 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEAT: Median-Ensemble Adversarial Training for Improving Robustness and Generalization
Jun 20, 2024Self-ensemble adversarial training methods improve model robustness by ensembling models at different training epochs, such as model weight averaging (WA). However, previous research has shown that self-ensemble defense methods in adversarial training (AT) still suffer from robust overfitting, which severely affects the generalization performance. Empirically, in the late phases of training, the AT becomes more overfitting to the extent that the individuals for weight averaging also suffer from overfitting and produce anomalous weight values, which causes the self-ensemble model to continue to undergo robust overfitting due to the failure in removing the weight anomalies. To solve this problem, we aim to tackle the influence of outliers in the weight space in this work and propose an easy-to-operate and effective Median-Ensemble Adversarial Training (MEAT) method to solve the robust overfitting phenomenon existing in self-ensemble defense from the source by searching for the median of the historical model weights. Experimental results show that MEAT achieves the best robustness against the powerful AutoAttack and can effectively allievate the robust overfitting. We further demonstrate that most defense methods can improve robust generalization and robustness by combining with MEAT.
An Adaptive Model Ensemble Adversarial Attack for Boosting Adversarial Transferability
Aug 05, 2023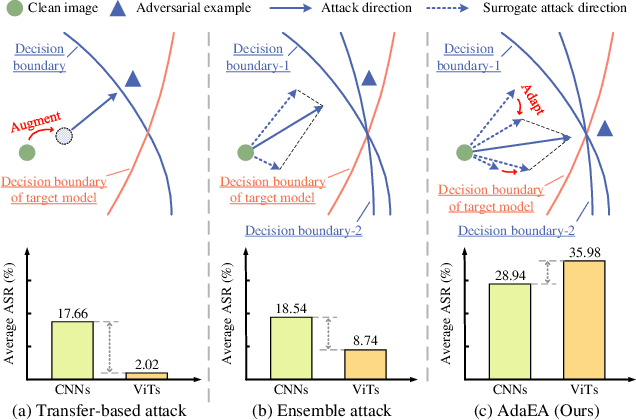
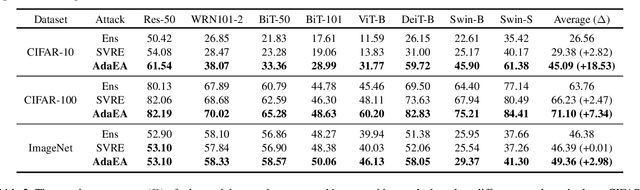
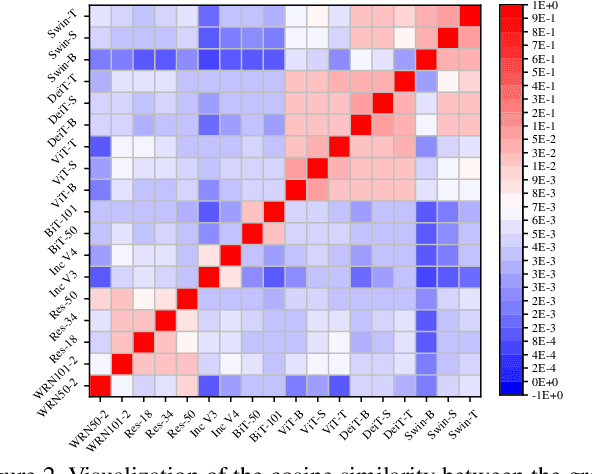
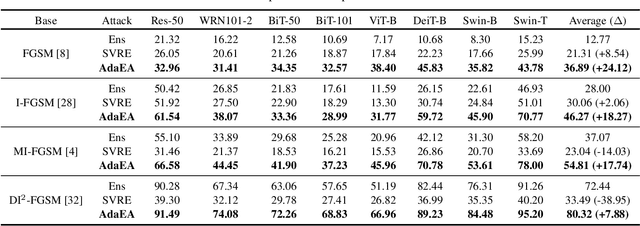
While the transferability property of adversarial examples allows the adversary to perform black-box attacks (i.e., the attacker has no knowledge about the target model), the transfer-based adversarial attacks have gained great attention. Previous works mostly study gradient variation or image transformations to amplify the distortion on critical parts of inputs. These methods can work on transferring across models with limited differences, i.e., from CNNs to CNNs, but always fail in transferring across models with wide differences, such as from CNNs to ViTs. Alternatively, model ensemble adversarial attacks are proposed to fuse outputs from surrogate models with diverse architectures to get an ensemble loss, making the generated adversarial example more likely to transfer to other models as it can fool multiple models concurrently. However, existing ensemble attacks simply fuse the outputs of the surrogate models evenly, thus are not efficacious to capture and amplify the intrinsic transfer information of adversarial examples. In this paper, we propose an adaptive ensemble attack, dubbed AdaEA, to adaptively control the fusion of the outputs from each model, via monitoring the discrepancy ratio of their contributions towards the adversarial objective. Furthermore, an extra disparity-reduced filter is introduced to further synchronize the update direction. As a result, we achieve considerable improvement over the existing ensemble attacks on various datasets, and the proposed AdaEA can also boost existing transfer-based attacks, which further demonstrates its efficacy and versatility.
SRoUDA: Meta Self-training for Robust Unsupervised Domain Adaptation
Dec 12, 2022As acquiring manual labels on data could be costly, unsupervised domain adaptation (UDA), which transfers knowledge learned from a rich-label dataset to the unlabeled target dataset, is gaining increasing popularity. While extensive studies have been devoted to improving the model accuracy on target domain, an important issue of model robustness is neglected. To make things worse, conventional adversarial training (AT) methods for improving model robustness are inapplicable under UDA scenario since they train models on adversarial examples that are generated by supervised loss function. In this paper, we present a new meta self-training pipeline, named SRoUDA, for improving adversarial robustness of UDA models. Based on self-training paradigm, SRoUDA starts with pre-training a source model by applying UDA baseline on source labeled data and taraget unlabeled data with a developed random masked augmentation (RMA), and then alternates between adversarial target model training on pseudo-labeled target data and finetuning source model by a meta step. While self-training allows the direct incorporation of AT in UDA, the meta step in SRoUDA further helps in mitigating error propagation from noisy pseudo labels. Extensive experiments on various benchmark datasets demonstrate the state-of-the-art performance of SRoUDA where it achieves significant model robustness improvement without harming clean accuracy. Code is available at https://github.com/Vision.
Push Stricter to Decide Better: A Class-Conditional Feature Adaptive Framework for Improving Adversarial Robustness
Dec 01, 2021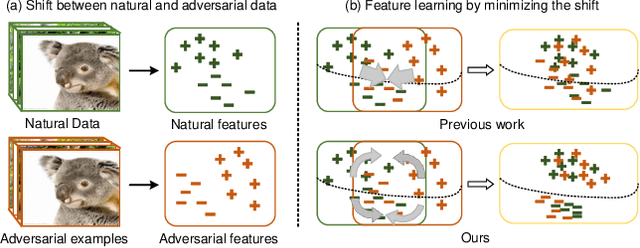
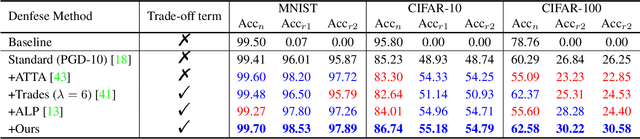
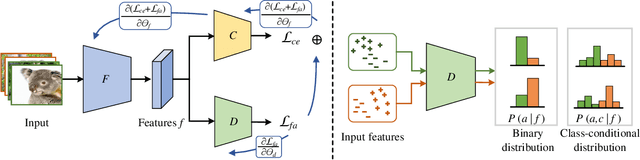
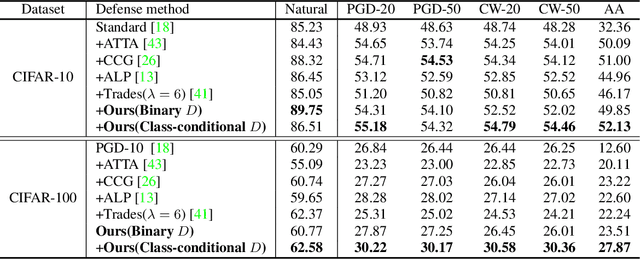
In response to the threat of adversarial examples, adversarial training provides an attractive option for enhancing the model robustness by training models on online-augmented adversarial examples. However, most of the existing adversarial training methods focus on improving the robust accuracy by strengthening the adversarial examples but neglecting the increasing shift between natural data and adversarial examples, leading to a dramatic decrease in natural accuracy. To maintain the trade-off between natural and robust accuracy, we alleviate the shift from the perspective of feature adaption and propose a Feature Adaptive Adversarial Training (FAAT) optimizing the class-conditional feature adaption across natural data and adversarial examples. Specifically, we propose to incorporate a class-conditional discriminator to encourage the features become (1) class-discriminative and (2) invariant to the change of adversarial attacks. The novel FAAT framework enables the trade-off between natural and robust accuracy by generating features with similar distribution across natural and adversarial data, and achieve higher overall robustness benefited from the class-discriminative feature characteristics. Experiments on various datasets demonstrate that FAAT produces more discriminative features and performs favorably against state-of-the-art methods. Codes are available at https://github.com/VisionFlow/FAAT.