 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
ASPD: Unlocking Adaptive Serial-Parallel Decoding by Exploring Intrinsic Parallelism in LLMs
Aug 12, 2025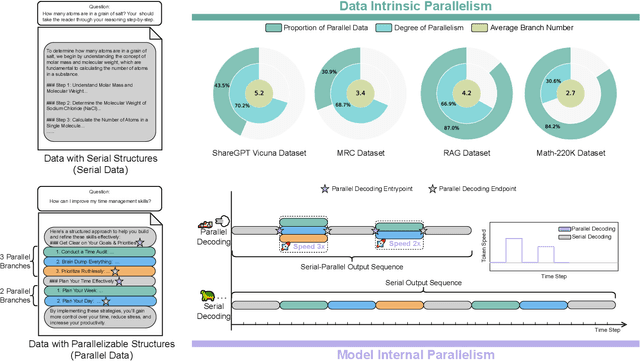
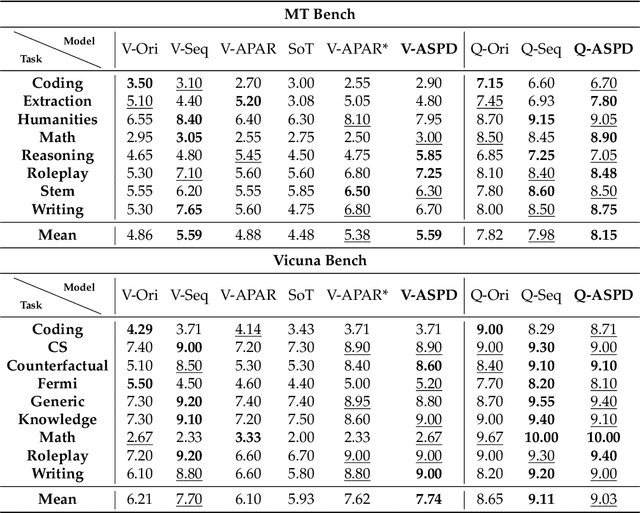
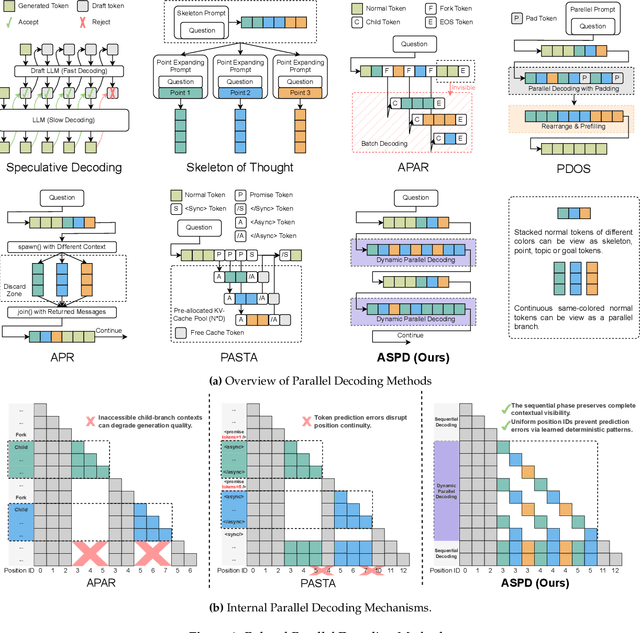
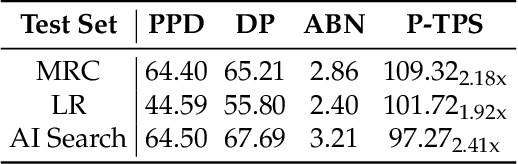
The increasing scale and complexity of large language models (LLMs) pose significant inference latency challenges, primarily due to their autoregressive decoding paradigm characterized by the sequential nature of next-token prediction. By re-examining the outputs of autoregressive models, we observed that some segments exhibit parallelizable structures, which we term intrinsic parallelism. Decoding each parallelizable branch simultaneously (i.e. parallel decoding) can significantly improve the overall inference speed of LLMs. In this paper, we propose an Adaptive Serial-Parallel Decoding (ASPD), which addresses two core challenges: automated construction of parallelizable data and efficient parallel decoding mechanism. More specifically, we introduce a non-invasive pipeline that automatically extracts and validates parallelizable structures from the responses of autoregressive models. To empower efficient adaptive serial-parallel decoding, we implement a Hybrid Decoding Engine which enables seamless transitions between serial and parallel decoding modes while maintaining a reusable KV cache, maximizing computational efficiency. Extensive evaluations across General Tasks, Retrieval-Augmented Generation, Mathematical Reasoning, demonstrate that ASPD achieves unprecedented performance in both effectiveness and efficiency. Notably, on Vicuna Bench, our method achieves up to 3.19x speedup (1.85x on average) while maintaining response quality within 1% difference compared to autoregressive models, realizing significant acceleration without compromising generation quality. Our framework sets a groundbreaking benchmark for efficient LLM parallel inference, paving the way for its deployment in latency-sensitive applications such as AI-powered customer service bots and answer retrieval engines.
MetaFBP: Learning to Learn High-Order Predictor for Personalized Facial Beauty Prediction
Nov 23, 2023



Predicting individual aesthetic preferences holds significant practical applications and academic implications for human society. However, existing studies mainly focus on learning and predicting the commonality of facial attractiveness, with little attention given to Personalized Facial Beauty Prediction (PFBP). PFBP aims to develop a machine that can adapt to individual aesthetic preferences with only a few images rated by each user. In this paper, we formulate this task from a meta-learning perspective that each user corresponds to a meta-task. To address such PFBP task, we draw inspiration from the human aesthetic mechanism that visual aesthetics in society follows a Gaussian distribution, which motivates us to disentangle user preferences into a commonality and an individuality part. To this end, we propose a novel MetaFBP framework, in which we devise a universal feature extractor to capture the aesthetic commonality and then optimize to adapt the aesthetic individuality by shifting the decision boundary of the predictor via a meta-learning mechanism. Unlike conventional meta-learning methods that may struggle with slow adaptation or overfitting to tiny support sets, we propose a novel approach that optimizes a high-order predictor for fast adaptation. In order to validate the performance of the proposed method, we build several PFBP benchmarks by using existing facial beauty prediction datasets rated by numerous users. Extensive experiments on these benchmarks demonstrate the effectiveness of the proposed MetaFBP method.
Periodically Exchange Teacher-Student for Source-Free Object Detection
Nov 23, 2023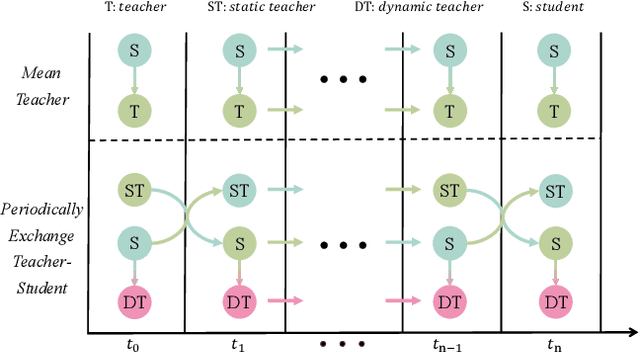
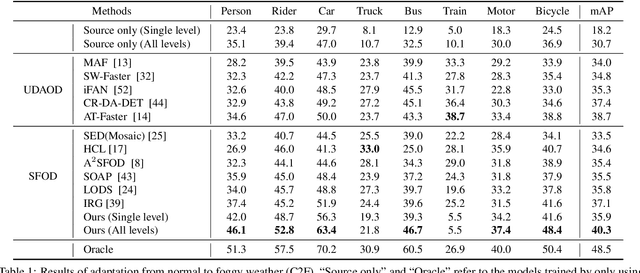
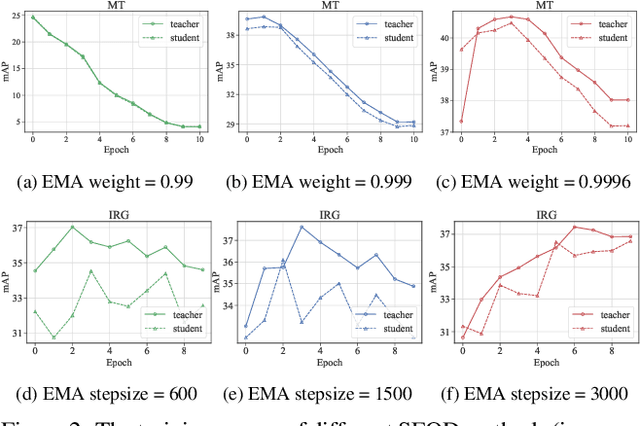
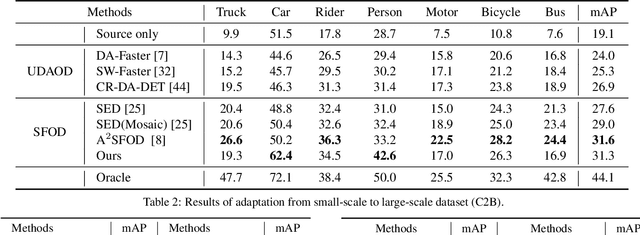
Source-free object detection (SFOD) aims to adapt the source detector to unlabeled target domain data in the absence of source domain data. Most SFOD methods follow the same self-training paradigm using mean-teacher (MT) framework where the student model is guided by only one single teacher model. However, such paradigm can easily fall into a training instability problem that when the teacher model collapses uncontrollably due to the domain shift, the student model also suffers drastic performance degradation. To address this issue, we propose the Periodically Exchange Teacher-Student (PETS) method, a simple yet novel approach that introduces a multiple-teacher framework consisting of a static teacher, a dynamic teacher, and a student model. During the training phase, we periodically exchange the weights between the static teacher and the student model. Then, we update the dynamic teacher using the moving average of the student model that has already been exchanged by the static teacher. In this way, the dynamic teacher can integrate knowledge from past periods, effectively reducing error accumulation and enabling a more stable training process within the MT-based framework. Further, we develop a consensus mechanism to merge the predictions of two teacher models to provide higher-quality pseudo labels for student model. Extensive experiments on multiple SFOD benchmarks show that the proposed method achieves state-of-the-art performance compared with other related methods, demonstrating the effectiveness and superiority of our method on SFOD task.
Parameter Exchange for Robust Dynamic Domain Generalization
Nov 23, 2023Agnostic domain shift is the main reason of model degradation on the unknown target domains, which brings an urgent need to develop Domain Generalization (DG). Recent advances at DG use dynamic networks to achieve training-free adaptation on the unknown target domains, termed Dynamic Domain Generalization (DDG), which compensates for the lack of self-adaptability in static models with fixed weights. The parameters of dynamic networks can be decoupled into a static and a dynamic component, which are designed to learn domain-invariant and domain-specific features, respectively. Based on the existing arts, in this work, we try to push the limits of DDG by disentangling the static and dynamic components more thoroughly from an optimization perspective. Our main consideration is that we can enable the static component to learn domain-invariant features more comprehensively by augmenting the domain-specific information. As a result, the more comprehensive domain-invariant features learned by the static component can then enforce the dynamic component to focus more on learning adaptive domain-specific features. To this end, we propose a simple yet effective Parameter Exchange (PE) method to perturb the combination between the static and dynamic components. We optimize the model using the gradients from both the perturbed and non-perturbed feed-forward jointly to implicitly achieve the aforementioned disentanglement. In this way, the two components can be optimized in a mutually-beneficial manner, which can resist the agnostic domain shifts and improve the self-adaptability on the unknown target domain. Extensive experiments show that PE can be easily plugged into existing dynamic networks to improve their generalization ability without bells and whistles.
Dynamic Domain Generalization
May 27, 2022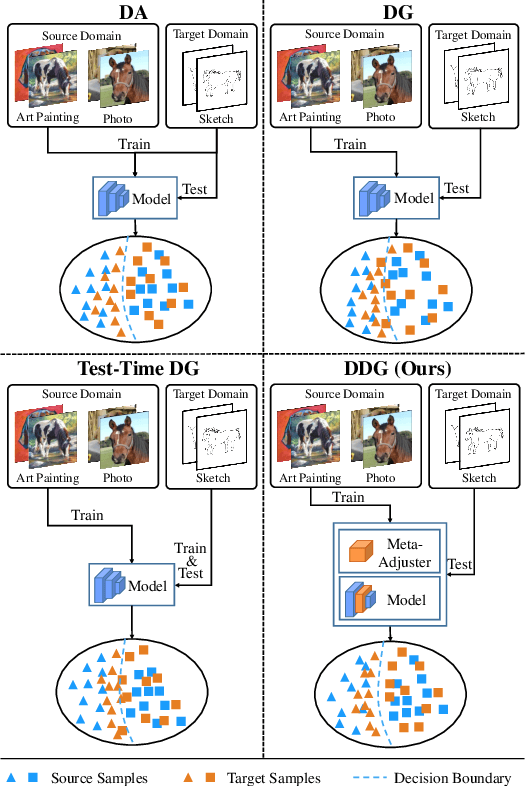
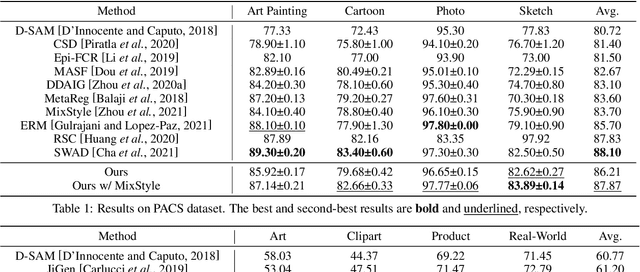

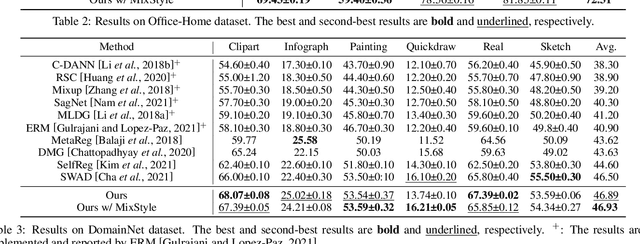
Domain generalization (DG) is a fundamental yet very challenging research topic in machine learning. The existing arts mainly focus on learning domain-invariant features with limited source domains in a static model. Unfortunately, there is a lack of training-free mechanism to adjust the model when generalized to the agnostic target domains. To tackle this problem, we develop a brand-new DG variant, namely Dynamic Domain Generalization (DDG), in which the model learns to twist the network parameters to adapt the data from different domains. Specifically, we leverage a meta-adjuster to twist the network parameters based on the static model with respect to different data from different domains. In this way, the static model is optimized to learn domain-shared features, while the meta-adjuster is designed to learn domain-specific features. To enable this process, DomainMix is exploited to simulate data from diverse domains during teaching the meta-adjuster to adapt to the upcoming agnostic target domains. This learning mechanism urges the model to generalize to different agnostic target domains via adjusting the model without training. Extensive experiments demonstrate the effectiveness of our proposed method. Code is available at: https://github.com/MetaVisionLab/DDG