 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGMark: A Diffusion Watermark for Knowledge Graphs
May 29, 2025Knowledge graphs (KGs) are ubiquitous in numerous real-world applications, and watermarking facilitates protecting intellectual property and preventing potential harm from AI-generated content. Existing watermarking methods mainly focus on static plain text or image data, while they can hardly be applied to dynamic graphs due to spatial and temporal variations of structured data. This motivates us to propose KGMARK, the first graph watermarking framework that aims to generate robust, detectable, and transparent diffusion fingerprints for dynamic KG data. Specifically, we propose a novel clustering-based alignment method to adapt the watermark to spatial variations. Meanwhile, we present a redundant embedding strategy to harden the diffusion watermark against various attacks, facilitating the robustness of the watermark to the temporal variations. Additionally, we introduce a novel learnable mask matrix to improve the transparency of diffusion fingerprints. By doing so, our KGMARK properly tackles the variation challenges of structured data. Experiments on various public benchmarks show the effectiveness of our proposed KGMARK.
MetaFBP: Learning to Learn High-Order Predictor for Personalized Facial Beauty Prediction
Nov 23, 2023



Predicting individual aesthetic preferences holds significant practical applications and academic implications for human society. However, existing studies mainly focus on learning and predicting the commonality of facial attractiveness, with little attention given to Personalized Facial Beauty Prediction (PFBP). PFBP aims to develop a machine that can adapt to individual aesthetic preferences with only a few images rated by each user. In this paper, we formulate this task from a meta-learning perspective that each user corresponds to a meta-task. To address such PFBP task, we draw inspiration from the human aesthetic mechanism that visual aesthetics in society follows a Gaussian distribution, which motivates us to disentangle user preferences into a commonality and an individuality part. To this end, we propose a novel MetaFBP framework, in which we devise a universal feature extractor to capture the aesthetic commonality and then optimize to adapt the aesthetic individuality by shifting the decision boundary of the predictor via a meta-learning mechanism. Unlike conventional meta-learning methods that may struggle with slow adaptation or overfitting to tiny support sets, we propose a novel approach that optimizes a high-order predictor for fast adaptation. In order to validate the performance of the proposed method, we build several PFBP benchmarks by using existing facial beauty prediction datasets rated by numerous users. Extensive experiments on these benchmarks demonstrate the effectiveness of the proposed MetaFBP method.
Parameter Exchange for Robust Dynamic Domain Generalization
Nov 23, 2023Agnostic domain shift is the main reason of model degradation on the unknown target domains, which brings an urgent need to develop Domain Generalization (DG). Recent advances at DG use dynamic networks to achieve training-free adaptation on the unknown target domains, termed Dynamic Domain Generalization (DDG), which compensates for the lack of self-adaptability in static models with fixed weights. The parameters of dynamic networks can be decoupled into a static and a dynamic component, which are designed to learn domain-invariant and domain-specific features, respectively. Based on the existing arts, in this work, we try to push the limits of DDG by disentangling the static and dynamic components more thoroughly from an optimization perspective. Our main consideration is that we can enable the static component to learn domain-invariant features more comprehensively by augmenting the domain-specific information. As a result, the more comprehensive domain-invariant features learned by the static component can then enforce the dynamic component to focus more on learning adaptive domain-specific features. To this end, we propose a simple yet effective Parameter Exchange (PE) method to perturb the combination between the static and dynamic components. We optimize the model using the gradients from both the perturbed and non-perturbed feed-forward jointly to implicitly achieve the aforementioned disentanglement. In this way, the two components can be optimized in a mutually-beneficial manner, which can resist the agnostic domain shifts and improve the self-adaptability on the unknown target domain. Extensive experiments show that PE can be easily plugged into existing dynamic networks to improve their generalization ability without bells and whistles.
Memory-Constrained Semantic Segmentation for Ultra-High Resolution UAV Imagery
Oct 07, 2023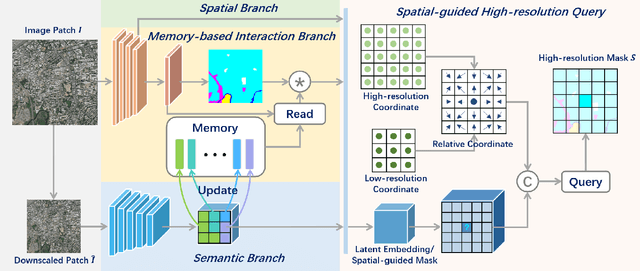
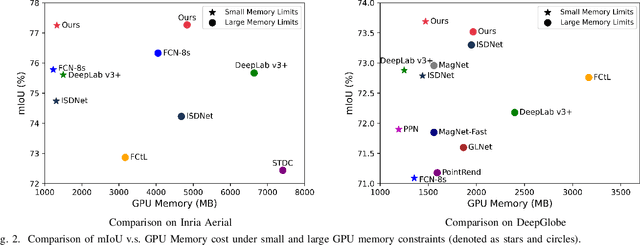
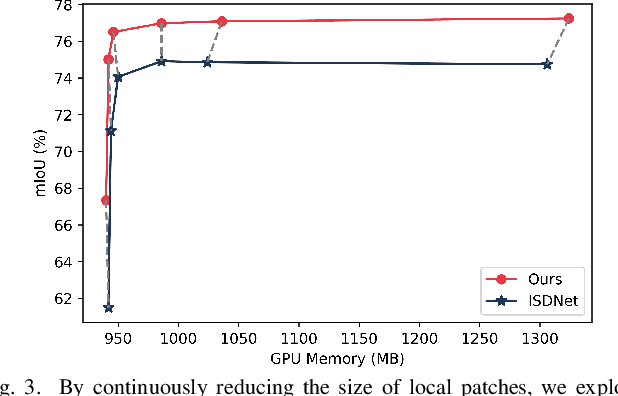

Amidst the swift advancements in photography and sensor technologies, high-definition cameras have become commonplace in the deployment of Unmanned Aerial Vehicles (UAVs) for diverse operational purposes. Within the domain of UAV imagery analysis, the segmentation of ultra-high resolution images emerges as a substantial and intricate challenge, especially when grappling with the constraints imposed by GPU memory-restricted computational devices. This paper delves into the intricate problem of achieving efficient and effective segmentation of ultra-high resolution UAV imagery, while operating under stringent GPU memory limitation. The strategy of existing approaches is to downscale the images to achieve computationally efficient segmentation. However, this strategy tends to overlook smaller, thinner, and curvilinear regions. To address this problem, we propose a GPU memory-efficient and effective framework for local inference without accessing the context beyond local patches. In particular, we introduce a novel spatial-guided high-resolution query module, which predicts pixel-wise segmentation results with high quality only by querying nearest latent embeddings with the guidance of high-resolution information. Additionally, we present an efficient memory-based interaction scheme to correct potential semantic bias of the underlying high-resolution information by associating cross-image contextual semantics. For evaluation of our approach, we perform comprehensive experiments over public benchmarks and achieve superior performance under both conditions of small and large GPU memory usage limitations. We will release the model and codes in the future.
Monocular BEV Perception of Road Scenes via Front-to-Top View Projection
Nov 15, 2022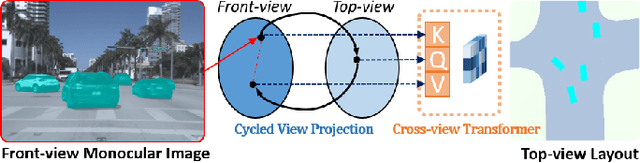



HD map reconstruction is crucial for autonomous driving. LiDAR-based methods are limited due to expensive sensors and time-consuming computation. Camera-based methods usually need to perform road segmentation and view transformation separately, which often causes distortion and missing content. To push the limits of the technology, we present a novel framework that reconstructs a local map formed by road layout and vehicle occupancy in the bird's-eye view given a front-view monocular image only. We propose a front-to-top view projection (FTVP) module, which takes the constraint of cycle consistency between views into account and makes full use of their correlation to strengthen the view transformation and scene understanding. In addition, we also apply multi-scale FTVP modules to propagate the rich spatial information of low-level features to mitigate spatial deviation of the predicted object location. Experiments on public benchmarks show that our method achieves the state-of-the-art performance in the tasks of road layout estimation, vehicle occupancy estimation, and multi-class semantic estimation. For multi-class semantic estimation, in particular, our model outperforms all competitors by a large margin. Furthermore, our model runs at 25 FPS on a single GPU, which is efficient and applicable for real-time panorama HD map reconstruction.
Dynamic Domain Generalization
May 27, 2022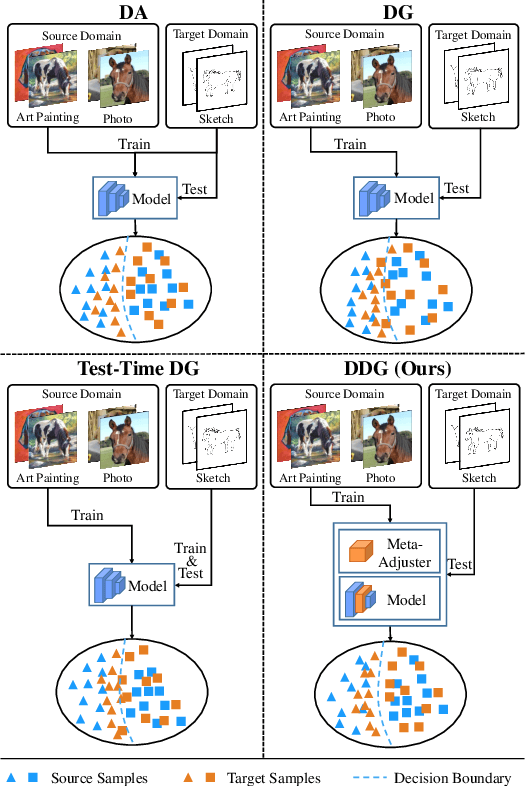
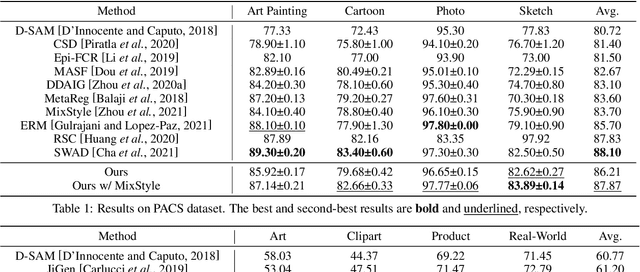

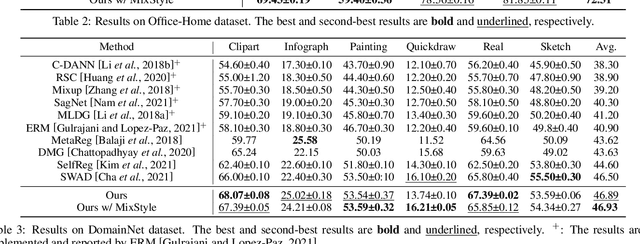
Domain generalization (DG) is a fundamental yet very challenging research topic in machine learning. The existing arts mainly focus on learning domain-invariant features with limited source domains in a static model. Unfortunately, there is a lack of training-free mechanism to adjust the model when generalized to the agnostic target domains. To tackle this problem, we develop a brand-new DG variant, namely Dynamic Domain Generalization (DDG), in which the model learns to twist the network parameters to adapt the data from different domains. Specifically, we leverage a meta-adjuster to twist the network parameters based on the static model with respect to different data from different domains. In this way, the static model is optimized to learn domain-shared features, while the meta-adjuster is designed to learn domain-specific features. To enable this process, DomainMix is exploited to simulate data from diverse domains during teaching the meta-adjuster to adapt to the upcoming agnostic target domains. This learning mechanism urges the model to generalize to different agnostic target domains via adjusting the model without training. Extensive experiments demonstrate the effectiveness of our proposed method. Code is available at: https://github.com/MetaVisionLab/DDG
Semi-Supervised Domain Generalization in Real World:New Benchmark and Strong Baseline
Nov 19, 2021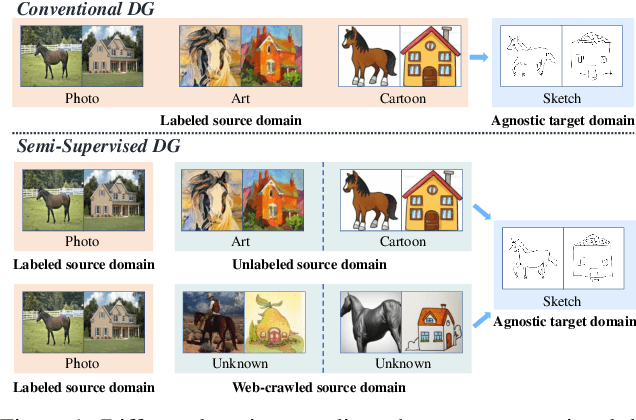
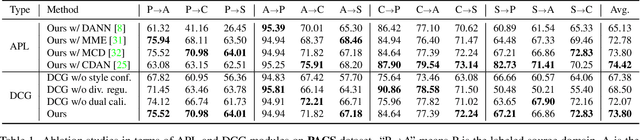
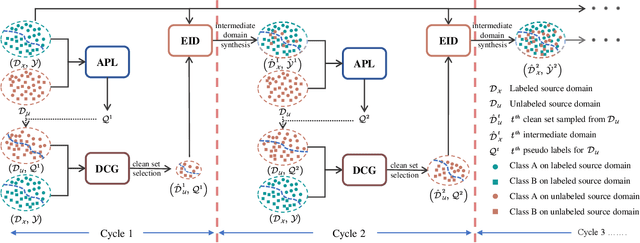
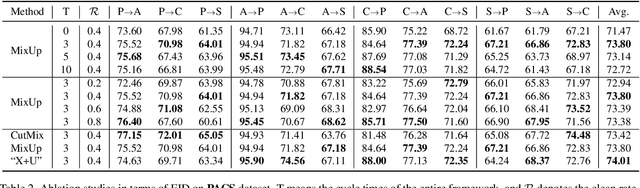
Conventional domain generalization aims to learn domain invariant representation from multiple domains, which requires accurate annotations. In realistic application scenarios, however, it is too cumbersome or even infeasible to collect and annotate the large mass of data. Yet, web data provides a free lunch to access a huge amount of unlabeled data with rich style information that can be harnessed to augment domain generalization ability. In this paper, we introduce a novel task, termed as semi-supervised domain generalization, to study how to interact the labeled and unlabeled domains, and establish two benchmarks including a web-crawled dataset, which poses a novel yet realistic challenge to push the limits of existing technologies. To tackle this task, a straightforward solution is to propagate the class information from the labeled to the unlabeled domains via pseudo labeling in conjunction with domain confusion training. Considering narrowing domain gap can improve the quality of pseudo labels and further advance domain invariant feature learning for generalization, we propose a cycle learning framework to encourage the positive feedback between label propagation and domain generalization, in favor of an evolving intermediate domain bridging the labeled and unlabeled domains in a curriculum learning manner. Experiments are conducted to validate the effectiveness of our framework. It is worth highlighting that web-crawled data benefits domain generalization as demonstrated in our results. Our code will be available later.
From Contexts to Locality: Ultra-high Resolution Image Segmentation via Locality-aware Contextual Correlation
Sep 06, 2021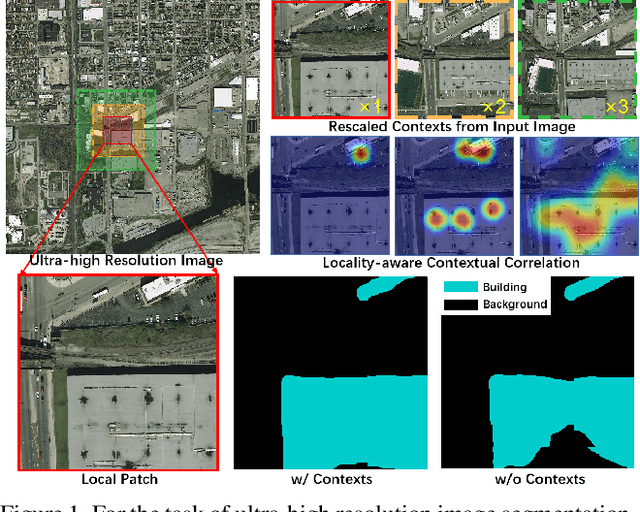
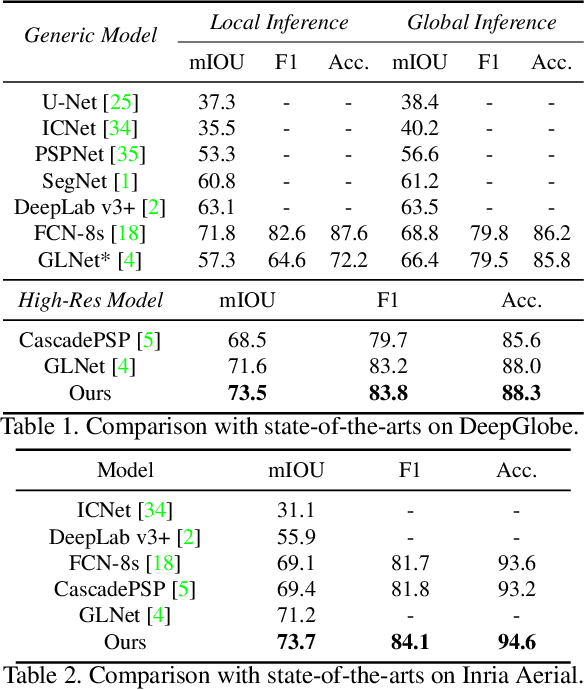
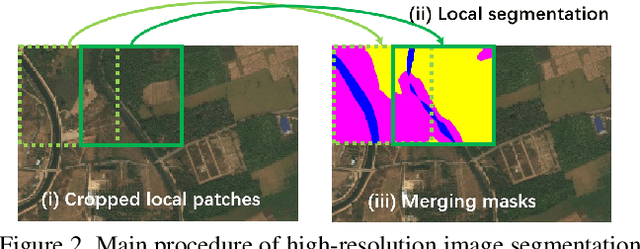
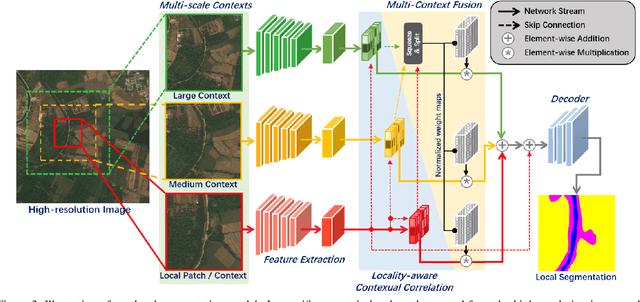
Ultra-high resolution image segmentation has raised increasing interests in recent years due to its realistic applications. In this paper, we innovate the widely used high-resolution image segmentation pipeline, in which an ultra-high resolution image is partitioned into regular patches for local segmentation and then the local results are merged into a high-resolution semantic mask. In particular, we introduce a novel locality-aware contextual correlation based segmentation model to process local patches, where the relevance between local patch and its various contexts are jointly and complementarily utilized to handle the semantic regions with large variations. Additionally, we present a contextual semantics refinement network that associates the local segmentation result with its contextual semantics, and thus is endowed with the ability of reducing boundary artifacts and refining mask contours during the generation of final high-resolution mask. Furthermore, in comprehensive experiments, we demonstrate that our model outperforms other state-of-the-art methods in public benchmarks. Our released codes are available at https://github.com/liqiokkk/FCtL.
A Homotopy Coordinate Descent Optimization Method for $l_0$-Norm Regularized Least Square Problem
Nov 13, 2020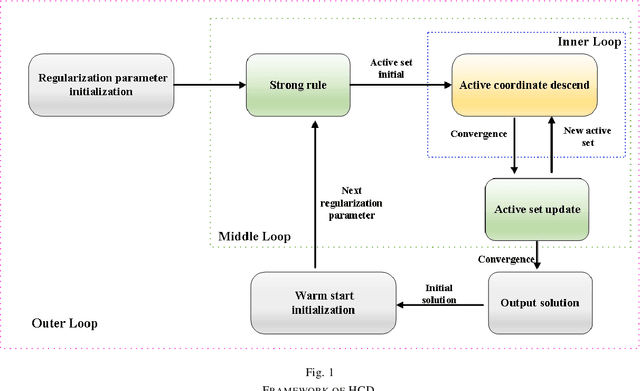
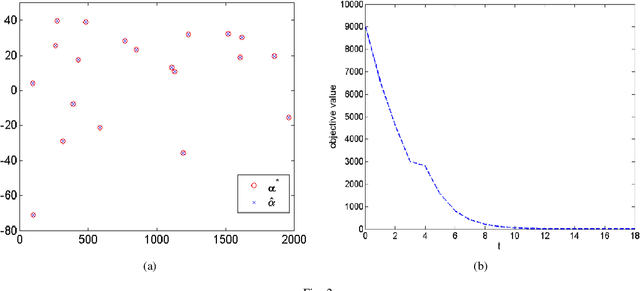
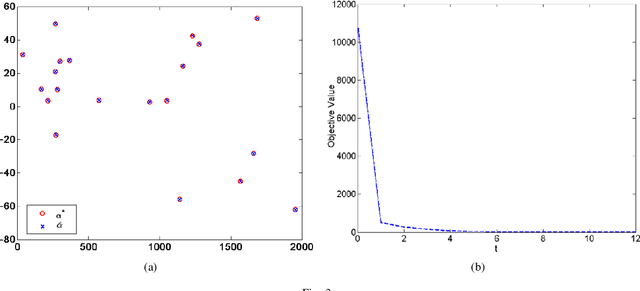
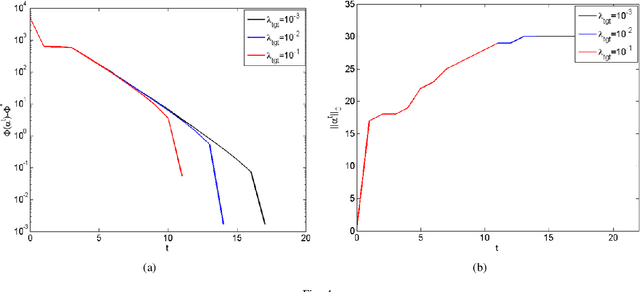
This paper proposes a homotopy coordinate descent (HCD) method to solve the $l_0$-norm regularized least square ($l_0$-LS) problem for compressed sensing, which combine the homotopy technique with a variant of coordinate descent method. Differs from the classical coordinate descent algorithms, HCD provides three strategies to speed up the convergence: warm start initialization, active set updating, and strong rule for active set initialization. The active set is pre-selected using a strong rule, then the coordinates of the active set are updated while those of inactive set are unchanged. The homotopy strategy provides a set of warm start initial solutions for a sequence of decreasing values of the regularization factor, which ensures all iterations along the homotopy solution path are sparse. Computational experiments on simulate signals and natural signals demonstrate effectiveness of the proposed algorithm, in accurately and efficiently reconstructing sparse solutions of the $l_0$-LS problem, whether the observation is noisy or not.
Nonnegative Spectral Analysis with Adaptive Graph and $L_{2,0}$-Norm Regularization for Unsupervised Feature Selection
Oct 30, 2020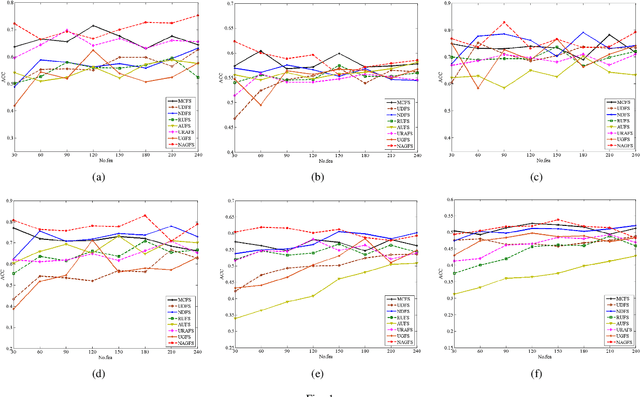
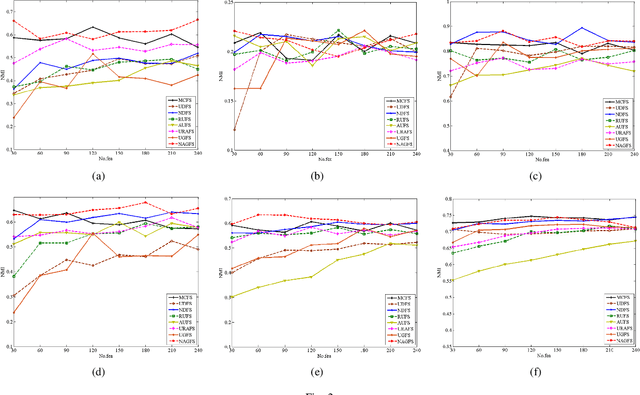
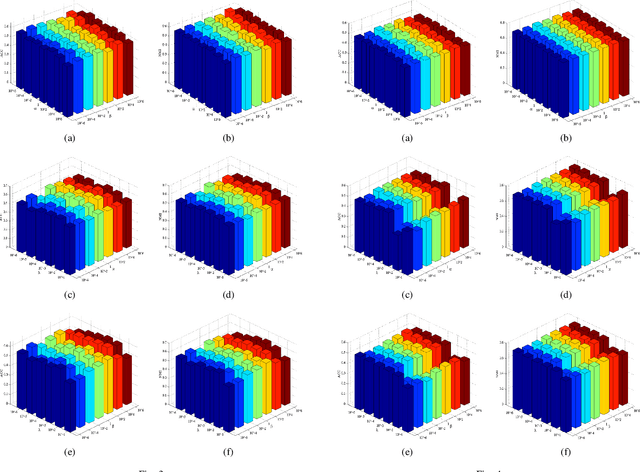

Feature selection is used to reduce feature dimension while maintain model's performance, which has been an important data preprocessing in many fields. Since obtaining annotated data is laborious or even infeasible in many cases, unsupervised feature selection is more practical in reality. Although a lots of methods have been proposed, these methods select features independently, thus it is no guarantee that the group of selected features is optimal. What's more, the number of selected features must be tuned carefully to get a satisfactory result. In this paper, we propose a novel unsupervised feature selection method which incorporate spectral analysis with a $l_{2,0}$-norm regularized term. After optimization, a group of optimal features will be selected, and the number of selected features will be determined automatically. What's more, a nonnegative constraint with respect to the class indicators is imposed to learn more accurate cluster labels, and a graph regularized term is added to learn the similarity matrix adaptively. An efficient and simple iterative algorithm is designed to optimize the proposed problem. Experiments on six different benchmark data sets validate the effectiveness of the proposed approach.