multi-step adversarial training.